NSC
1.0.0
神经情绪分类旨在用神经模型将情感分类为文档,这一直是情感分类的最新方法。在这个项目中,我们提供了NSC,NSC+LA和NSC+UPA [Chen等,2016]的实现,其中通过对不同语义级别的关注来考虑用户和产品信息。
对文档级别情感分类的评估结果。 ACC。(准确性)和RMSE是评估指标。 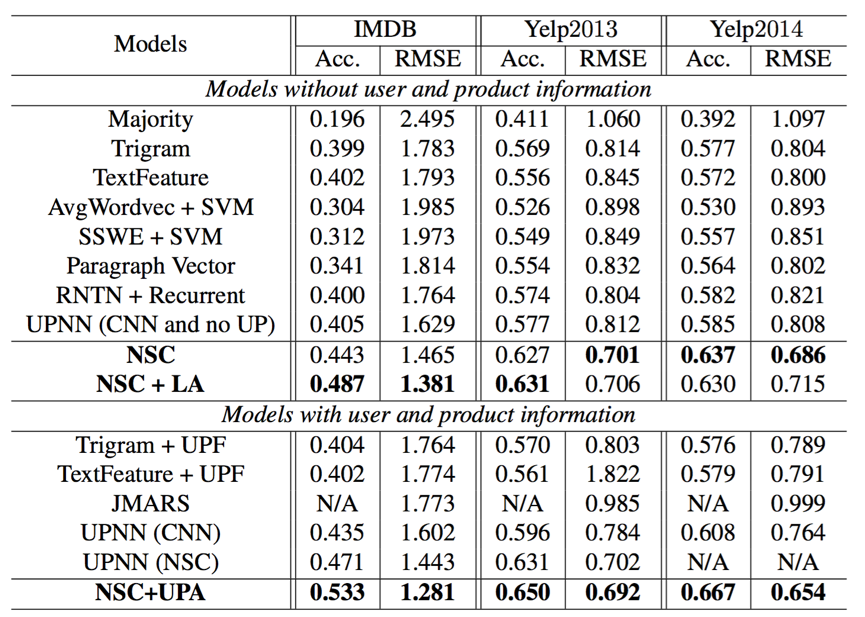
在上表中,[Tang等人,2015年]报道了包括多数,Trigram,TextFeature,UPF,AVGWORDVEC,AVGWORDVEC,SSWE,RNTN + RNN,段落向量,JMARS和UPNN在内的基线模型。
我们在[下载]中提供了用于情感分类的IMDB,YELP13和YELP14数据集。该数据集应被解压缩并放入文件夹NSC/,NSC+LA/或NSC+UPA/。
我们准备原始数据,以使其满足代码的输入格式。原始数据集由论文[Tang等,2015]发布。 [下载]
在每个数据集(IMDB,yelp13,yelp14)上分别学习预训练的单词向量。
每个域中的数据集包含七个文件,使用以下格式:
训练有素的模型可以在此链接上找到。
各种模型的源代码都放在文件夹NSC/SRC,NSC+LA/SRC,NSC+UPA/SRC中。
对于培训,您需要在每个模型的文件夹中键入以下命令:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
其中数据集是相应的数据集文件夹,类是相应域的数量。
例如,我们在对IMDB文档进行分类时使用以下命令:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
培训模型文件将保存在每个模型的文件夹模型/ BestModel中。
对于测试,您需要在每个模型的文件夹src/中键入以下命令:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
其中数据集是相应的数据集文件夹,类是相应域的数量。
例如,我们在对IMDB文档进行分类时使用以下命令:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
报告准确性和RMSE的测试结果将显示在屏幕上。
如果使用代码,请引用以下论文:
[Chen等,2016] Huimin Chen,Maosong Sun,Cunchao Tu,Yankai Lin和Zhiyuan Liu。神经情绪分类与用户和产品关注。在EMNLP的会议录中。[PDF]
[Chen等,2016] Huimin Chen,Maosong Sun,Cunchao Tu,Yankai Lin和Zhiyuan Liu。神经情绪分类与用户和产品关注。在EMNLP的会议录中。[PDF]
[Tang等,2015] Duyu Tang,Bing Qin,Ting Liu。学习用户和产品的语义表示,以进行文档级别的情感分类。在EMNLP会议录中。


