NSC
1.0.0
Классификация нейронных настроений направлена на классификацию настроений в документе с нейронными моделями, который был самыми современными методами классификации настроений. В этом проекте мы предоставляем наши реализации NSC, NSC+LA и NSC+UPA [Chen et al., 2016], в которых информация о пользователе и продукте рассматривается через внимание на разных семантических уровнях.
Результаты оценки по классификации настроений на уровне документов. Acc. (Точность) и RMSE являются показателями оценки. 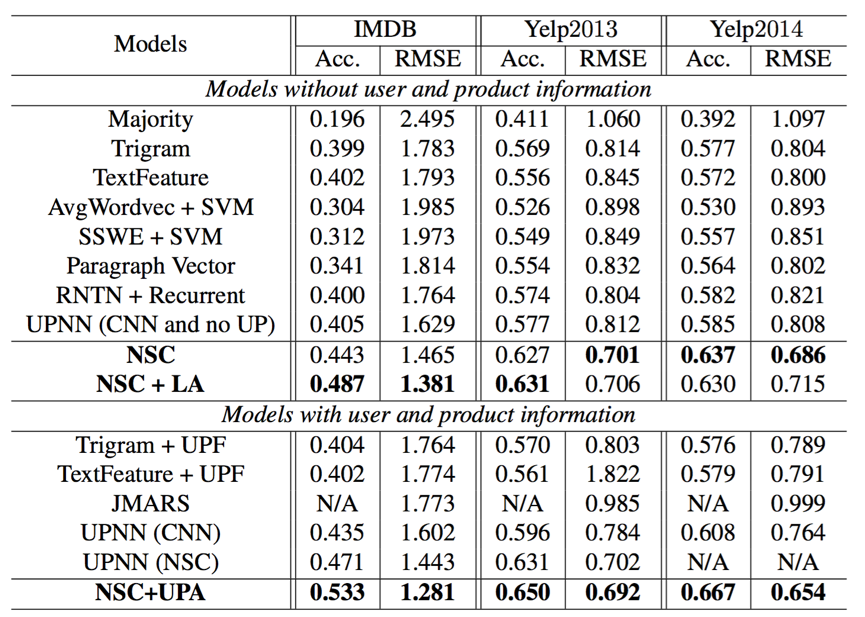
В вышеупомянутой таблице базовые модели, включая большинство, триграмму, текстовую обработку, UPF, AVGWORDVEC, SSWE, RNTN + RNN, Paragraph Vector, JMARS и UPNN, представлены в [Tang et al., 2015].
Мы предоставляем наборы данных IMDB, YELP13 и YELP14, которые мы использовали для классификации настроений в [загрузке]. Набор данных должен быть декомпрессирован и помещать в папку NSC/, NSC+LA/или NSC+UPA/.
Мы предварительно предпринимаем исходные данные, чтобы они удовлетворили входной формат наших кодов. Оригинальные наборы данных выпускаются в статье [Tang et al., 2015]. [Скачать]
Предварительно обученные векторы Word изучаются в каждом наборе данных (IMDB, Yelp13, Yelp14) отдельно.
Набор данных в каждом домене содержит семь файлов, используя следующий формат:
Обученную модель можно найти по этой ссылке.
Исходные коды различных моделей помещаются в папки NSC/SRC, NSC+LA/SRC, NSC+UPA/SRC.
Для обучения вам нужно ввести следующую команду в папке SRC/ каждой модели:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
Где набор данных является соответствующей папкой набора данных, класс - это количество соответствующего домена.
Например, мы используем следующую команду при классе документа IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
Файл обучающей модели будет сохранен в модели папки/ BestModel/ каждой модели.
Для тестирования вам нужно ввести следующую команду в папке SRC/ каждой модели:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
Где набор данных является соответствующей папкой набора данных, класс - это количество соответствующего домена.
Например, мы используем следующую команду при классе документа IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
Результат тестирования, который сообщает, что точность и RMSE будут показаны на экране.
Если вы используете код, указать следующую статью:
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin и Zhiyuan Liu. Классификация нейронных настроений с вниманием пользователя и продукта. В материалах EMNLP. [PDF]
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin и Zhiyuan Liu. Классификация нейронных настроений с вниманием пользователя и продукта. В материалах EMNLP. [PDF]
[Tang et al., 2015] Duyu Tang, Bing Qin, Ting Liu. Изучение семантических представлений пользователей и продуктов для классификации настроений на уровень документов. В материалах EMNLP.


