NSC
1.0.0
신경 정서 분류는 문서에서 감정을 신경 모델로 분류하는 것을 목표로하며, 이는 감정 분류를위한 최첨단 방법이었다. 이 프로젝트에서 우리는 NSC, NSC+LA 및 NSC+UPA의 구현을 제공합니다 [Chen et al., 2016]에서는 다른 의미 수준에 대한주의를 통해 사용자 및 제품 정보가 고려됩니다.
문서 수준의 감정 분류에 대한 평가 결과. Acc. (정확도) 및 RMSE는 평가 지표입니다. 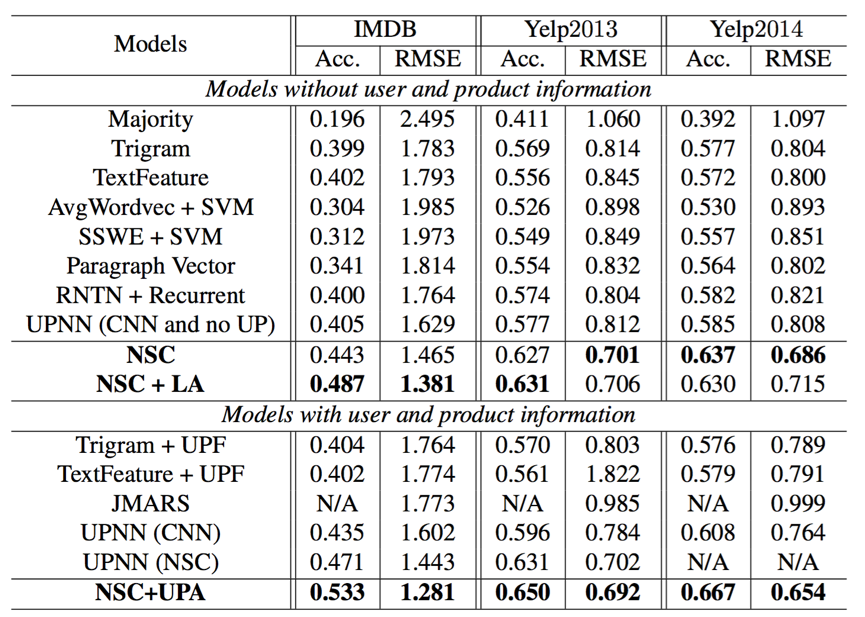
위의 표에서, 대다수, Trigram, TextFeature, UPF, AVGWORDVEC, SSWE, RNTN + RNN, 단락 벡터, JMAR 및 UPNN을 포함한 기준 모델은 [Tang et al., 2015]에보고됩니다.
우리는 [다운로드]에서 감정 분류에 사용한 IMDB, YELP13 및 YELP14 데이터 세트를 제공합니다. 데이터 세트는 압축을 압축하고 NSC/, NSC+LA/또는 NSC+UPA/폴더에 넣어야합니다.
코드의 입력 형식을 만족시키기 위해 원래 데이터를 전공합니다. 원래 데이터 세트는 논문에 의해 발표됩니다 [Tang et al., 2015]. [다운로드]
미리 훈련 된 워드 벡터는 각 데이터 세트 (IMDB, YELP13, YELP14)에서 별도로 학습됩니다.
각 도메인의 데이터 세트에는 다음 형식을 사용하여 7 개의 파일이 포함됩니다.
훈련 된 모델은이 링크에서 찾을 수 있습니다.
다양한 모델의 소스 코드는 폴더 NSC/SRC, NSC+LA/SRC, NSC+UPA/SRC에 넣습니다.
교육을 위해서는 각 모델의 폴더 SRC/에 다음 명령을 입력해야합니다.
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
여기서 데이터 세트 는 해당 데이터 세트 폴더이고 클래스는 해당 도메인의 수입니다.
예를 들어 IMDB 문서를 클래스 핑 할 때 다음 명령을 사용합니다.
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
교육 모델 파일은 각 모델의 폴더 모델/ BestModel/에 저장됩니다.
테스트하려면 각 모델의 폴더 SRC/에 다음 명령을 입력해야합니다.
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
여기서 데이터 세트 는 해당 데이터 세트 폴더이고 클래스는 해당 도메인의 수입니다.
예를 들어 IMDB 문서를 클래스 핑 할 때 다음 명령을 사용합니다.
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
정확도와 RMSE를보고하는 테스트 결과는 화면에 표시됩니다.
코드를 사용하는 경우 다음 논문을 인용하십시오.
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao TU, Yankai Lin 및 Zhiyuan Liu. 사용자 및 제품주의를 가진 신경 정서 분류. EMNLP의 절차에서 [PDF]
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao TU, Yankai Lin 및 Zhiyuan Liu. 사용자 및 제품주의를 가진 신경 정서 분류. EMNLP의 절차에서 [PDF]
[Tang et al., 2015] Duyu Tang, Bing Qin, Ting Liu. 문서 수준 감정 분류를위한 사용자 및 제품의 의미 론적 표현 학습. EMNLP의 절차에서.


