NSC
1.0.0
Klasifikasi sentimen saraf bertujuan untuk mengklasifikasikan sentimen dalam dokumen dengan model saraf, yang telah menjadi metode canggih untuk klasifikasi sentimen. Dalam proyek ini, kami menyediakan implementasi NSC, NSC+LA dan NSC+UPA [Chen et al., 2016] di mana informasi pengguna dan produk dipertimbangkan melalui perhatian pada tingkat semantik yang berbeda.
Hasil evaluasi pada klasifikasi sentimen tingkat dokumen. ACC. (Akurasi) dan RMSE adalah metrik evaluasi. 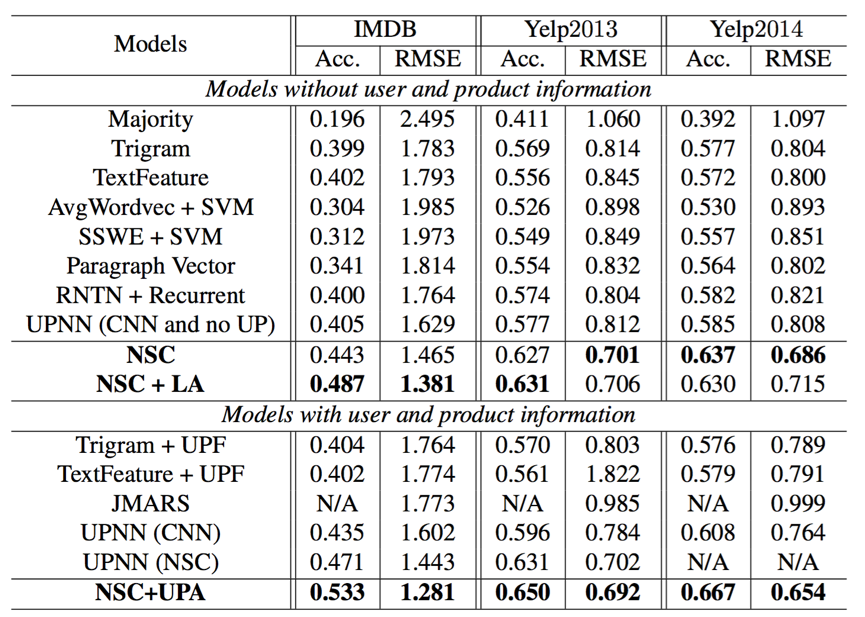
Dalam tabel di atas, model awal termasuk mayoritas, trigram, teks, UPF, AVGWORDVEC, SSWE, RNTN + RNN, paragraf vektor, JMAR dan UPNN dilaporkan dalam [Tang et al., 2015].
Kami menyediakan dataset IMDB, YELP13 dan YELP14 yang kami gunakan untuk klasifikasi sentimen di [unduh]. Dataset harus didekompresi dan dimasukkan ke dalam folder NSC/, NSC+LA/atau NSC+UPA/.
Kami prepocess data asli untuk membuatnya memenuhi format input kode kami. Dataset asli dirilis oleh kertas [Tang et al., 2015]. [Unduh]
Vektor kata pra-terlatih dipelajari pada setiap dataset (IMDB, YELP13, YELP14) secara terpisah.
Dataset di setiap domain berisi tujuh file, menggunakan format berikut:
Model terlatih dapat ditemukan di tautan ini.
Kode sumber berbagai model dimasukkan ke dalam folder NSC/SRC, NSC+LA/SRC, NSC+UPA/SRC.
Untuk pelatihan, Anda perlu mengetik perintah berikut di folder SRC/ dari setiap model:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
Di mana dataset adalah folder dataset yang sesuai, kelas adalah jumlah domain yang sesuai.
Misalnya, kami menggunakan perintah berikut saat menggolongkan dokumen IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
File model pelatihan akan disimpan dalam model folder/ BestModel/ dari masing -masing model.
Untuk pengujian, Anda perlu mengetik perintah berikut di folder SRC/ dari setiap model:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
Di mana dataset adalah folder dataset yang sesuai, kelas adalah jumlah domain yang sesuai.
Misalnya, kami menggunakan perintah berikut saat menggolongkan dokumen IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
Hasil pengujian yang melaporkan keakuratan dan RMSE akan ditampilkan di layar.
Jika Anda menggunakan kode, silakan mengutip makalah berikut:
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin dan Zhiyuan Liu. Klasifikasi sentimen saraf dengan perhatian pengguna dan produk. Dalam Prosiding EMNLP. [PDF]
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin dan Zhiyuan Liu. Klasifikasi sentimen saraf dengan perhatian pengguna dan produk. Dalam Prosiding EMNLP. [PDF]
[Tang et al., 2015] Duyu Tang, Bing Qin, Ting Liu. Mempelajari representasi semantik pengguna dan produk untuk klasifikasi sentimen tingkat dokumen. Dalam Prosiding EMNLP.


