NSC
1.0.0
La clasificación de sentimientos neuronales tiene como objetivo clasificar el sentimiento en un documento con modelos neuronales, que han sido los métodos de vanguardia para la clasificación de sentimientos. En este proyecto, proporcionamos nuestras implementaciones de NSC, NSC+LA y NSC+UPA [Chen et al., 2016] en las que se considera la información del usuario y el producto a través de atenciones en diferentes niveles semánticos.
Resultados de la evaluación en la clasificación de sentimientos a nivel de documento. Acc. (Precisión) y RMSE son las métricas de evaluación. 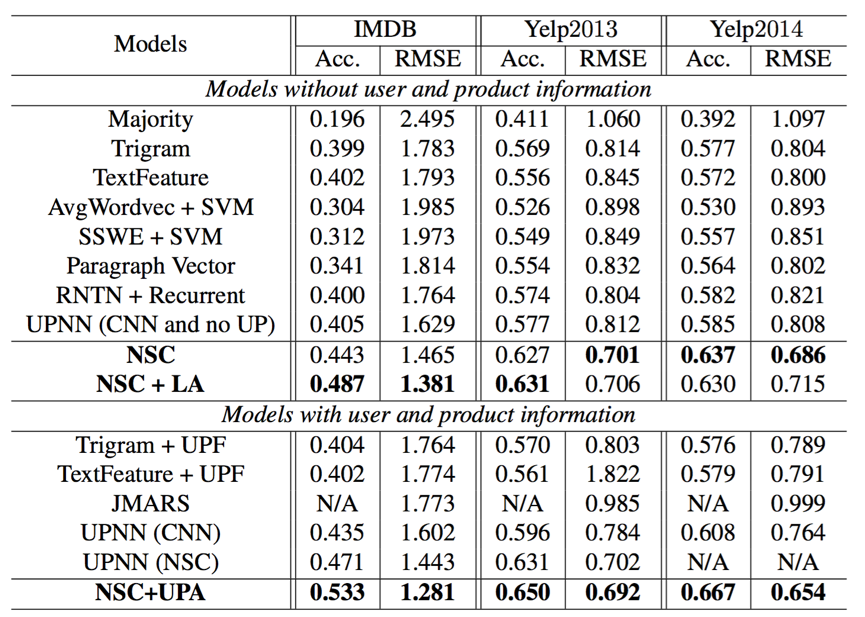
En la tabla anterior, los modelos de línea de base que incluyen mayoría, Trigram, TextFeature, UPF, AvgwordVec, SSWE, RNTN + RNN, Pargraph Vector, JMARS y UPNN se informan en [Tang et al., 2015].
Proporcionamos conjuntos de datos IMDB, YELP13 y YELP14 que utilizamos para la clasificación de sentimientos en [Descargar]. El conjunto de datos debe descomprimirse y colocar en la carpeta NSC/, NSC+LA/o NSC+UPA/.
Preparamos los datos originales para que satisfaga el formato de entrada de nuestros códigos. Los conjuntos de datos originales son lanzados por el documento [Tang et al., 2015]. [Descargar]
Los vectores de palabras previamente capacitados se aprenden en cada conjunto de datos (IMDB, Yelp13, Yelp14) por separado.
El conjunto de datos en cada dominio contiene siete archivos, utilizando el siguiente formato:
El modelo entrenado se puede encontrar en este enlace.
Los códigos fuente de varios modelos se colocan en las carpetas NSC/SRC, NSC+LA/SRC, NSC+UPA/SRC.
Para el entrenamiento, debe escribir el siguiente comando en la carpeta SRC/ de cada modelo:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
Donde el conjunto de datos es la carpeta del conjunto de datos correspondiente, la clase es el número de dominio correspondiente.
Por ejemplo, usamos el siguiente comando al clasificar el documento IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
El archivo del modelo de entrenamiento se guardará en el modelo de carpeta/ bestmodel/ de cada modelo.
Para las pruebas, debe escribir el siguiente comando en la carpeta src/ de cada modelo:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
Donde el conjunto de datos es la carpeta del conjunto de datos correspondiente, la clase es el número de dominio correspondiente.
Por ejemplo, usamos el siguiente comando al clasificar el documento IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
El resultado de la prueba que informa la precisión y el RMSE se mostrará en la pantalla.
Si usa el código, cite el siguiente documento:
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin y Zhiyuan Liu. Clasificación de sentimientos neuronales con atención del usuario y del producto. En Actas de EMNLP. [PDF]
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin y Zhiyuan Liu. Clasificación de sentimientos neuronales con atención del usuario y del producto. En Actas de EMNLP. [PDF]
[Tang et al., 2015] Duyu Tang, Bing Qin, Ting Liu. Aprender representaciones semánticas de usuarios y productos para la clasificación de sentimientos a nivel de documentos. En Actas de EMNLP.


