NSC
1.0.0
神経感情分類は、センチメント分類の最先端の方法であるニューラルモデルを含む文書の感情を分類することを目的としています。このプロジェクトでは、NSC、NSC+LA、およびNSC+UPA [Chen et al。、2016]の実装を提供します。ここでは、ユーザーと製品情報が異なるセマンティックレベルを介して検討されます。
ドキュメントレベルのセンチメント分類に関する評価結果。 ACC。(精度)とRMSEは評価メトリックです。 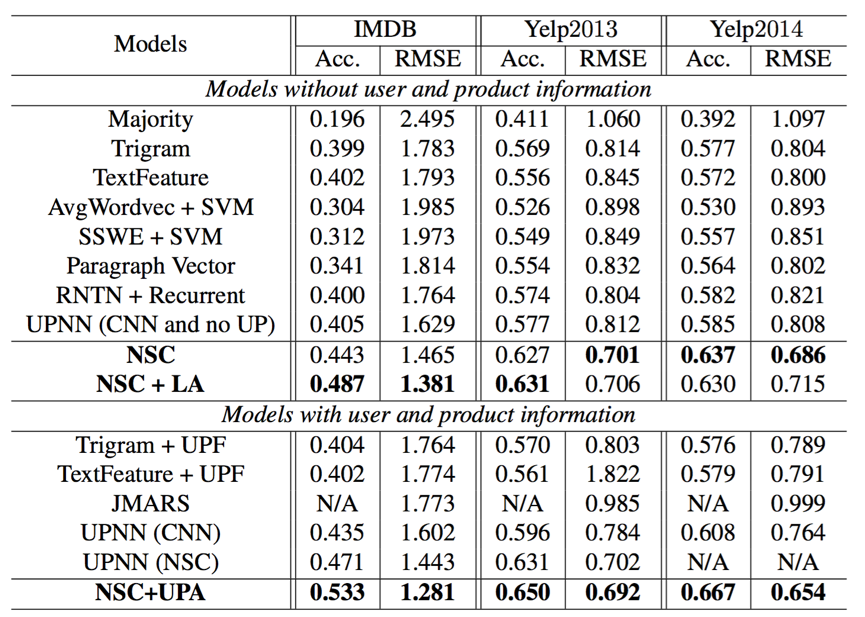
上記の表では、多数派、Trigram、TextFeature、UPF、AvgWordVec、SSWE、RNTN + RNN、段落ベクター、JMARSおよびUPNNを含むベースラインモデルが[Tang et al。、2015]に報告されています。
[ダウンロード]の感情分類に使用したIMDB、YELP13、およびYELP14データセットを提供します。データセットを解凍し、フォルダーNSC/、NSC+LA/またはNSC+UPA/に入れてください。
元のデータを事前にアクセスして、コードの入力形式を満たすようにします。元のデータセットは、論文によってリリースされています[Tang et al。、2015]。 [ダウンロード]
事前に訓練された単語ベクトルは、各データセット(IMDB、YELP13、YELP14)で個別に学習されます。
各ドメインのデータセットには、次の形式を使用して7つのファイルが含まれています。
訓練されたモデルは、このリンクで見つけることができます。
さまざまなモデルのソースコードは、フォルダーNSC/SRC、NSC+LA/SRC、NSC+UPA/SRCに入れられます。
トレーニングには、各モデルのフォルダーSRC/に次のコマンドを入力する必要があります。
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
データセットが対応するデータセットフォルダーである場合、クラスは対応するドメインの数です。
たとえば、IMDBドキュメントをクラスしているときに次のコマンドを使用します。
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
トレーニングモデルファイルは、各モデルのフォルダーモデル/ BestModel/に保存されます。
テストには、各モデルのフォルダーSRC/に次のコマンドを入力する必要があります。
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
データセットが対応するデータセットフォルダーである場合、クラスは対応するドメインの数です。
たとえば、IMDBドキュメントをクラスしているときに次のコマンドを使用します。
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
精度とRMSEを報告するテスト結果は、画面に表示されます。
コードを使用する場合は、次の論文を引用してください。
[Chen et al。、2016] Huimin Chen、Maosong Sun、Cunchao Tu、Yankai Lin、Zhiyuan Liu。ユーザーと製品の注意による神経感情分類。 emnlpの議事録[PDF]
[Chen et al。、2016] Huimin Chen、Maosong Sun、Cunchao Tu、Yankai Lin、Zhiyuan Liu。ユーザーと製品の注意による神経感情分類。 emnlpの議事録[PDF]
[Tang et al。、2015] Duyu Tang、Bing Qin、Ting Liu。ドキュメントレベルのセンチメント分類のためのユーザーと製品のセマンティック表現を学習します。 EMNLPの議事録。


