NSC
1.0.0
La classification des sentiments neuronaux vise à classer le sentiment dans un document avec des modèles neuronaux, qui a été les méthodes de pointe de la classification du sentiment. Dans ce projet, nous fournissons nos implémentations de NSC, NSC + LA et NSC + UPA [Chen et al., 2016] dans lesquelles les informations sur les utilisateurs et les produits sont considérées via des attentions sur différents niveaux sémantiques.
Résultats de l'évaluation sur la classification des sentiments au niveau du document. Acc. (Précision) et RMSE sont les mesures d'évaluation. 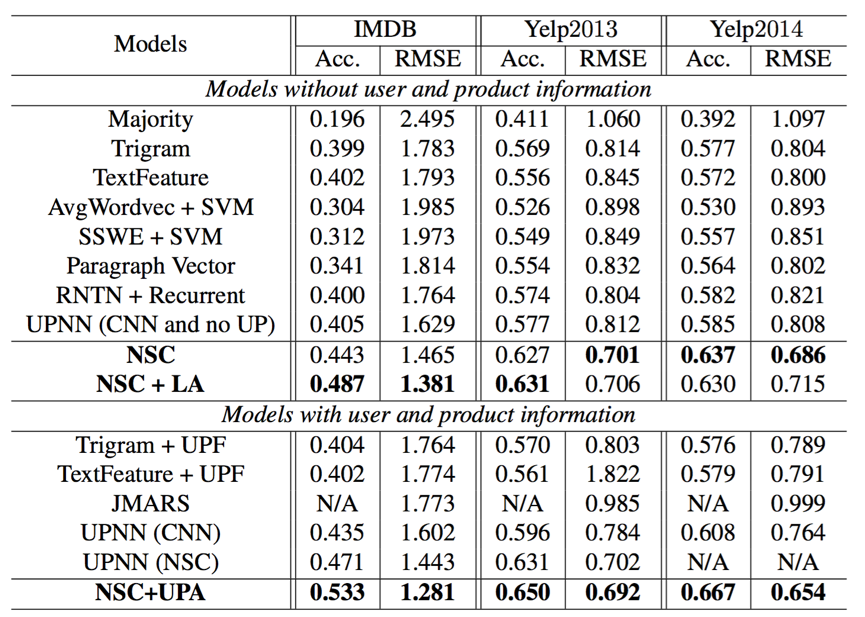
Dans le tableau ci-dessus, des modèles de référence, notamment la majorité, le trigram, TextFeature, UPF, AVGWORDVEC, SSWE, RNTN + RNN, Vector, Paragraph Vector, JMARS et UPNN sont signalés dans [Tang et al., 2015].
Nous fournissons des ensembles de données IMDB, YELP13 et YELP14 que nous avons utilisés pour la classification des sentiments dans [Download]. L'ensemble de données doit être décompressé et placé dans le dossier nsc /, nsc + la / ou nsc + upa /.
Nous préparons les données d'origine pour la faire satisfaire le format d'entrée de nos codes. Les ensembles de données originaux sont publiés par l'article [Tang et al., 2015]. [Télécharger]
Les vecteurs de mots pré-formés sont appris sur chaque ensemble de données (IMDB, YELP13, YELP14) séparément.
L'ensemble de données de chaque domaine contient sept fichiers, en utilisant le format suivant:
Le modèle formé peut être trouvé sur ce lien.
Les codes source de divers modèles sont placés dans les dossiers NSC / SRC, NSC + LA / SRC, NSC + UPA / SRC.
Pour la formation, vous devez taper la commande suivante dans le dossier SRC / de chaque modèle:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py $dataset $class
Lorsque l'ensemble de données est le dossier de jeu de données correspondant, la classe est le nombre de domaines correspondants.
Par exemple, nous utilisons la commande suivante lors de la classe du document IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python train.py IMDB 10
Le fichier de modèle de formation sera enregistré dans le modèle de dossier / BestModel / de chaque modèle.
Pour les tests, vous devez taper la commande suivante dans le dossier Src / de chaque modèle:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py $dataset $class
Lorsque l'ensemble de données est le dossier de jeu de données correspondant, la classe est le nombre de domaines correspondants.
Par exemple, nous utilisons la commande suivante lors de la classe du document IMDB:
THEANO_FLAGS="floatX=float32,device=gpu" python test.py IMDB 10
Le résultat des tests qui rapporte la précision et le RMSE seront affichés dans l'écran.
Si vous utilisez le code, veuillez citer l'article suivant:
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin et Zhiyuan Liu. Classification des sentiments neuronaux avec l'attention des utilisateurs et des produits. Dans les actes d'EMNLP. [PDF]
[Chen et al., 2016] Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin et Zhiyuan Liu. Classification des sentiments neuronaux avec l'attention des utilisateurs et des produits. Dans les actes d'EMNLP. [PDF]
[Tang et al., 2015] Duyu Tang, Bing Qin, Ting Liu. Apprendre des représentations sémantiques des utilisateurs et des produits pour la classification des sentiments au niveau des documents. Dans les actes de l'EMNLP.


