canopy
0.9.0
笔记
顶篷团队不再维护此存储库。感谢您对该项目的支持和热情!如果您正在寻找具有持续更新和改进的高质量托管RAG解决方案,请查看Pinecone助理。
Canopy是建立在Pinecone矢量数据库顶部的开源检索增强生成(RAG)框架和上下文引擎。 Canopy使您可以快速轻松地使用RAG实验并构建应用程序。使用一些简单命令开始与文档或文本数据聊天。
Canopy竭尽全力来构建抹布应用:从块和嵌入文本数据到聊天历史管理,查询优化,上下文检索(包括及时的工程)和增强生成。
Canopy提供了可配置的内置服务器,因此您可以轻松地将由抹布的聊天应用程序部署到现有的聊天UI或接口。或者,您可以使用Canopy库构建自己的自定义RAG应用程序。
顶篷让您可以使用基于CLI的聊天工具来评估RAG工作流程。借助Canopy CLI中的一个简单命令,您可以与文本数据进行交互式聊天,并并排比较抹布与非抹布工作流程。
查看我们的博客文章以了解更多信息,或在此处查看快速教程。
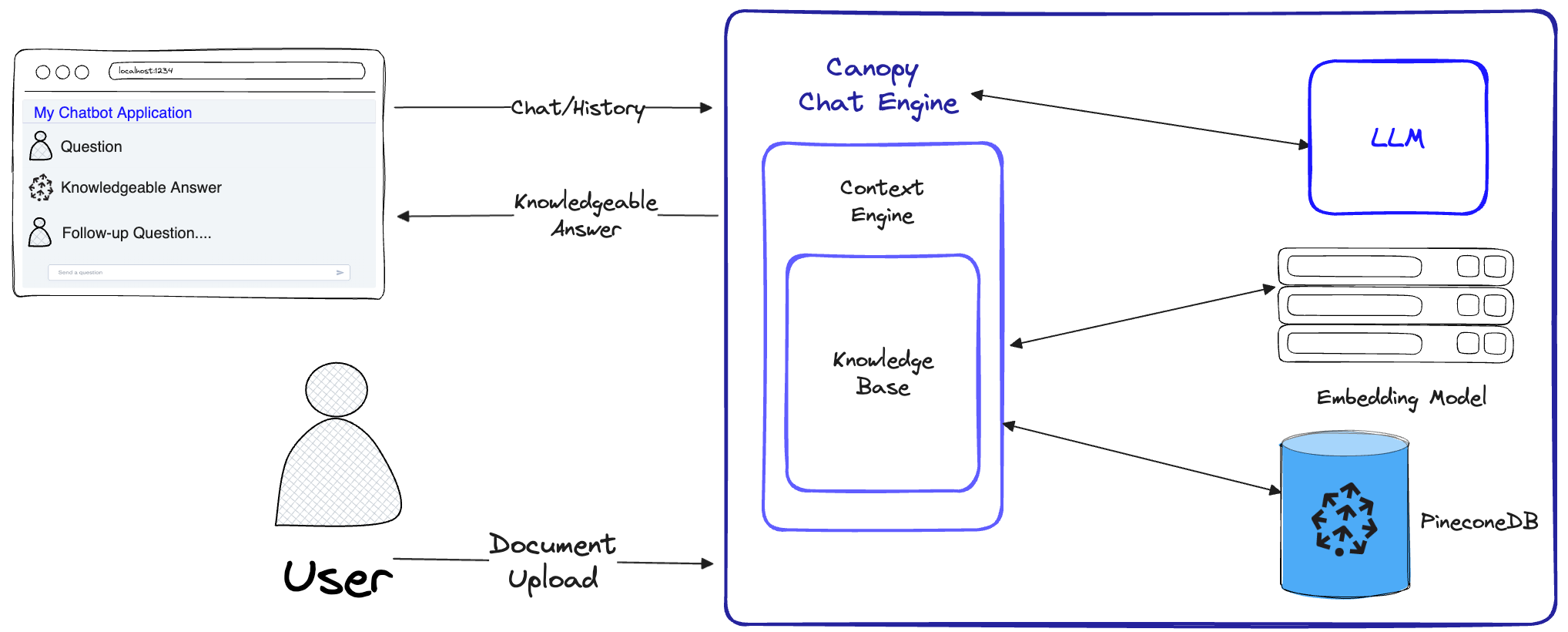
Canopy实现了完整的RAG工作流程,以防止幻觉并使用自己的文本数据增强您的LLM。
Canopy有两个流:知识基础创建和聊天。在知识库创建流中,用户上传文档并将其转换为Pinecone矢量数据库中存储的有意义的表示形式。在聊天流中,对传入的查询和聊天历史记录进行了优化以检索最相关的文档,查询知识库,并为LLM生成有意义的上下文以回答。
ChatEngine为ContextEngine提出了相关查询,然后使用LLM来生成知识渊博的响应。ContextEngine利用基础KnowledgeBase来检索最相关的文档,然后制定一个连贯的文本上下文,以用作LLM的提示。有关核心库使用的更多信息,请参见库文档中
Canopy Server-这是一个网络服务,它包装Canopy Core库并将其公开为REST API。该服务器建在Fastapi,Uvicorn和Gunicorn的顶部,可以轻松地在生产中部署。该服务器还带有内置的Swagger UI,可轻松测试和文档。启动服务器后,您可以在http://host:port/docs (默认: http://localhost:8000/docs )上访问Swagger UI。
Canopy CLI-一种内置开发工具,允许用户快速设置自己的Canopy Server并测试其配置。
只需三个CLI命令,您就可以创建一个新的Canopy Server,将文档上传到它,然后直接使用终端中的内置聊天应用程序与聊天机器人进行交互。内置的聊天机器人还可以比较注入抹布的响应与本机LLM聊天机器人。
python3 -m venv canopy-env
source canopy-env/bin/activate有关虚拟环境的更多信息可以在此处找到
pip install canopy-sdk| 姓名 | 描述 |
|---|---|
grpc | 通过使用Pinecone客户端的GRPC版本来解锁一些性能改进 |
torch | 启用句子转换器提供的嵌入 |
transformers | 如果您使用的是EnyScale LLMS,建议使用LLamaTokenizer令牌仪,该kenizer需要变压器作为依赖项 |
cohere | 使用cohere reranker或/and/and/and cohere llm |
qdrant | 将QDrant作为替代知识库 |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| 姓名 | 描述 | 如何获得它? |
|---|---|---|
PINECONE_API_KEY | Pinecone的API键。用于对Pinecone服务进行身份验证以创建索引并插入,删除和搜索数据 | 在控制台中注册或登录您的Pinecone帐户。您可以从仪表板的侧边栏中的“ API键”部分访问API键 |
OPENAI_API_KEY | Openai的API密钥。用于验证OpenAI的服务以嵌入和聊天API | 您可以在此处找到OpenAI API密钥。您可能需要登录或注册到OpenAI服务 |
INDEX_NAME | Pinecone索引冠层的名称将与 | 只要遵循Pinecone的限制,您就可以选择任何名称 |
CANOPY_CONFIG_FILE | Canopy Server将使用配置YAML文件的路径。 | 可选 - 如果不提供,将使用默认配置 |
这些可选的环境变量用于对其他支持的嵌入和LLM的支持服务进行身份验证。如果您配置了Canopy以使用这些提供商中的任何一个 - 您需要设置相关的环境变量。
| 姓名 | 描述 | 如何获得它? |
|---|---|---|
ANYSCALE_API_KEY | api键的Anyscale。用于对开源LLMS的任何规模端点进行身份验证 | 您可以在此处注册Anyscale端点并在此处找到API密钥 |
CO_API_KEY | cohere的API键。用于验证以嵌入服务的服务 | 您可以在此处找到有关注册到Cohere的更多信息 |
JINA_API_KEY | Jina AI的API密钥。用于验证Jinaai的服务以嵌入和聊天API | 您可以在此处找到OpenAI API密钥。您可能需要登录或注册到OpenAI服务 |
AZURE_OPENAI_ENDOINT | 您部署的Azure OpenAI端点的URL。 | 您可以在_keys和endpoints`下的Azure Openai门户网站中找到它 |
AZURE_OPENAI_API_KEY | 用于Azure OpenAI型号的API键。 | 您可以在_keys和endpoints`下的Azure Openai门户网站中找到它 |
OCTOAI_API_KEY | octoai的API键。用于在Octoai提供的开源LLMS验证 | 您可以注册Octoai并在此处找到您的API密钥 |
canopy输出应与此相似:
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message 在此QuickStart中,我们将向您展示如何使用冠层使用抹布(检索增强生成)构建一个简单的问答系统。
作为一次性设置,Canopy需要创建一个新的Pinecone索引,该索引配置为使用Canopy,只需运行:
canopy new并遵循CLI说明。将要创建的索引将具有前缀canopy--<INDEX_NAME> 。
您只需要为要创建的每个冠层索引完成一次此过程即可。
要了解有关Pinecone索引以及如何管理它们的更多信息,请参阅以下指南:了解索引
您可以使用命令将数据加载到冠层索引中:
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... Canopy支持jsonl , parquet和csv格式的文件。此外,您可以以.txt格式加载明文数据文件。在这种情况下,每个文件将被视为一个文档。文档ID将是文件名,源将是文件的完整路径。
注意:文档字段在抹布流中使用,应符合以下模式:
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]本笔记本显示了如何以这种格式创建数据集,请在上传数据时按照CLI中的说明进行操作。
提示
如果您想将数据分为名称空间,则可以使用--namespace选项或INDEX_NAMESPACE环境变量。
Canopy Server通过REST API公开了Canopy的功能。也就是说,它允许您上传文档,检索给定查询的相关文档以及与您的数据聊天。服务器曝光了A /chat.completion端点,可以轻松地将其与任何聊天应用程序集成在一起。要启动服务器,请运行:
canopy start现在,应该提示您使用以下标准UVICORN消息:
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
就是这样!现在,您可以开始使用支持A /chat.completion端点的任何聊天应用程序的Canopy Server。
顶式启动命令将保持终端占用(建议使用)。如果要在后台运行服务器,则可以使用以下命令
nohup canopy start &
要停止服务器,只需在您启动的终端中按CTRL+C即可。
Canopy的CLI附带一个内置的聊天应用程序,可让您与文本数据进行交互性聊天,并比较抹布与非抹布工作流程,以评估结果
在新的终端窗口中,设置所需的环境变量然后运行:
canopy chat这将在您的终端打开聊天接口。您可以提出问题,注入抹布的聊天机器人将尝试使用您上传的数据来回答它们。
用或不带有抹布的聊天响应,请使用--no-rag标志
注意:此方法仅在目前由OpenAI支持。
canopy chat --no-rag这将打开一个类似的聊天接口窗口,但将同时显示抹布和非抹布响应。
感谢您考虑为Canopy做出贡献!有关更多信息,请参阅我们的贡献指南。
如果您已经有一个使用OpenAI API的应用程序,则可以通过简单地将API端点更改为http://host:port/v1 ,例如使用默认配置来迁移到盖层。
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )如果您想使用特定的索引名称空间进行聊天,则可以将名称空间附加到API端点:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" )Canopy将FastApi用作Web框架,Uvicorn用作ASGI服务器。
要在生产中使用冠层,建议使用Canopy的Docker图像(可在GitHub软件包上获得)来满足您的生产需求。
有关在Google Cloud平台(GCP)上部署冠层的指南,请参阅部署在GCP文档中提供的示例。
另外,您可以将Gunicorn用作生产级WSGI,在此处提供更多详细信息。
设置您所需的PORT和WORKER_COUNT设想变量,并使用以下方式启动服务器
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT 重要的
服务器使用您自己的身份验证凭据与Pinecone和OpenAI等服务进行交互。将服务器部署在公共网络托管提供商上时,建议启用身份验证机制,以便您的服务器仅从身份验证的用户那里获取请求。


