canopy
0.9.0
Nota
El equipo de Canopy ya no mantiene este repositorio. ¡Gracias por su apoyo y entusiasmo por el proyecto! Si está buscando una solución de trapo administrada de alta calidad con actualizaciones y mejoras continuas, consulte el Asistente de Pinecone.
Canopy es un marco de generación aumentada de recuperación de código abierto (RAG) y un motor de contexto construido en la parte superior de la base de datos Vector Pinecone. Canopy le permite experimentar y construir rápida y fácilmente aplicaciones con RAG. Comience a chatear con sus documentos o datos de texto con algunos comandos simples.
Canopy asume el trabajo pesado para construir aplicaciones de trapo: desde fragmentos e integrar sus datos de texto hasta la gestión del historial de chat, la optimización de consultas, la recuperación de contexto (incluida la ingeniería rápida) y la generación aumentada.
Canopy proporciona un servidor incorporado configurable para que pueda implementar sin esfuerzo una aplicación de chat con trapo a su interfaz de usuario o interfaz de chat existente. O puede construir su propia aplicación de trapo personalizada utilizando la biblioteca Canopy.
Canopy le permite evaluar su flujo de trabajo de trapo con una herramienta de chat basada en CLI. Con un comando simple en la CLI con dosel, puede chatear interactivamente con sus datos de texto y comparar los flujos de trabajo RAG frente a RAG de lado a lado.
Echa un vistazo a nuestra publicación de blog para obtener más información o ver un tutorial rápido aquí.
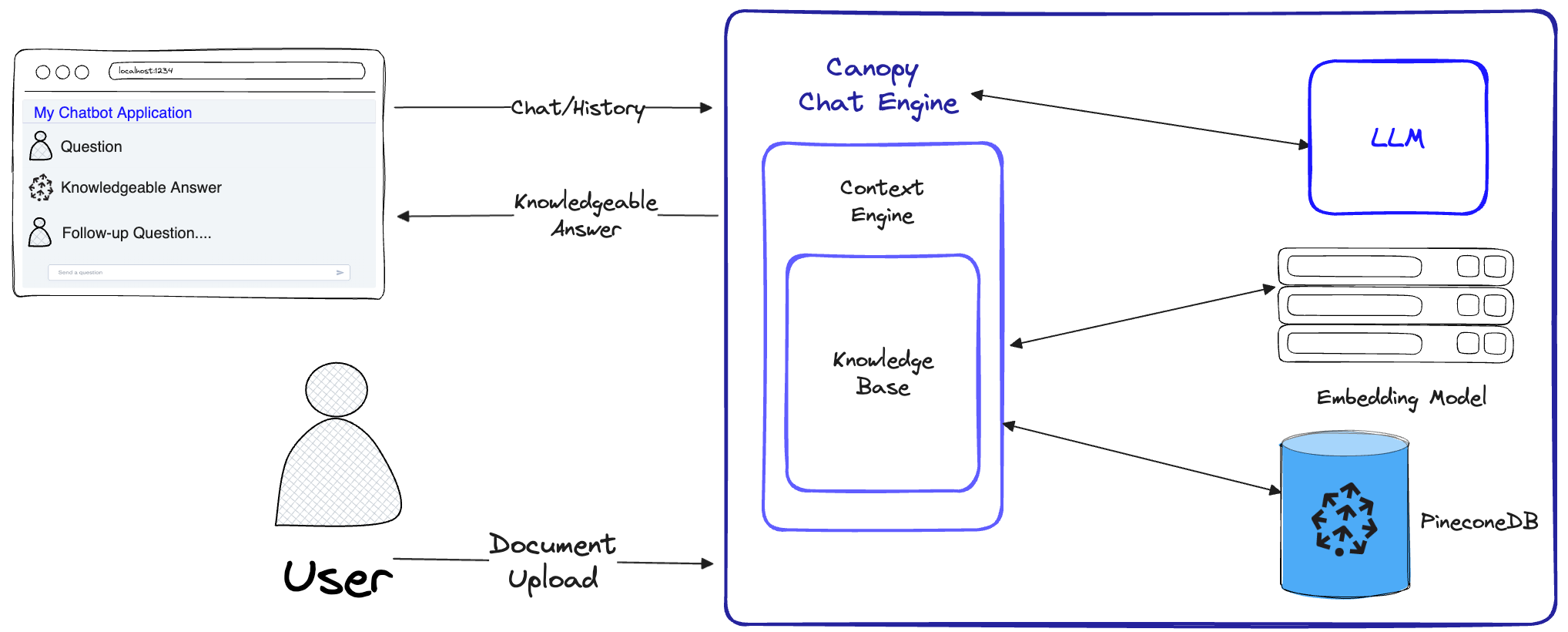
Canopy implementa el flujo de trabajo de trapo completo para evitar alucinaciones y aumentar su LLM con sus propios datos de texto.
Canopy tiene dos flujos: creación y chat de la base de conocimiento. En el flujo de creación de la base de conocimiento, los usuarios cargan sus documentos y los transforman en representaciones significativas almacenadas en la base de datos Vector de Pinecone. En el flujo de chat, las consultas entrantes y el historial de chat están optimizados para recuperar los documentos más relevantes, se consulta la base de conocimiento y se genera un contexto significativo para que el LLM responda.
ChatEngine formula consultas relevantes para el ContextEngine , luego usa el LLM para generar una respuesta bien informada.ContextEngine utiliza la KnowledgeBase subyacente para recuperar los documentos más relevantes, luego formula un contexto textual coherente que se utilizará como un aviso para el LLM.Puede encontrar más información sobre el uso de la biblioteca central en la documentación de la biblioteca
Servidor Canopy : este es un servicio web que envuelve la biblioteca de Canopy Core y la expone como una API REST. El servidor está construido sobre Fastapi, Uvicorn y Gunicorn y se puede implementar fácilmente en producción. El servidor también viene con una interfaz de usuario de Swagger incorporada para fácilmente pruebas y documentación. Después de iniciar el servidor, puede acceder a la interfaz de usuario de Swagger en http://host:port/docs (predeterminado: http://localhost:8000/docs )
Canopy CLI : una herramienta de desarrollo incorporada que permite a los usuarios configurar rápidamente su propio servidor Canopy y probar su configuración.
Con solo tres comandos CLI, puede crear un nuevo servidor de dosel, cargarlo y luego interactuar con el chatbot usando una aplicación de chat incorporada directamente desde el terminal. El chatbot incorporado también permite la comparación de respuestas infundidas con trapo contra un chatbot nativo de LLM.
python3 -m venv canopy-env
source canopy-env/bin/activatePuede encontrar más información sobre entornos virtuales aquí
pip install canopy-sdk| Nombre | Descripción |
|---|---|
grpc | Para desbloquear algunas mejoras de rendimiento trabajando con la versión GRPC del cliente Pinecone |
torch | Para habilitar incrustaciones proporcionadas por transformadores de oraciones |
transformers | Si está utilizando AnyScale LLMS, se recomienda utilizar Tokenizer LLamaTokenizer que requiere transformadores como dependencia |
cohere | Para usar Cohere Reranker o/y cohere LLM |
qdrant | Para usar Qdrant como una base de conocimiento alternativa |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| Nombre | Descripción | ¿Cómo conseguirlo? |
|---|---|---|
PINECONE_API_KEY | La tecla API para Pinecone. Se utiliza para autenticarse en los servicios de Pinecone para crear índices y insertar, eliminar y buscar datos | Regístrese o inicie sesión en su cuenta de Pinecone en la consola. Puede acceder a su tecla API desde la sección "teclas API" en la barra lateral de su tablero |
OPENAI_API_KEY | Clave API para OpenAI. Se solía autenticarse en los servicios de OpenAI para incrustar y chat API | Puede encontrar su llave API OpenAI aquí. Es posible que deba iniciar sesión o registrarse en los servicios de OpenAI |
INDEX_NAME | El nombre del dosel del índice de pinecone será el trabajo subyacente con | Puede elegir cualquier nombre siempre que siga las restricciones de Pinecone |
CANOPY_CONFIG_FILE | La ruta de un archivo YAML de configuración para ser utilizado por el servidor Canopy. | Opcional: si no se proporciona, se utilizaría la configuración predeterminada |
Estas variables de entorno opcional se utilizan para autenticarse con otros servicios compatibles para integridades y LLM. Si configura dosel para usar cualquiera de estos proveedores, necesitaría establecer las variables de entorno relevantes.
| Nombre | Descripción | ¿Cómo conseguirlo? |
|---|---|---|
ANYSCALE_API_KEY | Clave API para AnyScale. Se utiliza para autenticarse en los puntos finales de cualquier escala para LLM de código abierto | Puede registrar los puntos finales de cualquier escala y encontrar su clave API aquí |
CO_API_KEY | Clave API para Cohere. Se utiliza para autenticarse para Cohere Services para integrar | Puede encontrar más información sobre cómo registrarse para cohere aquí |
JINA_API_KEY | Clave API para Jina Ai. Se utiliza para autenticarse en los servicios de Jinaai para incrustar y chat API | Puede encontrar su llave API OpenAI aquí. Es posible que deba iniciar sesión o registrarse en los servicios de OpenAI |
AZURE_OPENAI_ENDOINT | La URL del punto final Azure OpenAI que desplegó. | Puede encontrar esto en el portal de Azure OpenAi en _Keys and Endpoints` |
AZURE_OPENAI_API_KEY | La clave API para usar para sus modelos Azure OpenAI. | Puede encontrar esto en el portal de Azure OpenAi en _Keys and Endpoints` |
OCTOAI_API_KEY | Clave API para Octoai. Se utiliza para autenticarse para LLM de código abierto servidos en Octoai | Puede registrarse en Octoai y encontrar su clave API aquí |
canopyLa salida debe ser similar a esta:
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message En este rápido arranque, le mostraremos cómo usar el dosel para construir un sistema de respuesta de preguntas simple usando RAG (generación de recuperación aumentada).
Como una configuración única, Canopy necesita crear un nuevo índice Pinecone que esté configurado para funcionar con Canopy, simplemente ejecute:
canopy new Y siga las instrucciones de la CLI. El índice que se creará tendrá un canopy--<INDEX_NAME> .
Solo tiene que hacer este proceso una vez para cada índice de dosel que desee crear.
Para obtener más información sobre los índices de Pinecone y cómo administrarlos, consulte la siguiente guía: Comprensión de los índices
Puede cargar datos en su índice de dosel utilizando el comando:
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... Canopy admite archivos en formatos jsonl , parquet y csv . Además, puede cargar archivos de datos de texto sin formato en formato .txt . En este caso, cada archivo será tratado como un solo documento. La ID del documento será el nombre de archivo, y la fuente será la ruta completa del archivo.
Nota : Los campos de documentos se utilizan en el flujo de trapo y deben cumplir con el siguiente esquema:
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]Este cuaderno muestra cómo crea un conjunto de datos en este formato, siga las instrucciones en la CLI cuando cargue sus datos.
Consejo
Si desea separar sus datos en los espacios de nombres, puede usar la opción --namespace o la variable de entorno INDEX_NAMESPACE .
El servidor Canopy expone la funcionalidad de Canopy a través de una API REST. A saber, le permite cargar documentos, recuperar documentos relevantes para una consulta dada y chatear con sus datos. El servidor expone un punto final A /chat.completion que se puede integrar fácilmente con cualquier aplicación de chat. Para iniciar el servidor, ejecute:
canopy startAhora, se le debe solicitar el siguiente mensaje estándar de UVICORN:
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
¡Eso es todo! Ahora puede comenzar a usar el servidor Canopy con cualquier aplicación de chat que admita un punto final A /chat.completion .
El comando Start Canopy mantendrá el terminal ocupado (uso recomendado). Si desea ejecutar el servidor en segundo plano, puede usar el siguiente comando -
nohup canopy start &
Para detener el servidor, simplemente presione CTRL+C en el terminal donde lo inició.
La CLI de Canopy viene con una aplicación de chat incorporada que le permite chatear interactivamente con sus datos de texto y comparar los flujos de trabajo RAG versus no RAG de lado a lado para evaluar los resultados
En una nueva ventana de terminal, establezca las variables de entorno requeridas y luego se ejecuta:
canopy chatEsto abrirá una interfaz de chat en su terminal. Puede hacer preguntas y el chatbot con infusión de trapo intentará responderlas utilizando los datos que cargó.
Para comparar la respuesta de chat con y sin trapo, use la bandera --no-rag
Nota : Este método solo es compatible con OpenAI en este momento.
canopy chat --no-ragEsto abrirá una ventana de interfaz de chat similar, pero mostrará las respuestas RAG y no RAG de lado a lado.
¡Gracias por considerar contribuir a Canopy! Consulte nuestras pautas de contribución para obtener más información.
Si ya tiene una aplicación que usa la API de OpenAI, puede migrarlo a Canopy simplemente cambiando el punto final de la API a http://host:port/v1 , por ejemplo con la configuración predeterminada:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )Si desea utilizar un espacio de nombres de índice específico para chatear, puede agregar el espacio de nombres al punto final de la API:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" ) Canopy está utilizando FastAPI como marco web y UVicorn como el servidor ASGI.
Para usar Canopy en producción, se recomienda utilizar la imagen Docker de Canopy, disponible en paquetes de GitHub, para sus necesidades de producción.
Para obtener orientación sobre la implementación del dosel en la plataforma de Google Cloud (GCP), consulte el ejemplo proporcionado en la implementación de la documentación GCP.
Alternativamente, puede usar Gunicorn como WSGI de grado de producción, más detalles aquí.
Establezca su PORT deseado y las variables de envidación WORKER_COUNT e inicie el servidor con:
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT Importante
El servidor interactúa con servicios como Pinecone y OpenAI utilizando sus propias credenciales de autenticación. Al implementar el servidor en un proveedor de alojamiento web público, se recomienda habilitar un mecanismo de autenticación, para que su servidor solo tome solicitudes de usuarios autenticados.


