canopy
0.9.0
Notiz
Das Canopy -Team unterhält dieses Repository nicht mehr. Vielen Dank für Ihre Unterstützung und Begeisterung für das Projekt! Wenn Sie nach einer qualitativ hochwertig verwalteten Lappenlösung mit fortgesetzten Updates und Verbesserungen suchen, lesen Sie bitte den Pnecone -Assistenten.
Canopy ist ein Rahmenwerk (Open-Source Retrieval Augmented Generation) und eine Kontext-Engine, die oben in der Pinecone-Vektor-Datenbank aufgebaut ist. Mit Canopy können Sie schnell und einfach mit Anwendungen mit RAG experimentieren und sie bauen. Chatten Sie mit Ihren Dokumenten oder Textdaten mit einigen einfachen Befehlen.
Canopy übernimmt das schwere Heben für den Aufbau von Lag -Anwendungen: vom Knacken und Einbettung Ihrer Textdaten in das Chat -Verlaufsmanagement, die Abfrageoptimierung, das Abrufen von Kontext (einschließlich promptem Engineering) und die Augmented -Generation.
Canopy bietet einen konfigurierbaren integrierten Server, sodass Sie mühelos eine rampenbetriebene Chat-Anwendung auf Ihrer vorhandenen Chat-Benutzeroberfläche oder -R-Schnittstelle bereitstellen können. Oder Sie können Ihre eigene, benutzerdefinierte Lag -Anwendung mit der Canopy -Bibliothek erstellen.
Mit Canopy können Sie Ihren Lag -Workflow mit einem CLI -basierten Chat -Tool bewerten. Mit einem einfachen Befehl in der Canopy-CLI können Sie interaktiv mit Ihren Textdaten chatten und sich nebeneinander mit Rag vs. Nicht-RAG-Workflows vergleichen.
Schauen Sie sich unseren Blog -Beitrag an, um mehr zu erfahren, oder sehen Sie hier ein kurzes Tutorial.
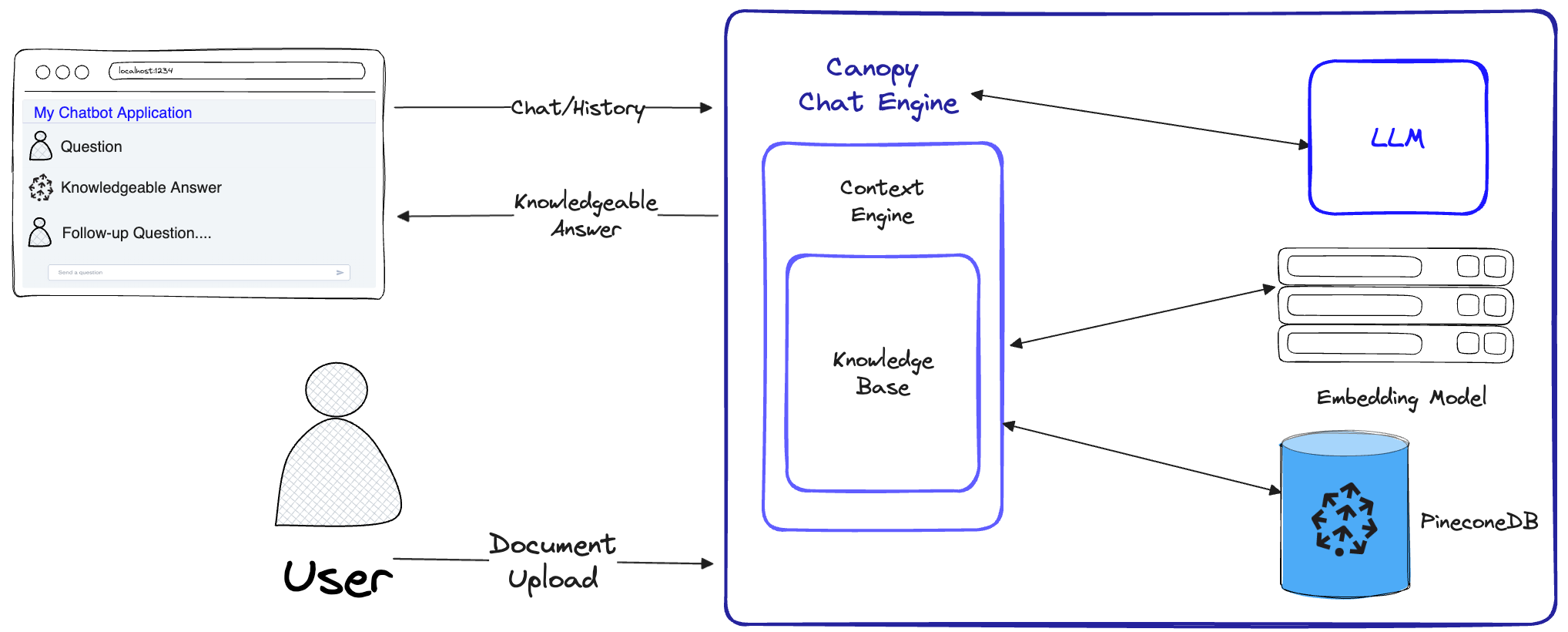
Canopy implementiert den vollständigen Lag -Workflow, um Halluzinationen zu verhindern und Ihre LLM mit Ihren eigenen Textdaten zu erweitern.
Canopy hat zwei Flüsse: Erstellung und Chat der Wissensbasis. Im Knowledge Base Base Creation Flow laden Benutzer ihre Dokumente hoch und verwandeln sie in aussagekräftige Darstellungen, die in der Vector -Datenbank von Pinecone gespeichert sind. Im Chat -Fluss werden eingehende Abfragen und Chat -Historien optimiert, um die relevantesten Dokumente abzurufen, die Wissensbasis wird abgefragt und ein aussagekräftiger Kontext wird für die LLM generiert.
ChatEngine relevante Abfragen in die ContextEngine und verwendet dann das LLM, um eine sachkundige Antwort zu generieren.ContextEngine verwendet die zugrunde liegende KnowledgeBase , um die relevantesten Dokumente abzurufen, und formuliert dann einen kohärenten textuellen Kontext, der als Aufforderung für die LLM verwendet werden soll.Weitere Informationen zur Nutzung der Kernbibliothek finden Sie in der Bibliotheksdokumentation
Canopy Server - Dies ist ein Webservice, der die Canopy -Kernbibliothek umhüllt und sie als REST -API enthüllt. Der Server ist auf Fastapi, Uvicorn und Gunicorn aufgebaut und kann problemlos in der Produktion eingesetzt werden. Der Server verfügt außerdem über eine integrierte Swagger-Benutzeroberfläche für einfache Tests und Dokumentation. Nachdem Sie den Server gestartet haben, können Sie auf die SWAGGE UI unter http://host:port/docs zugreifen (Standard: http://localhost:8000/docs )
Canopy Cli - Ein integriertes Entwicklungswerkzeug, mit dem Benutzer ihren eigenen Canopy -Server schnell einrichten und seine Konfiguration testen können.
Mit nur drei CLI-Befehlen können Sie einen neuen Canopy-Server erstellen, Ihre Dokumente darauf hochladen und dann mit dem Chatbot mit einer integrierten Chat-Anwendung direkt vom Terminal mit dem Chatbot interagieren. Der eingebaute Chatbot ermöglicht auch den Vergleich von ragig angereicherten Antworten mit einem nativen LLM-Chatbot.
python3 -m venv canopy-env
source canopy-env/bin/activateWeitere Informationen zu virtuellen Umgebungen finden Sie hier
pip install canopy-sdk| Name | Beschreibung |
|---|---|
grpc | Um einige Leistungsverbesserungen durch Arbeiten mit der GRPC -Version des Pinecone -Clients freizuschalten |
torch | Um Einbettungen zu aktivieren, die von Satztransformen bereitgestellt werden |
transformers | Wenn Sie AnyScale LLMs verwenden, wird empfohlen, LLamaTokenizer -Tokenizer zu verwenden, für die Transformatoren als Abhängigkeit erforderlich sind |
cohere | Cohere Reranker oder/und Cohere LLM verwenden |
qdrant | QDrant als alternative Wissensbasis zu verwenden |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| Name | Beschreibung | Wie bekomme ich es? |
|---|---|---|
PINECONE_API_KEY | Die API -Schlüssel für Tinecone. Wird verwendet, um sich mit Pnecone -Diensten zu authentifizieren, um Indizes zu erstellen und Daten einzufügen, zu löschen und zu suchen | Registrieren Sie sich oder melden Sie sich in Ihrem Pinecone -Konto in der Konsole an. Sie können auf Ihre API -Taste aus dem Abschnitt "API -Schlüssel" in der Seitenleiste Ihres Dashboards zugreifen |
OPENAI_API_KEY | API -Schlüssel für OpenAI. Wird verwendet, um sich mit den Diensten von Openai für ein Einbettung und Chat -API zu authentifizieren | Hier finden Sie Ihren OpenAI -API -Schlüssel. Möglicherweise müssen Sie sich anmelden oder sich an OpenAI -Dienste registrieren |
INDEX_NAME | Name des Pinecone Index -Canopy funktioniert mit dem zugrunde liegenden | Sie können einen beliebigen Namen auswählen, solange er die Beschränkungen von Pinecone folgt |
CANOPY_CONFIG_FILE | Der Pfad einer Konfiguration YAML -Datei, die vom Canopy -Server verwendet wird. | Optional - Wenn nicht angegeben, wird die Standardkonfiguration verwendet |
Diese optionalen Umgebungsvariablen werden verwendet, um sich mit anderen unterstützten Diensten für Einbettungen und LLMs zu authentifizieren. Wenn Sie Canopy so konfigurieren, dass Sie einen dieser Anbieter verwenden, müssten Sie die relevanten Umgebungsvariablen festlegen.
| Name | Beschreibung | Wie bekomme ich es? |
|---|---|---|
ANYSCALE_API_KEY | API -Schlüssel für AnyScale. Wird verwendet, um sich mit AnyScale -Endpunkten für Open Source LLMs zu authentifizieren | Sie können AnyScale -Endpunkte registrieren und hier Ihren API -Schlüssel finden |
CO_API_KEY | API -Schlüssel für Cohere. Wird verwendet, um die Authentifizierung für die Einbettung zu authentifizieren | Weitere Informationen zur Registrierung zur Registrierung finden Sie hier |
JINA_API_KEY | API -Schlüssel für Jina Ai. Wird verwendet, um die Dienste von Jinaai für ein Einbettung und Chat -API zu authentifizieren | Hier finden Sie Ihren OpenAI -API -Schlüssel. Möglicherweise müssen Sie sich anmelden oder sich an OpenAI -Dienste registrieren |
AZURE_OPENAI_ENDOINT | Die URL des von Ihnen bereitgestellten Azure OpenAI -Endpunkts. | Sie finden dies im Azure Openai -Portal unter _Keys und Endpunkten ' |
AZURE_OPENAI_API_KEY | Der API -Schlüssel für Ihre Azure OpenAI -Modelle. | Sie finden dies im Azure Openai -Portal unter _Keys und Endpunkten ' |
OCTOAI_API_KEY | API -Schlüssel für Octoai. Wird verwendet, um sich für Open Source LLMs zu authentifizieren, die in Octoai serviert werden | Sie können sich für Octoai anmelden und Ihren API -Schlüssel hier finden |
canopyDie Ausgabe sollte dem ähnlich sein:
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message In diesem QuickStart zeigen wir Ihnen, wie Sie den Baldachin verwenden, um ein einfaches Fragenbeantwortungssystem mit RAG (Abruf Augmented Generation) zu erstellen.
Als einmalige Einrichtung muss Canopy einen neuen Pinecone-Index erstellen, der so konfiguriert ist, dass er mit Canopy funktioniert.
canopy new Und folgen Sie den CLI -Anweisungen. Der erstellte Index hat ein Präfix canopy--<INDEX_NAME> .
Sie müssen diesen Prozess nur einmal für jeden Canopy -Index durchführen, den Sie erstellen möchten.
Weitere Informationen zu Pinecone -Indizes und der Verwaltung finden Sie im folgenden Leitfaden: Verständnis für Indizes
Sie können Daten mit dem Befehl in Ihren Canopy -Index laden:
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... Canopy unterstützt Dateien in jsonl , parquet und csv -Formaten. Zusätzlich können Sie Klartextdatendateien im .txt -Format laden. In diesem Fall wird jede Datei als ein einzelnes Dokument behandelt. Die Dokument -ID ist der Dateiname, und die Quelle ist der vollständige Pfad der Datei.
Hinweis : Dokumentfelder werden im Lappenfluss verwendet und sollten dem folgenden Schema einhalten:
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]In diesem Notebook wird angezeigt, wie Sie in diesem Format einen Datensatz erstellen. Befolgen Sie die Anweisungen in der CLI, wenn Sie Ihre Daten hochladen.
Tipp
Wenn Sie Ihre Daten in Namespaces trennen möchten, können Sie die Option --namespace oder die Variable INDEX_NAMESPACE -Umgebungsvariable verwenden.
Der Canopy -Server enthält die Funktionalität von Canopy über eine REST -API. Sie können nämlich Dokumente hochladen, relevante Dokumente für eine bestimmte Abfrage abrufen und mit Ihren Daten chatten. Der Server enthält einen A /chat.completion -Pletion -Endpunkt, der problemlos in jede Chat -Anwendung integriert werden kann. Um den Server zu starten, führen Sie aus:
canopy startJetzt sollten Sie mit der folgenden Standard -Uvicorn -Nachricht aufgefordert werden:
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Das war's! Sie können jetzt mit dem Canopy -Server mit jeder Chat -Anwendung beginnen, die den Endpunkt von A /chat.completion Pletion unterstützt.
Der Befehl canopy start hält das Terminal besetzt (empfohlene Verwendung). Wenn Sie den Server im Hintergrund ausführen möchten, können Sie den folgenden Befehl verwenden -
nohup canopy start &
Um den Server zu stoppen, drücken Sie einfach CTRL+C im Terminal, an dem Sie ihn gestartet haben.
Die CLI von Canopy wird mit einer integrierten Chat-App ausgestattet, mit der Sie interaktiv mit Ihren Textdaten chatten und RAG mit Nicht-Rag-Workflows nebeneinander vergleichen können, um die Ergebnisse zu bewerten
Stellen Sie in einem neuen Terminalfenster die erforderlichen Umgebungsvariablen ein und laufen Sie dann aus:
canopy chatDadurch wird eine Chat -Oberfläche in Ihrem Terminal geöffnet. Sie können Fragen stellen, und der Lag-infundierte Chatbot versucht, sie mit den von Ihnen hochgeladenen Daten zu beantworten.
Um die Chat-Antwort mit und ohne --no-rag zu vergleichen
Hinweis : Diese Methode wird derzeit nur mit OpenAI unterstützt.
canopy chat --no-ragDadurch wird ein ähnliches Chat-Schnittstellenfenster geöffnet, aber sowohl die RAG- als auch die Nicht-RAG-Antworten nebeneinander anzeigen.
Vielen Dank, dass Sie in Betracht gezogen haben, zu Baldachin beizutragen! Weitere Informationen finden Sie in unseren beitragenden Richtlinien.
Wenn Sie bereits eine Anwendung haben, die die OpenAI -API verwendet, können Sie sie in den Banach migrieren, indem Sie einfach den API -Endpunkt in http://host:port/v1 ändern, beispielsweise mit der Standardkonfiguration:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )Wenn Sie einen bestimmten Index -Namespace für das Chat verwenden möchten, können Sie den Namespace einfach an den API -Endpunkt anhängen:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" ) Canopy verwendet Fastapi als Web Framework und Uvicorn als ASGI -Server.
Um Canopy in der Produktion zu verwenden, wird empfohlen, das Docker -Image von Canopy für Ihre Produktionsanforderungen zu verwenden.
Für die Bereitstellung von Canopy auf der Google Cloud -Plattform (GCP) finden Sie die in der Bereitstellung in der GCP -Dokumentation bereitgestellten Beispiele.
Alternativ können Sie GuniCorn als WSGI von Produktionsgraden verwenden, weitere Details hier.
Legen Sie Ihren gewünschten PORT und Ihre Variablen für die Umgebung WORKER_COUNT ein und starten Sie den Server mit:
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT Wichtig
Der Server interagiert mit Diensten wie PineCone und OpenAI mit Ihren eigenen Authentifizierungsanmeldeinformationen. Bei der Bereitstellung des Servers in einem öffentlichen Webhosting -Anbieter wird empfohlen, einen Authentifizierungsmechanismus zu aktivieren, damit Ihr Server nur Anfragen von authentifizierten Benutzern stellt.


