canopy
0.9.0
Note
L'équipe de la canopée ne maintient plus ce référentiel. Merci pour votre soutien et votre enthousiasme pour le projet! Si vous recherchez une solution de chiffon gérée de haute qualité avec des mises à jour et des améliorations continues, veuillez consulter l'assistant Pinecone.
Le canopy est un cadre de génération de récupération open source (RAG) un moteur de contexte construit sur le dessus de la base de données vectorielle de Pinecone. La verrière vous permet d'expérimenter et de créer rapidement et facilement des applications en utilisant RAG. Commencez à discuter avec vos documents ou données texte avec quelques commandes simples.
Canopy prend le travail lourd pour créer des applications de chiffon: de la chasse et de l'intégration de vos données texte à la gestion de l'historique de chat, à l'optimisation des requêtes, à la récupération de contexte (y compris à l'ingénierie rapide) et à la génération augmentée.
Canopy fournit un serveur intégré configurable afin que vous puissiez déployer sans effort une application de chat alimentée par chiffon vers votre interface de chat ou interface existante. Ou vous pouvez créer votre propre application de chiffon personnalisée à l'aide de la bibliothèque de la canopée.
La verrière vous permet d'évaluer votre flux de travail de chiffon avec un outil de chat basé sur la CLI. Avec une commande simple dans la CLI de la canopée, vous pouvez discuter de manière interactive avec vos données de texte et comparer RAG par rapport aux workflows non-RAG côte à côte.
Consultez notre article de blog pour en savoir plus ou voir un tutoriel rapide ici.
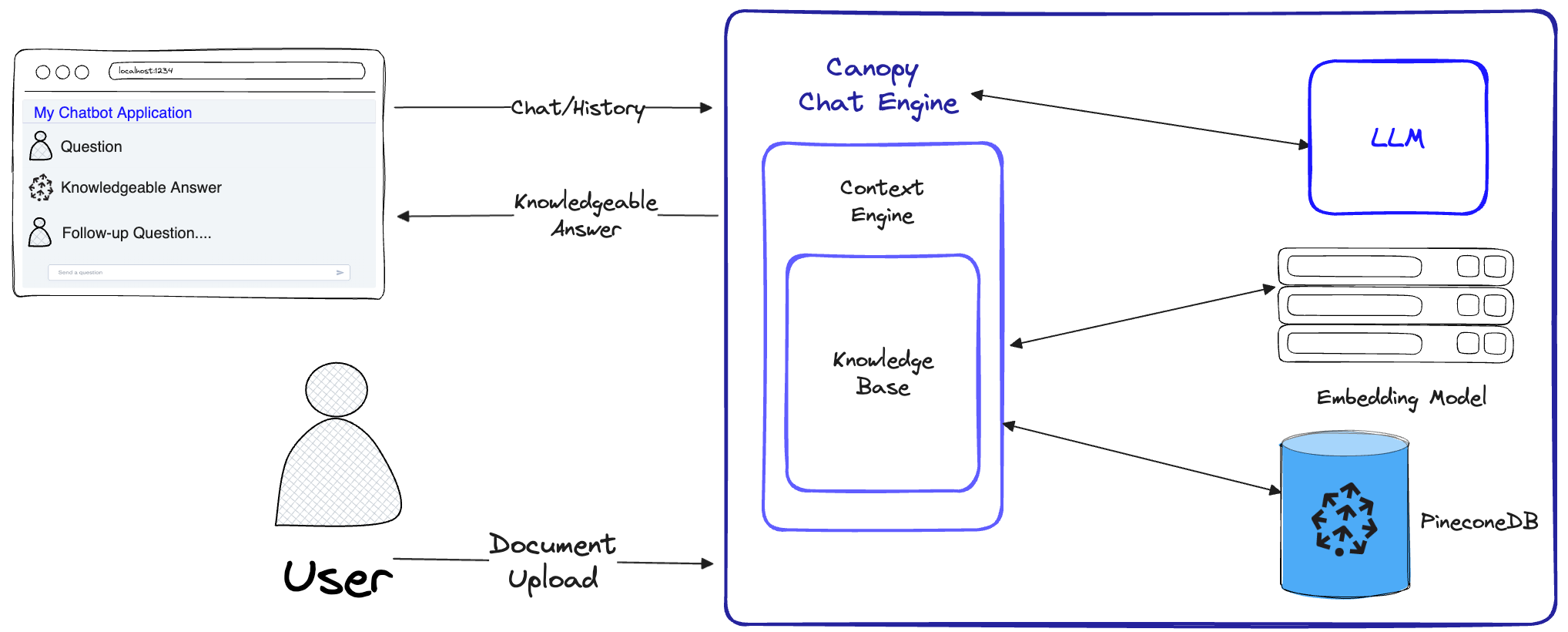
Canopy implémente le flux de travail complet pour empêcher les hallucinations et augmenter votre LLM avec vos propres données de texte.
Canopy a deux flux: la création de la base de connaissances et le chat. Dans le flux de création de base de connaissances, les utilisateurs téléchargent leurs documents et les transforment en représentations significatives stockées dans la base de données vectorielle de Pinecone. Dans le flux de chat, les requêtes entrantes et l'historique de chat sont optimisées pour récupérer les documents les plus pertinents, la base de connaissances est interrogée et un contexte significatif est généré pour que le LLM réponde.
ChatEngine formule des requêtes pertinentes pour le ContextEngine , puis utilise le LLM pour générer une réponse compétente.ContextEngine utilise la KnowledgeBase sous-jacente pour récupérer les documents les plus pertinents, puis formule un contexte textuel cohérent à utiliser comme invite pour le LLM.Plus d'informations sur l'utilisation de la bibliothèque de base peuvent être trouvées dans la documentation de la bibliothèque
Canopy Server - Il s'agit d'un service Web qui enveloppe la bibliothèque de base de la canopée et l'expose en API REST. Le serveur est construit sur Fastapi, Uvicorn et Gunicorn et peut être facilement déployé en production. Le serveur est également livré avec une interface utilisateur de fanfaronnade intégrée pour des tests et une documentation faciles. Après avoir démarré le serveur, vous pouvez accéder à l'interface utilisateur de Swagger sur http://host:port/docs (par défaut: http://localhost:8000/docs )
CLI CLI - Un outil de développement intégré qui permet aux utilisateurs de configurer rapidement leur propre serveur de canopée et de tester sa configuration.
Avec seulement trois commandes CLI, vous pouvez créer un nouveau serveur de canopée, télécharger vos documents, puis interagir avec le chatbot à l'aide d'une application de chat intégrée directement à partir du terminal. Le chatbot intégré permet également la comparaison des réponses infusées par le chiffon contre un chatbot LLM natif.
python3 -m venv canopy-env
source canopy-env/bin/activatePlus d'informations sur les environnements virtuels peuvent être trouvés ici
pip install canopy-sdk| Nom | Description |
|---|---|
grpc | Pour déverrouiller certaines améliorations des performances en travaillant avec la version GRPC du client Pinecone |
torch | Activer les intégres fournis par les transformateurs de phrases |
transformers | Si vous utilisez des LLM de LLamaTokenizer |
cohere | Pour utiliser Cohere Reranker ou / et Cohere LLM |
qdrant | Utiliser Qdrant comme base de connaissances alternative |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| Nom | Description | Comment l'obtenir? |
|---|---|---|
PINECONE_API_KEY | La touche API pour Pinecone. Utilisé pour s'authentifier aux services PineCone pour créer des index et insérer, supprimer et rechercher des données | Inscrivez-vous ou connectez-vous à votre compte Pinecone dans la console. Vous pouvez accéder à votre clé API à partir de la section "Clés API" dans la barre latérale de votre tableau de bord |
OPENAI_API_KEY | Clé API pour Openai. Utilisé pour s'authentifier aux services d'Openai pour l'intégration et l'API de chat | Vous pouvez trouver votre clé API OpenAI ici. Vous devrez peut-être vous connecter ou vous inscrire aux services Openai |
INDEX_NAME | Le nom de la canopée de l'index de pinone sous-tendra le travail avec | Vous pouvez choisir n'importe quel nom tant qu'il suit les restrictions de Pinecone |
CANOPY_CONFIG_FILE | Le chemin d'accès d'un fichier YAML de configuration à utiliser par le serveur de canopée. | Facultatif - s'il n'est pas fourni, la configuration par défaut serait utilisée |
Ces variables d'environnement facultatives sont utilisées pour s'authentifier avec d'autres services pris en charge pour les intégres et les LLM. Si vous configurez une canopée pour utiliser l'un de ces fournisseurs - vous devrez définir les variables d'environnement pertinentes.
| Nom | Description | Comment l'obtenir? |
|---|---|---|
ANYSCALE_API_KEY | Clé API pour tout système. Utilisé pour s'authentifier avec tous les points de terminaison pour les LLMS open source | Vous pouvez enregistrer n'importe quel point de terminaison et trouver votre clé API ici |
CO_API_KEY | Clé API pour Cohere. Utilisé pour s'authentifier pour cohérer les services pour intégrer | Vous pouvez trouver plus d'informations sur l'inscription pour cohérer ici |
JINA_API_KEY | Clé API pour Jina Ai. Utilisé pour s'authentifier aux services de Jinaai pour l'intégration et l'API de chat | Vous pouvez trouver votre clé API OpenAI ici. Vous devrez peut-être vous connecter ou vous inscrire aux services Openai |
AZURE_OPENAI_ENDOINT | L'URL du point de terminaison Azure Openai que vous avez déployé. | Vous pouvez le trouver dans le portail Azure Openai sous _KEYS et Point de terminaison` |
AZURE_OPENAI_API_KEY | La clé API à utiliser pour vos modèles Azure OpenAI. | Vous pouvez le trouver dans le portail Azure Openai sous _KEYS et Point de terminaison` |
OCTOAI_API_KEY | Clé API pour Octoai. Utilisé pour s'authentifier pour les LLM open source servies en octoai | Vous pouvez vous inscrire à Octoai et trouver votre clé API ici |
canopyLa sortie doit être similaire à ceci:
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message Dans ce QuickStart, nous vous montrerons comment utiliser la canopée pour construire un système de réponse simple à l'aide de RAG (Génération augmentée de récupération).
En tant que configuration unique, la canopée doit créer un nouvel index de pinone qui est configuré pour fonctionner avec Canopy, il suffit d'exécuter:
canopy new Et suivez les instructions CLI. L'index qui sera créé aura une canopy--<INDEX_NAME> .
Vous n'avez qu'à faire ce processus une seule fois pour chaque indice de canopée que vous souhaitez créer.
Pour en savoir plus sur les index Pinecone et comment les gérer, veuillez vous référer au guide suivant: Comprendre les index
Vous pouvez charger des données dans votre index de la canopée à l'aide de la commande:
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... Canopy prend en charge les fichiers dans les formats jsonl , parquet et csv . De plus, vous pouvez charger des fichiers de données en texte clair au format .txt . Dans ce cas, chaque fichier sera traité comme un seul document. L'ID de document sera le nom de fichier et la source sera le chemin complet du fichier.
Remarque : les champs de document sont utilisés dans le flux de chiffon et doivent se conformer au schéma suivant:
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]Ce cahier montre comment vous créez un ensemble de données dans ce format, suivez les instructions de la CLI lorsque vous téléchargez vos données.
Conseil
Si vous souhaitez séparer vos données en espaces de noms, vous pouvez utiliser l'option --namespace ou la variable INDEX_NAMESPACE Environment.
Le serveur Canopy expose les fonctionnalités de Canopy via une API REST. À savoir, il vous permet de télécharger des documents, de récupérer des documents pertinents pour une requête donnée et de discuter avec vos données. Le serveur expose un point de terminaison A /chat.completion qui peut être facilement intégré à n'importe quelle application de chat. Pour démarrer le serveur, exécutez:
canopy startMaintenant, vous devez être invité avec le message standard suivant en uvicorne:
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
C'est ça! Vous pouvez maintenant commencer à utiliser le serveur Canopy avec n'importe quelle application de chat qui prend en charge le point de terminaison A /chat.completion ........... ce
La commande de démarrage de la canopée gardera le terminal occupé (utilisation recommandée). Si vous souhaitez exécuter le serveur en arrière-plan, vous pouvez utiliser la commande suivante -
nohup canopy start &
Pour arrêter le serveur, appuyez simplement sur CTRL+C dans le terminal où vous l'avez commencé.
La CLI de Canopy est livrée avec une application de chat intégrée qui vous permet de discuter de manière interactive avec vos données de texte et de comparer le chiffon par rapport aux workflows non-RAG côte à côte pour évaluer les résultats
Dans une nouvelle fenêtre de terminal, définissez les variables d'environnement requises puis exécutez:
canopy chatCela ouvrira une interface de chat dans votre terminal. Vous pouvez poser des questions et le chatbot infusé de chiffon essaiera d'y répondre en utilisant les données que vous avez téléchargées.
Pour comparer la réponse de chat avec et sans chiffon, utilisez le drapeau --no-rag
Remarque : cette méthode n'est prise en charge qu'avec OpenAI pour le moment.
canopy chat --no-ragCela ouvrira une fenêtre d'interface de chat similaire, mais affichera à la fois les réponses de chiffon et de non-Rag côte à côte.
Merci d'avoir envisagé de contribuer à Canopy! Veuillez consulter nos directives contributives pour plus d'informations.
Si vous avez déjà une application qui utilise l'API OpenAI, vous pouvez la migrer vers la canopée en modifiant simplement le point de terminaison de l'API en http://host:port/v1 , par exemple avec la configuration par défaut:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )Si vous souhaitez utiliser un espace de noms d'index spécifique pour discuter, vous pouvez simplement ajouter l'espace de noms au point de terminaison de l'API:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" ) Canopy utilise Fastapi comme framework Web et Uvicorn comme serveur ASGI.
Pour utiliser la canopée dans la production, il est recommandé d'utiliser l'image Docker de Canopy, disponible sur les packages GitHub, pour vos besoins de production.
Pour obtenir des conseils sur le déploiement de la verrière sur la plate-forme Google Cloud (GCP), reportez-vous à l'exemple fourni dans le déploiement de la documentation GCP.
Alternativement, vous pouvez utiliser Gunicorn comme WSGI de qualité de production, plus de détails ici.
Définissez les variables de votre PORT et WORKER_COUNT , et démarrez le serveur avec:
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT Important
Le serveur interagit avec des services comme PineCone et OpenAI à l'aide de vos propres informations d'authentification. Lors du déploiement du serveur sur un fournisseur d'hébergement Web public, il est recommandé d'activer un mécanisme d'authentification, afin que votre serveur ne prenne que les demandes des utilisateurs authentifiés.


