canopy
0.9.0
메모
캐노피 팀은 더 이상이 저장소를 유지하지 않습니다. 프로젝트에 대한 귀하의 지원과 열정에 감사드립니다! 지속적인 업데이트 및 개선 사항이있는 고품질 관리 래그 솔루션을 찾고 있다면 Pinecone Assistant를 확인하십시오.
Canopy 는 Pinecone Vector 데이터베이스 위에 구축 된 오픈 소스 검색 증강 생성 (RAG) 프레임 워크 및 컨텍스트 엔진입니다. Canopy를 사용하면 Rag를 사용하여 신속하고 쉽게 실험하고 구축 할 수 있습니다. 몇 가지 간단한 명령으로 문서 나 텍스트 데이터와 채팅을 시작하십시오.
Canopy는 텍스트 데이터 청킹 및 임베드에서 채팅 기록 관리, 쿼리 최적화, 컨텍스트 검색 (프롬프트 엔지니어링 포함) 및 증강 된 생성에 이르기까지 Rag Applications를 구축하기위한 무거운 리프팅을 취합니다.
Canopy는 구성 가능한 내장 서버를 제공하므로 기존 채팅 UI 또는 인터페이스에 래그 전원 채팅 응용 프로그램을 쉽게 배포 할 수 있습니다. 또는 캐노피 라이브러리를 사용하여 자신의 맞춤형 래그 응용 프로그램을 구축 할 수 있습니다.
Canopy를 사용하면 CLI 기반 채팅 도구로 Rag 워크 플로를 평가할 수 있습니다. Canopy CLI의 간단한 명령을 사용하면 텍스트 데이터와 대화식으로 채팅하고 Rag와 비 RAG 워크 플로를 나란히 비교할 수 있습니다.
블로그 게시물을 확인하여 자세한 내용을 확인하거나 여기에서 빠른 자습서를 참조하십시오.
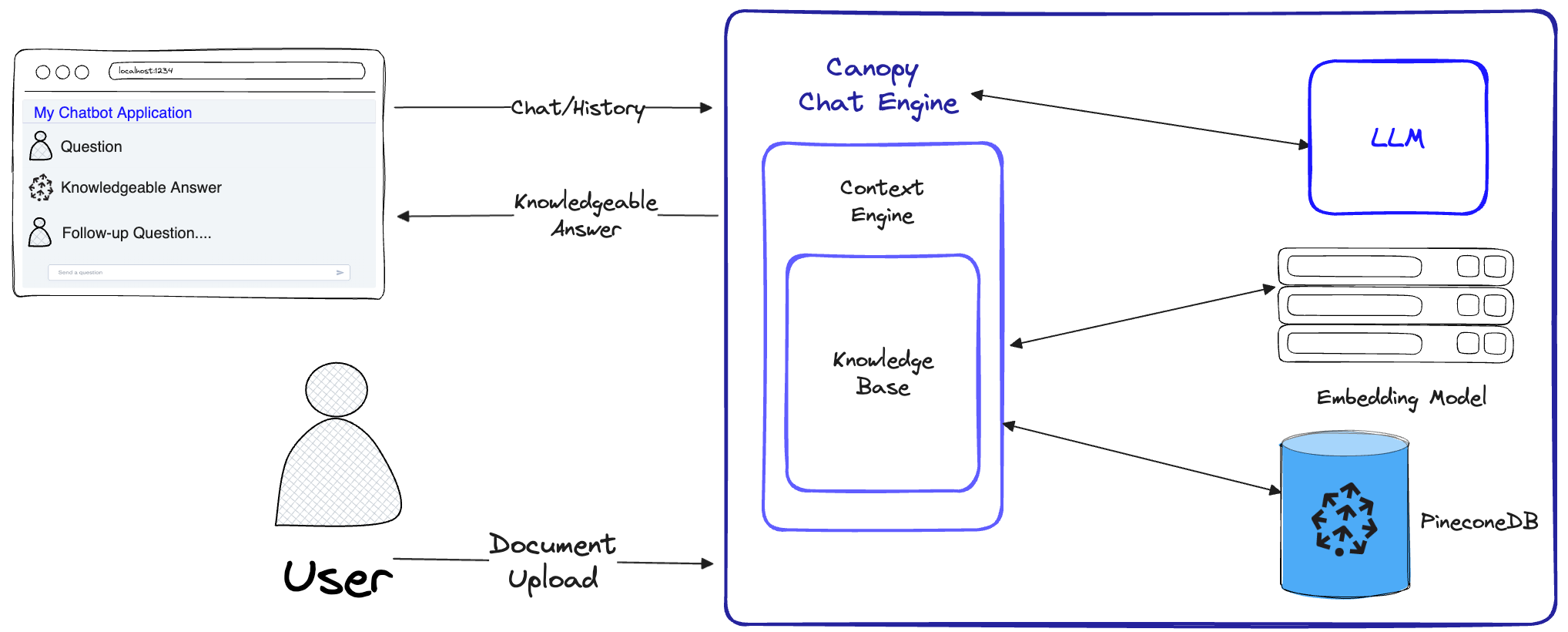
캐노피는 환각을 방지하고 자신의 텍스트 데이터로 LLM을 강화하기 위해 전체 걸레 워크 플로를 구현합니다.
캐노피에는 지식 기반 창조와 채팅의 두 가지 흐름이 있습니다. 지식 기반 생성 흐름에서 사용자는 문서를 업로드하여 Pinecone의 벡터 데이터베이스에 저장된 의미있는 표현으로 변환합니다. 채팅 흐름에서 들어오는 쿼리 및 채팅 기록은 가장 관련성이 높은 문서를 검색하도록 최적화되며, 지식 기반이 쿼리되며 LLM이 답변 할 수있는 의미있는 컨텍스트가 생성됩니다.
ChatEngine ContextEngine 과 관련 쿼리를 공식화 한 다음 LLM을 사용하여 지식이 풍부한 응답을 생성합니다.ContextEngine 기본 KnowledgeBase 활용하여 가장 관련성이 높은 문서를 검색 한 다음 LLM의 프롬프트로 사용될 일관된 텍스트 컨텍스트를 공식화합니다.핵심 라이브러리 사용에 대한 자세한 내용은 라이브러리 문서를 참조하십시오.
CANOPY SERVER- 이것은 Canopy Core 라이브러리를 감싸고 REST API로 노출시키는 웹 서비스입니다. 이 서버는 Fastapi, Uvicorn 및 Gunicorn 위에 구축되었으며 생산에 쉽게 배치 할 수 있습니다. 서버에는 또한 쉬운 테스트 및 문서화를 위해 내장 Swagger UI가 제공됩니다. 서버를 시작하면 http://host:port/docs (기본값 : http://localhost:8000/docs )에서 Swagger UI에 액세스 할 수 있습니다.
Canopy CLI- 사용자가 자체 캐노피 서버를 신속하게 설정하고 구성을 테스트 할 수있는 내장 개발 도구입니다.
3 개의 CLI 명령만으로 새 캐노피 서버를 작성하고 문서를 업로드 한 다음 터미널에서 직접 내장 채팅 응용 프로그램을 사용하여 챗봇과 상호 작용할 수 있습니다. 내장 챗봇은 또한 기본 LLM 챗봇과의 래그 주입 응답을 비교할 수 있습니다.
python3 -m venv canopy-env
source canopy-env/bin/activate가상 환경에 대한 자세한 내용은 여기를 참조하십시오
pip install canopy-sdk| 이름 | 설명 |
|---|---|
grpc | GRPC 버전의 PENECONE 클라이언트로 작업하여 성능 향상을 잠금 해제하려면 |
torch | 문장 변환기가 제공하는 임베딩을 가능하게합니다 |
transformers | 스케일 LLM을 사용하는 경우 변압기가 의존성으로 필요한 LLamaTokenizer 토큰 화기를 사용하는 것이 좋습니다. |
cohere | Cohere Reranker 또는/및 Cohere LLM을 사용합니다 |
qdrant | 대체 지식 기반으로 qdrant를 사용합니다 |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| 이름 | 설명 | 그것을 얻는 방법? |
|---|---|---|
PINECONE_API_KEY | PENECONE의 API 키. 인덱스를 만들고 데이터를 삽입, 삭제 및 검색하기 위해 PENECONE 서비스에 인증하는 데 사용됩니다. | 콘솔에서 PENECONE 계정을 등록하거나 로그인하십시오. 대시 보드의 사이드 바에있는 "API 키"섹션에서 API 키에 액세스 할 수 있습니다. |
OPENAI_API_KEY | OpenAI의 API 키. 임베딩 및 채팅 API를위한 OpenAI의 서비스에 인증하는 데 사용 | 여기에서 OpenAI API 키를 찾을 수 있습니다. OpenAI 서비스에 로그인하거나 등록해야 할 수도 있습니다. |
INDEX_NAME | PENECONE Index Canopy의 이름은 | Pinecone의 제한에 따라 이름을 선택할 수 있습니다. |
CANOPY_CONFIG_FILE | Canopy Server에서 사용할 구성 Yaml 파일의 경로. | 선택 사항 - 제공되지 않으면 기본 구성이 사용됩니다. |
이러한 선택적 환경 변수는 임베딩 및 LLM에 대한 다른 지원되는 서비스를 인증하는 데 사용됩니다. 이러한 공급자를 사용하도록 캐노피를 구성하는 경우 관련 환경 변수를 설정해야합니다.
| 이름 | 설명 | 그것을 얻는 방법? |
|---|---|---|
ANYSCALE_API_KEY | 모든 규모에 대한 API 키. 오픈 소스 LLMS의 모든 스케일 엔드 포인트로 인증하는 데 사용 | 스케일 엔드 포인트를 등록하고 여기에서 API 키를 찾을 수 있습니다. |
CO_API_KEY | Cohere의 API 키. 임베딩을위한 코셔 서비스에 인증하는 데 사용됩니다 | Cohere 등록에 대한 자세한 정보는 여기를 참조하십시오. |
JINA_API_KEY | Jina AI의 API 키. API를 포함시키고 채팅하기 위해 Jinaai의 서비스에 인증하는 데 사용됩니다. | 여기에서 OpenAI API 키를 찾을 수 있습니다. OpenAI 서비스에 로그인하거나 등록해야 할 수도 있습니다. |
AZURE_OPENAI_ENDOINT | 배포 한 Azure Openai 엔드 포인트의 URL. | _keys and endpoints의 Azure Openai 포털에서 찾을 수 있습니다. |
AZURE_OPENAI_API_KEY | Azure OpenAI 모델에 사용할 API 키. | _keys and endpoints의 Azure Openai 포털에서 찾을 수 있습니다. |
OCTOAI_API_KEY | Octoai의 API 키. Octoai에서 제공되는 오픈 소스 LLMS를 인증하는 데 사용 | Octoai에 가입하고 여기에서 API 키를 찾을 수 있습니다. |
canopy출력은 다음과 유사해야합니다.
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message 이 빠른 스타트에서는 캐노피를 사용하여 RAG (검색 증강 생성)를 사용하여 간단한 질문 응답 시스템을 구축하는 방법을 보여줍니다.
일회성 설정으로 Canopy는 Canopy와 함께 작동하도록 구성된 새로운 Pinecone 인덱스를 만들어야합니다.
canopy new CLI 지침을 따르십시오. 생성 될 인덱스에는 접두사 canopy--<INDEX_NAME> 가 있습니다.
생성하려는 모든 캐노피 인덱스에 대해이 프로세스를 한 번만 수행하면됩니다.
Pinecone Indexes 및이를 관리하는 방법에 대한 자세한 내용은 다음 안내서를 참조하십시오. 인덱스 이해
명령을 사용하여 캐노피 인덱스에 데이터를로드 할 수 있습니다.
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... Canopy는 jsonl , parquet 및 csv 형식의 파일을 지원합니다. 또한 일반 텍스트 데이터 파일을 .txt 형식으로로드 할 수 있습니다. 이 경우 각 파일은 단일 문서로 취급됩니다. 문서 ID는 파일 이름이되며 소스는 파일의 전체 경로가됩니다.
참고 : 문서 필드는 헝겊 흐름에 사용되며 다음 스키마를 준수해야합니다.
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]이 노트는이 형식으로 데이터 세트를 만드는 방법을 보여주고 데이터를 업로드 할 때 CLI의 지침을 따르십시오.
팁
데이터를 네임 스페이스로 분리하려면 --namespace 옵션 또는 INDEX_NAMESPACE 환경 변수를 사용할 수 있습니다.
Canopy Server는 REST API를 통해 Canopy의 기능을 노출시킵니다. 즉, 문서를 업로드하고 관련 문서를 검색하고 데이터와 채팅 할 수 있습니다. 서버는 채팅 애플리케이션과 쉽게 통합 될 수있는 /chat.completion 엔드 포인트를 노출시킵니다. 서버를 시작하려면 실행 :
canopy start이제 다음 표준 UVICORN 메시지가 표시되어야합니다.
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
그게 다야! 이제 /chat.completion endpoint를 지원하는 채팅 애플리케이션으로 Canopy Server를 사용하기 시작할 수 있습니다.
Canopy Start 명령은 터미널을 유지합니다 (권장 사용). 백그라운드에서 서버를 실행하려면 다음 명령을 사용할 수 있습니다
nohup canopy start &
서버를 중지하려면 서버를 시작한 터미널에서 CTRL+C 누릅니다.
Canopy의 CLI는 텍스트 데이터와 대화식으로 채팅하고 RAG 대 비 라그 워크 플로를 나란히 비교하여 결과를 평가할 수있는 내장 채팅 앱과 함께 제공됩니다.
새 터미널 창에서 필요한 환경 변수를 설정 한 다음 실행합니다.
canopy chat터미널에서 채팅 인터페이스가 열립니다. 질문을 할 수 있고 Rag-infused Chatbot은 업로드 한 데이터를 사용하여 답변하려고합니다.
래그와 함께 채팅 응답을 비교하려면 --no-rag 플래그를 사용하십시오.
참고 :이 방법은 현재 OpenAI에서만 지원됩니다.
canopy chat --no-rag이것은 비슷한 채팅 인터페이스 창을 열지 만 헝겊과 비 래그 응답을 나란히 보여줍니다.
캐노피에 기여하는 것을 고려해 주셔서 감사합니다! 자세한 내용은 기고 가이드 라인을 참조하십시오.
OpenAI API를 사용하는 응용 프로그램이 이미있는 경우 API 엔드 포인트를 http://host:port/v1 로 변경하여 기본 구성과 같은 간단히 캐노피 로 마이그레이션 할 수 있습니다.
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )채팅을 위해 특정 인덱스 네임 스페이스를 사용하려면 네임 스페이스를 API 엔드 포인트에 추가 할 수 있습니다.
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" ) Canopy는 FastApi를 웹 프레임 워크로 사용하고 Uvicorn을 ASGI 서버로 사용하고 있습니다.
생산에 캐노피를 사용하려면 생산 요구를 위해 GitHub 패키지에서 제공되는 Canopy의 Docker 이미지를 사용하는 것이 좋습니다.
GCP (Google Cloud Platform)에 Canopy 배포에 대한 지침은 GCP 문서에 배포 된 예제를 참조하십시오.
또는 Gunicorn을 생산 등급 WSGI로 사용할 수 있습니다. 자세한 내용은 여기를 참조하십시오.
원하는 PORT 및 WORKER_COUNT Envrionment 변수를 설정하고 다음을 사용하여 서버를 시작하십시오.
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT 중요한
서버는 자신의 인증 자격 증명을 사용하여 Pinecone 및 OpenAi와 같은 서비스와 상호 작용합니다. 공개 웹 호스팅 제공 업체에 서버를 배포 할 때는 인증 메커니즘을 활성화하여 서버가 인증 된 사용자로부터 요청 만 받도록 권장됩니다.


