canopy
0.9.0
注記
Canopyチームは、このリポジトリを維持しなくなりました。プロジェクトへのご支援と熱意に感謝します!継続的な更新と改善を備えた高品質のマネージドラグソリューションをお探しの場合は、Pineconeアシスタントをご覧ください。
Canopyは、Pinecone Vectorデータベースの上に構築されたオープンソース検索拡張生成(RAG)フレームワークとコンテキストエンジンです。 Canopyを使用すると、RAGを使用してアプリケーションをすばやく簡単に実験して構築できます。いくつかの簡単なコマンドを使用して、ドキュメントまたはテキストデータとのチャットを開始します。
キャノピーは、ぼろきれのアプリケーションを構築するための重い持ち上げを引き受けます。テキストデータのチャンキングと埋め込みから、チャット履歴管理、クエリの最適化、コンテキスト検索(迅速なエンジニアリングを含む)、および拡張生成。
Canopyは構成可能なビルトインサーバーを提供するため、既存のチャットUIまたはインターフェイスにぼろきれのチャットアプリケーションを簡単に展開できます。または、Canopyライブラリを使用して独自のカスタムラグアプリケーションを構築することもできます。
Canopyを使用すると、CLIベースのチャットツールでRAGワークフローを評価できます。 Canopy CLIにシンプルなコマンドを使用すると、テキストデータとインタラクティブにチャットし、RAGと非レイグワークフローを並べて比較できます。
詳細については、ブログ投稿をご覧ください。または、こちらの簡単なチュートリアルをご覧ください。
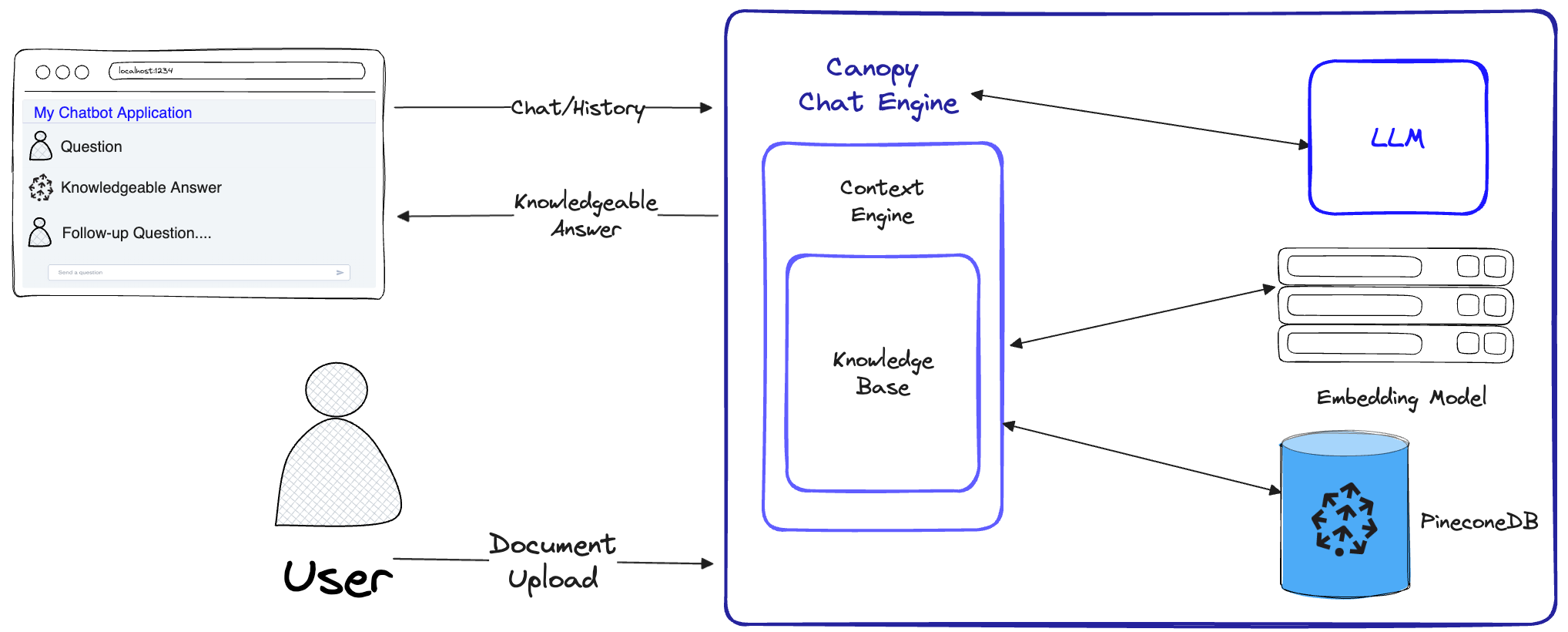
キャノピーは、幻覚を防ぐために完全なぼろきれワークフローを実装し、独自のテキストデータでLLMを増やします。
キャノピーには、知識ベースの作成とチャットの2つのフローがあります。ナレッジベースの作成フローでは、ユーザーはドキュメントをアップロードし、PineconeのVectorデータベースに保存されている意味のある表現に変換します。チャットフローでは、着信クエリとチャット履歴が最適化され、最も関連性の高いドキュメントを取得し、知識ベースがクエリが施され、LLMが回答できる意味のあるコンテキストが生成されます。
ChatEngine ContextEngineに関連するクエリを策定し、LLMを使用して知識豊富な応答を生成します。ContextEngine 、基礎となるKnowledgeBaseベースを利用して最も関連性の高いドキュメントを取得し、LLMのプロンプトとして使用するコヒーレントテキストコンテキストを策定します。コアライブラリの使用に関する詳細については、ライブラリのドキュメントをご覧ください。
Canopy Server-これは、Canopy Coreライブラリをラップし、REST APIとして公開するWebサービスです。サーバーは、Fastapi、Uvicorn、Gunicornの上に構築されており、生産で簡単に展開できます。サーバーには、簡単にテストしてドキュメントを簡単にするためのSwagger UIが組み込まれています。サーバーを起動すると、 http://host:port/docsでSwagger UIにアクセスできます(デフォルト: http://localhost:8000/docs )
Canopy CLI-ユーザーが独自のCanopyサーバーを迅速にセットアップして構成をテストできる組み込み開発ツール。
たった3つのCLIコマンドを使用すると、新しいCanopyサーバーを作成し、ドキュメントをアップロードしてから、ターミナルから直接組み込みのチャットアプリケーションを使用してチャットボットと対話できます。組み込みのチャットボットは、ネイティブLLMチャットボットに対するぼろきれの応答を比較することもできます。
python3 -m venv canopy-env
source canopy-env/bin/activate仮想環境の詳細については、こちらをご覧ください
pip install canopy-sdk| 名前 | 説明 |
|---|---|
grpc | PineconeクライアントのGRPCバージョンと連携することで、いくつかのパフォーマンスの改善を解除するため |
torch | 文の変換者が提供する埋め込みを有効にするため |
transformers | スケールのLLMSを使用している場合は、依存関係として変圧器を必要とするLLamaTokenizerトークナイザーを使用することをお勧めします |
cohere | Cohere Rerankerまたは/およびCohere LLMを使用するには |
qdrant | QDRANTを代替の知識ベースとして使用します |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| 名前 | 説明 | それを手に入れる方法は? |
|---|---|---|
PINECONE_API_KEY | PineconeのAPIキー。インデックスを作成し、データを挿入、削除、検索するためにPineconeサービスを認証するために使用されます | コンソールのPineconeアカウントに登録またはログインします。ダッシュボードのサイドバーにある「APIキー」セクションからAPIキーにアクセスできます |
OPENAI_API_KEY | OpenaiのAPIキー。埋め込みおよびチャットAPIのためにOpenaiのサービスに認証するために使用されます | Openai APIキーはこちらから見つけることができます。 OpenAIサービスにログインまたは登録する必要があるかもしれません |
INDEX_NAME | Pinecone Index Canopyの名前は、 | Pineconeの制限に従う限り、任意の名前を選択できます |
CANOPY_CONFIG_FILE | Canopyサーバーが使用する構成YAMLファイルのパス。 | オプション - 提供されていない場合、デフォルトの構成が使用されます |
これらのオプションの環境変数は、埋め込みおよびLLMの他のサポートされているサービスに認証するために使用されます。これらのプロバイダーのいずれかを使用するようにCanopyを構成する場合 - 関連する環境変数を設定する必要があります。
| 名前 | 説明 | それを手に入れる方法は? |
|---|---|---|
ANYSCALE_API_KEY | あらゆるスケールのAPIキー。オープンソースLLMの任意のスケールエンドポイントに認証するために使用されます | スケールのエンドポイントを登録して、ここでAPIキーを見つけることができます |
CO_API_KEY | CohereのAPIキー。埋め込みのためにサービスを網羅するために認証するために使用されます | 登録に関する詳細については、こちらをご覧ください |
JINA_API_KEY | Jina AIのAPIキー。埋め込みおよびチャットAPIのためにJinaaiのサービスに認証するために使用されます | Openai APIキーはこちらから見つけることができます。 OpenAIサービスにログインまたは登録する必要があるかもしれません |
AZURE_OPENAI_ENDOINT | 展開したAzure OpenaiエンドポイントのURL。 | これは、_keys and endpoints`の下のAzure Openaiポータルで見つけることができます |
AZURE_OPENAI_API_KEY | Azure Openaiモデルに使用するAPIキー。 | これは、_keys and endpoints`の下のAzure Openaiポータルで見つけることができます |
OCTOAI_API_KEY | OctoaiのAPIキー。 Octoaiで提供されるオープンソースLLMの認証に使用 | Octoaiにサインアップして、ここでAPIキーを見つけることができます |
canopy出力はこれに似ている必要があります。
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message このQuickStartでは、 Canopyを使用してRAG(検索拡張生成)を使用して簡単な質問応答システムを構築する方法を示します。
1回限りのセットアップとして、CanopyはCanopyで動作するように構成されている新しいPineconeインデックスを作成する必要があります。
canopy new CLIの指示に従ってください。作成されるインデックスには、プレフィックスcanopy--<INDEX_NAME>があります。
作成するすべてのキャノピーインデックスに対して、このプロセスを1回だけ行う必要があります。
Pinecone Indexesの詳細とそれらの管理方法については、次のガイドを参照してください。インデックスの理解
コマンドを使用してデータをキャノピーインデックスにロードできます。
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... Canopyは、 jsonl 、 parquet 、 csv形式のファイルをサポートしています。さらに、Plantextデータファイルを.txt形式でロードできます。この場合、各ファイルは単一のドキュメントとして扱われます。ドキュメントIDはファイル名であり、ソースはファイルのフルパスになります。
注:ドキュメントフィールドはラグフローで使用され、次のスキーマに準拠する必要があります。
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]このノートブックは、この形式でデータセットを作成する方法を示しています。データをアップロードしたときのCLIの指示に従ってください。
ヒント
データを名前空間に分離する場合は、 --namespaceオプションまたはINDEX_NAMESPACE環境変数を使用できます。
Canopy Serverは、REST APIを介してCanopyの機能を公開します。つまり、ドキュメントをアップロードし、特定のクエリに関連するドキュメントを取得し、データとチャットすることができます。サーバーは、任意のチャットアプリケーションと簡単に統合できるA /chat.completionエンドポイントを公開します。サーバーを起動するには、実行してください。
canopy startこれで、次の標準的なUVICORNメッセージを求められる必要があります。
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
それでおしまい!これで、A /chat.completionエンドポイントをサポートするチャットアプリケーションでCanopyサーバーの使用を開始できます。
Canopy Startコマンドは、端末を占有し続けます(推奨使用)。バックグラウンドでサーバーを実行する場合は、次のコマンドを使用できます
nohup canopy start &
サーバーを停止するには、開始した端末にCTRL+Cを押すだけです。
CanopyのCLIには、テキストデータとインタラクティブにチャットし、RAGとRAGのワークフローを並べて比較するために、結果を評価できる組み込みチャットアプリが付属しています。
新しい端子ウィンドウで、必要な環境変数を設定してから実行します。
canopy chatこれにより、端末にチャットインターフェイスが開きます。質問をすることができ、ragに注目したチャットボットは、アップロードしたデータを使用してそれらに応答しようとします。
ラグの有無にかかわらずチャットの応答を比較するには--no-ragフラグを使用します
注:この方法は、現時点ではOpenaiでのみサポートされています。
canopy chat --no-ragこれにより、同様のチャットインターフェイスウィンドウが開きますが、RAG応答と非ラグの両方の応答の両方が並んで表示されます。
キャノピーへの貢献を検討していただきありがとうございます!詳細については、貢献ガイドラインをご覧ください。
既にOpenai APIを使用するアプリケーションがある場合は、デフォルトの構成を使用して、APIエンドポイントをhttp://host:port/v1に変更するだけでキャノピーに移行できます。
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )チャットに特定のインデックスネームスペースを使用する場合は、APIエンドポイントに名前空間を追加するだけです。
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" )Canopyは、FastapiをWebフレームワークとして、UvicornをASGIサーバーとして使用しています。
生産にキャノピーを使用するには、Productionのニーズに合わせてGitHubパッケージで利用できるCanopyのDocker画像を利用することをお勧めします。
Google Cloudプラットフォーム(GCP)にキャノピーの展開に関するガイダンスについては、GCPドキュメントへの展開で提供されている例を参照してください。
または、GunicornをプロダクショングレードのWSGIとして使用することもできます。詳細については、こちらをご覧ください。
目的のPORTとWORKER_COUNT envrionment変数を設定し、以下でサーバーを開始します。
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT 重要
サーバーは、独自の認証資格情報を使用して、PineconeやOpenaiなどのサービスと対話します。サーバーをパブリックWebホスティングプロバイダーに展開する場合、認証メカニズムを有効にすることをお勧めします。これにより、サーバーは認証されたユーザーからのみリクエストを実行します。


