canopy
0.9.0
Observação
A equipe do dossel não está mais mantendo esse repositório. Obrigado pelo seu apoio e entusiasmo pelo projeto! Se você está procurando uma solução de pano gerenciado de alta qualidade com atualizações e melhorias contínuas, consulte o Assistente do Pinecone.
O Canopy é uma estrutura de geração aumentada de recuperação de código aberto (RAG) e mecanismo de contexto construído sobre o banco de dados do vetor de pinecone. O Canopy permite que você experimente e construa de maneira rápida e facilmente aplicativos usando RAG. Comece a conversar com seus documentos ou dados de texto com alguns comandos simples.
O Canopy assume o levantamento pesado para a criação de aplicações de pano de criação: desde a crise e a incorporação de seus dados de texto para o gerenciamento de histórico de bate -papo, otimização de consultas, recuperação de contexto (incluindo engenharia imediata) e geração aumentada.
A Canopy fornece um servidor interno configurável para que você possa implantar sem esforço um aplicativo de bate-papo movido a RAG na sua interface ou interface de bate-papo existente. Ou você pode construir seu próprio aplicativo RAG personalizado usando a Biblioteca Canopy.
O Canopy permite avaliar seu fluxo de trabalho de pano com uma ferramenta de bate -papo baseada em CLI. Com um comando simples na CLI do dossel, você pode conversar interativamente com seus dados de texto e comparar os fluxos de trabalho RAG vs. não RAG lado a lado.
Confira nossa postagem no blog para saber mais ou ver um tutorial rápido aqui.
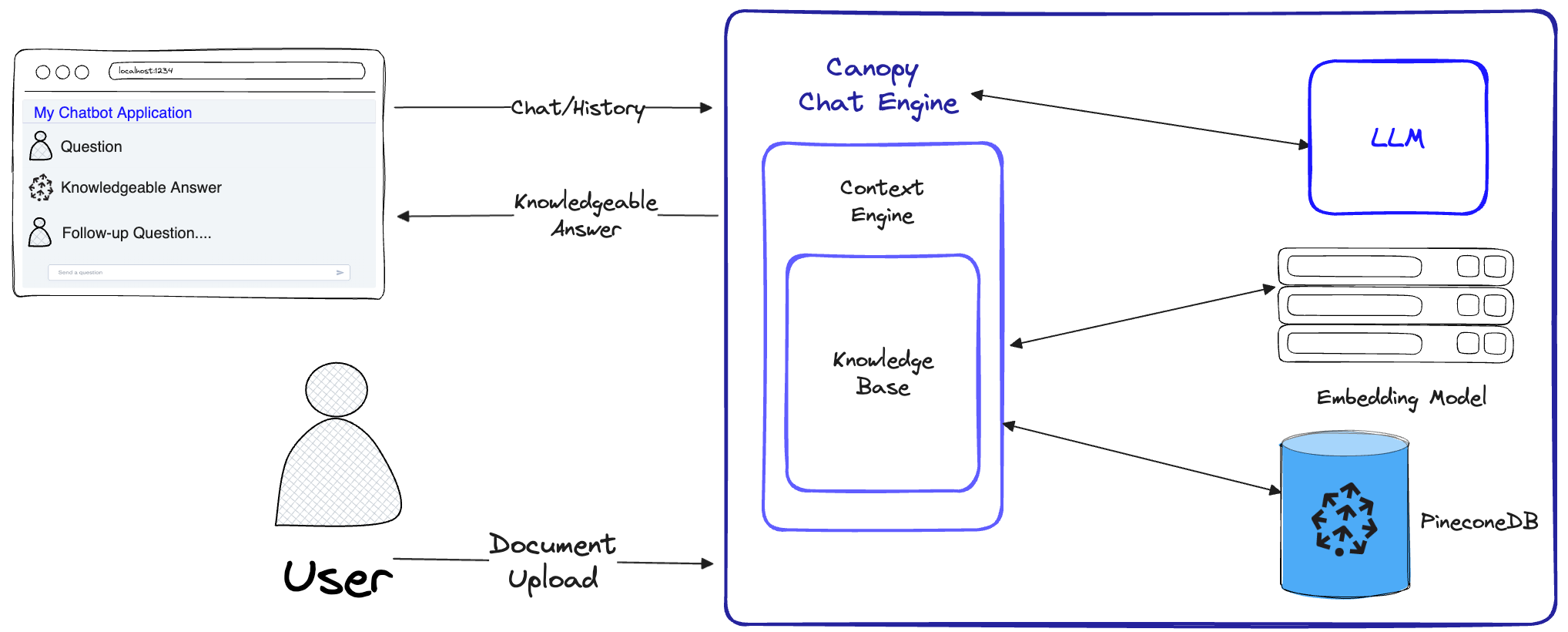
O Canopy implementa o fluxo de trabalho completo do RAG para evitar alucinações e aumentar seu LLM com seus próprios dados de texto.
O Canopy tem dois fluxos: criação e bate -papo da base de conhecimento. No fluxo de criação da base de conhecimento, os usuários carregam seus documentos e os transformam em representações significativas armazenadas no banco de dados vetorial da Pinecone. No fluxo de bate -papo, as consultas de entrada e o histórico de bate -papo são otimizadas para recuperar os documentos mais relevantes, a base de conhecimento é consultada e um contexto significativo é gerado para o LLM responder.
ChatEngine formula consultas relevantes para o ContextEngine e usa o LLM para gerar uma resposta experiente.ContextEngine utiliza a KnowledgeBase subjacente para recuperar os documentos mais relevantes e, em seguida, formula um contexto textual coerente a ser usado como um prompt para o LLM.Mais informações sobre o uso da biblioteca principal podem ser encontradas na documentação da biblioteca
Canopy Server - este é um serviço da web que envolve a biblioteca do Canopy Core e a expõe como uma API REST. O servidor é construído sobre o FASTAPI, UVICORN e Gunicorn e pode ser facilmente implantado na produção. O servidor também vem com uma interface do usuário de swagger embutida para facilitar testes e documentação. Depois de iniciar o servidor, você pode acessar a interface do usuário do Swagger em http://host:port/docs (padrão: http://localhost:8000/docs )
CLI CLI - uma ferramenta de desenvolvimento interna que permite que os usuários configurem rapidamente seu próprio servidor de dossel e testem sua configuração.
Com apenas três comandos da CLI, você pode criar um novo servidor dossel, fazer upload de seus documentos e interagir com o chatbot usando um aplicativo de bate-papo interno diretamente do terminal. O chatbot embutido também permite a comparação de respostas com infusão de pano contra um chatbot nativo do LLM.
python3 -m venv canopy-env
source canopy-env/bin/activateMais informações sobre ambientes virtuais podem ser encontrados aqui
pip install canopy-sdk| Nome | Descrição |
|---|---|
grpc | Para desbloquear algumas melhorias de desempenho trabalhando com a versão GRPC do cliente Pinecone |
torch | Para permitir incorporações fornecidas por transformadores de frases |
transformers | Se você estiver usando o AnyScale LLMS, é recomendável usar o tokenizador LLamaTokenizer , que requer transformadores como dependência |
cohere | Para usar o coere reranker ou/e coere llm |
qdrant | Para usar o QDRANT como uma base de conhecimento alternativa |
export PINECONE_API_KEY= " <PINECONE_API_KEY> "
export OPENAI_API_KEY= " <OPENAI_API_KEY> "
export INDEX_NAME= " <INDEX_NAME> "| Nome | Descrição | Como obtê -lo? |
|---|---|---|
PINECONE_API_KEY | A chave da API para Pinecone. Usado para autenticar os serviços Pinecone para criar índices e inserir, excluir e pesquisar dados | Registre -se ou faça login na sua conta Pinecone no console. Você pode acessar sua tecla API na seção "API Keys" na barra lateral do seu painel |
OPENAI_API_KEY | Chave da API para OpenAI. Usado para autenticar os serviços do OpenAI para incorporação e API de bate -papo | Você pode encontrar sua chave de API do OpenAI aqui. Pode ser necessário fazer login ou registrar -se nos serviços OpenAI |
INDEX_NAME | Nome do Pinecone Index Canopy subjacente ao trabalho com | Você pode escolher qualquer nome, desde que siga as restrições de Pinecone |
CANOPY_CONFIG_FILE | O caminho de um arquivo YAML de configuração a ser usado pelo servidor dossel. | Opcional - se não for fornecido, a configuração padrão seria usada |
Essas variáveis de ambiente opcionais são usadas para se autenticar para outros serviços suportados para incorporação e LLMS. Se você configurar o dossel para usar qualquer um desses fornecedores - precisará definir as variáveis de ambiente relevantes.
| Nome | Descrição | Como obtê -lo? |
|---|---|---|
ANYSCALE_API_KEY | Chave da API para qualquer escala. Usado para autenticar em qualquer ponto de extremidade de escala para o Open Source LLMS | Você pode registrar pontos de extremidade de qualquer escala e encontrar sua chave da API aqui |
CO_API_KEY | Chave da API para coere. Usado para autenticar para coerenciar os serviços para incorporar | Você pode encontrar mais informações sobre como se registrar para coar aqui |
JINA_API_KEY | Chave da API para Jina AI. Usado para autenticar os serviços de Jinaai para incorporar e bate -papo API | Você pode encontrar sua chave de API do OpenAI aqui. Pode ser necessário fazer login ou registrar -se nos serviços OpenAI |
AZURE_OPENAI_ENDOINT | O URL do terminal do Azure OpenAi que você implantou. | Você pode encontrar isso no portal do Azure Openai sob _keys and endpoints` |
AZURE_OPENAI_API_KEY | A chave da API a ser usada para os seus modelos do Azure Openai. | Você pode encontrar isso no portal do Azure Openai sob _keys and endpoints` |
OCTOAI_API_KEY | Chave da API para Octoai. Usado para autenticar para o Open Source LLMS servido em outubroi | Você pode se inscrever no Octoai e encontrar sua chave da API aqui |
canopyA saída deve ser semelhante a isso:
Canopy: Ready
Usage: canopy [OPTIONS] COMMAND [ARGS]...
# rest of the help message Neste Quickstart, mostraremos como usar o dossel para criar um sistema de resposta a perguntas simples usando RAG (geração aumentada de recuperação).
Como uma configuração única, o Canopy precisa criar um novo índice de Pinecone que esteja configurado para trabalhar com o dossel, basta executar:
canopy new E siga as instruções da CLI. O índice que será criado terá um canopy--<INDEX_NAME> .
Você só precisa fazer esse processo uma vez para cada índice de dossel que deseja criar.
Para saber mais sobre os índices Pinecone e como gerenciá -los, consulte o seguinte guia: Entendendo os índices
Você pode carregar dados no seu índice de dossel usando o comando:
canopy upsert /path/to/data_directory
# or
canopy upsert /path/to/data_directory/file.parquet
# or
canopy upsert /path/to/data_directory/file.jsonl
# or
canopy upsert /path/to/directory_of_txt_files/
# ... O Canopy suporta arquivos nos formatos jsonl , parquet e csv . Além disso, você pode carregar arquivos de dados de texto simples no formato .txt . Nesse caso, cada arquivo será tratado como um único documento. O ID do documento será o nome do arquivo e a fonte será o caminho completo do arquivo.
NOTA : Os campos de documentos são usados no fluxo de pano e devem cumprir o seguinte esquema:
+----------+--------------+--------------+---------------+
| id(str) | text(str) | source | metadata |
| | | Optional[str] | Optional[dict] |
| ----------+--------------+--------------+--------------- |
| " id1 " | " some text " | " some source " | { " key " : " val " } |
+----------+--------------+--------------+---------------+
# id - unique identifier for the document
#
# text - the text of the document, in utf-8 encoding.
#
# source - the source of the document, can be any string, or null.
# ** this will be used as a reference in the generated context. **
#
# metadata - optional metadata for the document, for filtering or additional context.
# Dict[str, Union[str, int, float, List[str]]]Este notebook mostra como você cria um conjunto de dados neste formato, siga as instruções na CLI ao enviar seus dados.
Dica
Se você deseja separar seus dados em namespaces, pode usar a opção --namespace ou a variável de ambiente INDEX_NAMESPACE .
O servidor Canopy expõe a funcionalidade do Canopy por meio de uma API REST. Ou seja, ele permite fazer upload de documentos, recuperar documentos relevantes para uma determinada consulta e conversar com seus dados. O servidor expõe um terminal de appletion /chat.completion que pode ser facilmente integrado a qualquer aplicativo de bate -papo. Para iniciar o servidor, execute:
canopy startAgora, você deve ser solicitado com a seguinte mensagem padrão Uvicorn:
...
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
É isso! Agora você pode começar a usar o servidor Canopy com qualquer aplicativo de bate -papo que suporta um terminal de A /chat.completion .
O comando Start Canopy manterá o terminal ocupado (uso recomendado). Se você deseja executar o servidor em segundo plano, pode usar o seguinte comando -
nohup canopy start &
Para parar o servidor, basta pressionar CTRL+C no terminal onde você o iniciou.
O CLI do Canopy vem com um aplicativo de bate-papo embutido que permite que você converse interativamente com seus dados de texto e compare os fluxos de trabalho RAG vs. não RAG lado a lado para avaliar os resultados
Em uma nova janela do terminal, defina as variáveis de ambiente necessárias e execute:
canopy chatIsso abrirá uma interface de bate -papo no seu terminal. Você pode fazer perguntas e o chatbot com infusão de pano tentará respondê-las usando os dados que você carregou.
Para comparar a resposta de bate-papo com e sem pano, use a bandeira --no-rag
Nota : Este método é suportado apenas com o OpenAI no momento.
canopy chat --no-ragIsso abrirá uma janela de interface de bate-papo semelhante, mas mostrará as respostas RAG e não RAG lado a lado.
Obrigado por considerar contribuir para o Canopy! Consulte nossas diretrizes contribuintes para obter mais informações.
Se você já possui um aplicativo que usa a API OpenAI, pode migrá -lo para o dossel simplesmente alterando o endpoint da API para http://host:port/v1 , por exemplo, com a configuração padrão:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" )Se você deseja usar um espaço de nome de índice específico para conversar, você pode apenas anexar o espaço para nome ao endpoint da API:
from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1/my-namespace" ) O Canopy está usando o FASTAPI como estrutura da Web e Uvicorn como o servidor ASGI.
Para usar o dossel na produção, é recomendável utilizar a imagem do Docker do Canopy, disponível nos pacotes do Github, para suas necessidades de produção.
Para obter orientações sobre a implantação do dossel na plataforma do Google Cloud (GCP), consulte o exemplo fornecido na implantação na documentação do GCP.
Como alternativa, você pode usar o Gunicorn como WSGI de grau de produção, mais detalhes aqui.
Defina as variáveis desejadas PORT e WORKER_COUNT .
gunicorn canopy_server.app:app --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0: $PORT --workers $WORKER_COUNT Importante
O servidor interage com serviços como Pinecone e OpenAI, usando suas próprias credenciais de autenticação. Ao implantar o servidor em um provedor de hospedagem pública da Web, recomenda -se ativar um mecanismo de autenticação, para que seu servidor apenas aceitasse solicitações de usuários autenticados.


