clifs
1.0.0
CLIF是通过视频搜索带有匹配内容的视频帧的免费文本概念验证。这是使用OpenAI的剪辑模型完成的,该模型经过训练,可以与相应的字幕匹配图像,反之亦然。搜索是通过首先使用剪辑图像编码从视频帧中提取功能,然后通过剪辑文本编码来获取搜索查询的功能来完成的。然后,如果超过设定的阈值,则功能与相似性匹配,并返回顶部结果。
为了轻松使用CLIFS后端,使用运行Django的简单Web服务器为搜索引擎提供接口。
为了了解该模型的能力,下面显示了一些示例,其中搜索查询为粗体,结果以下结果。这些搜索查询是根据UrbanTracker数据集的2分钟Sherbrooke视频进行的。仅显示每个查询的顶部图像结果。请注意,该模型实际上具有OCR。



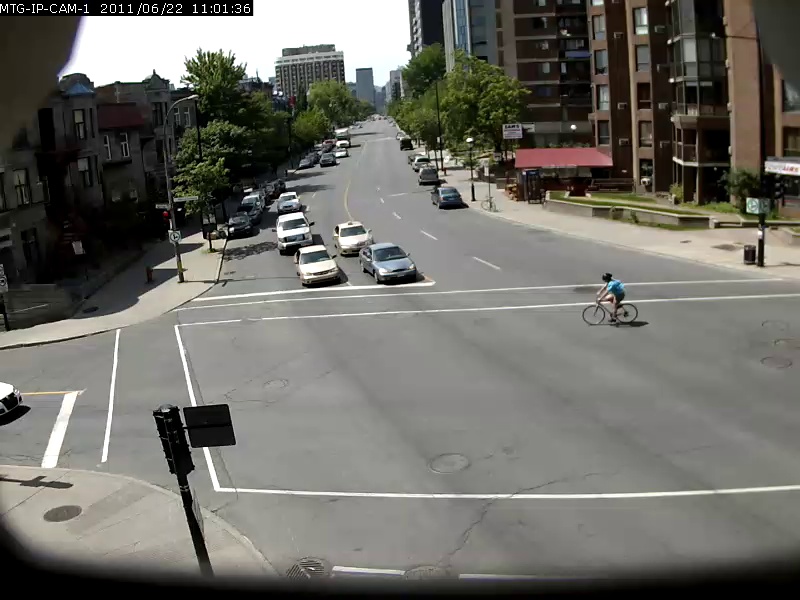
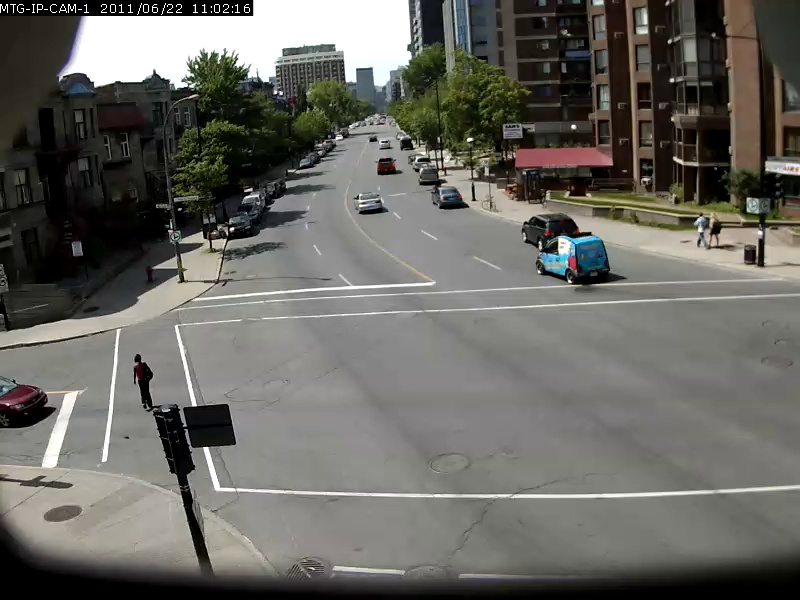
./setup.sh将自己要在data/input目录中索引的视频文件
通过Docker-Compose构建并启动搜索引擎和Web服务器容器:
docker-compose build && docker-compose up可选地,如果主机环境具有NVIDIA GPU,可以使用带有GPU支持的Docker-Compose文件,并且已设置用于Docker GPU支持:
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input目录中的文件的功能进行编码,如日志所示,请导航至127.0.0.1:8000并搜索。

