clifs
1.0.0
CLIFS เป็นข้อพิสูจน์แนวคิดสำหรับการค้นหาข้อความฟรีผ่านวิดีโอสำหรับเฟรมวิดีโอที่มีเนื้อหาที่ตรงกัน สิ่งนี้ทำโดยใช้โมเดลคลิปของ OpenAI ซึ่งได้รับการฝึกฝนให้จับคู่ภาพกับคำบรรยายภาพที่สอดคล้องกันและในทางกลับกัน การค้นหาทำได้โดยการแยกคุณสมบัติแรกจากเฟรมวิดีโอโดยใช้ตัวเข้ารหัสภาพคลิปจากนั้นรับคุณสมบัติสำหรับการค้นหาผ่านตัวเข้ารหัสข้อความคลิป จากนั้นคุณสมบัติจะถูกจับคู่โดยความคล้ายคลึงกันและผลลัพธ์ด้านบนจะถูกส่งคืนหากเหนือเกณฑ์ที่กำหนดไว้
เพื่อให้สามารถใช้งานแบ็กเอนด์ CLIFS ได้อย่างง่ายดายเว็บเซิร์ฟเวอร์ที่ใช้งานได้อย่างง่าย ๆ จะใช้ Django เพื่อให้อินเทอร์เฟซกับเครื่องมือค้นหา
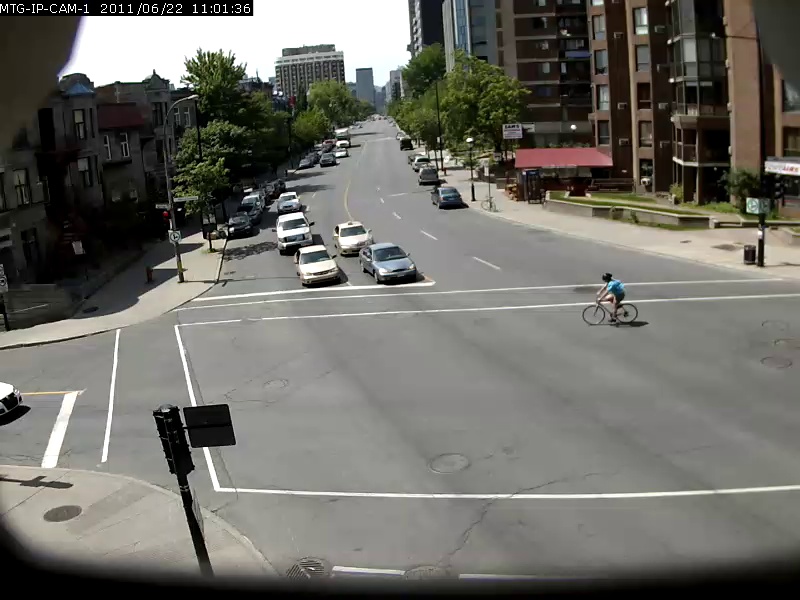
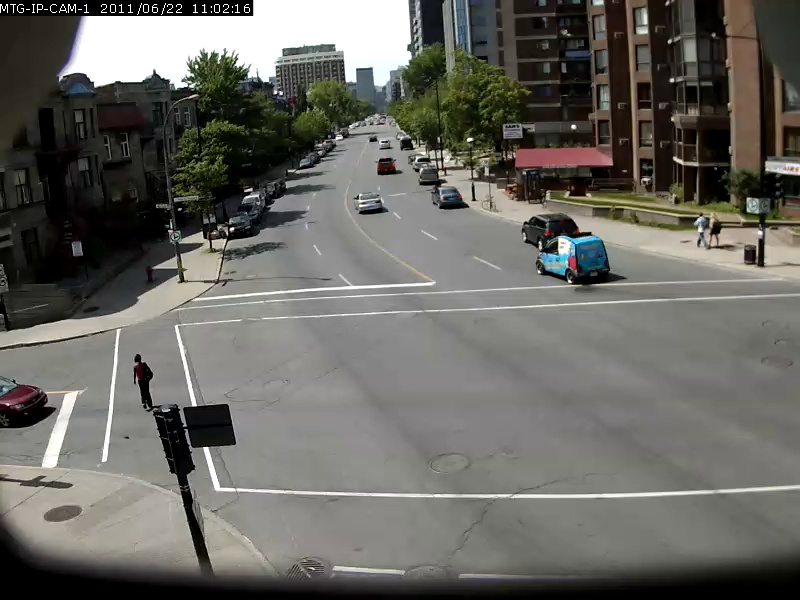
เพื่อให้ทราบถึงความสามารถของโมเดลนี้ตัวอย่างบางส่วนจะแสดงอยู่ด้านล่างโดยมีการค้นหาเป็นตัวหนาและผลลัพธ์ด้านล่าง คำค้นหาการค้นหาเหล่านี้ทำกับวิดีโอ Sherbrooke 2 นาทีจากชุดข้อมูล Urbuntracker เฉพาะผลลัพธ์ภาพด้านบนสำหรับแต่ละแบบสอบถามเท่านั้น โปรดทราบว่าแบบจำลองนั้นค่อนข้างสามารถใช้ OCR ได้



./setup.sh ใส่ไฟล์วิดีโอของคุณเองที่คุณต้องการจัดทำดัชนีในไดเรกทอรี data/input
สร้างและสตาร์ทคอนเทนเนอร์ค้นหาและเว็บเซิร์ฟเวอร์ผ่าน Docker-compose:
docker-compose build && docker-compose upเป็นทางเลือกไฟล์ Docker-compose ที่มีการสนับสนุน GPU สามารถใช้งานได้หากสภาพแวดล้อมโฮสต์มี Nvidia GPU และตั้งค่าสำหรับการสนับสนุน Docker GPU:
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input ได้รับการเข้ารหัสดังที่แสดงในบันทึกนำไปที่ 127.0.0.1:8000 และค้นหา

