clifs
1.0.0
CLIFS est une preuve de concept pour la recherche de texte libre via des vidéos des trames vidéo avec un contenu correspondant. Cela se fait à l'aide du modèle de clip d'Openai, qui est formé pour faire correspondre les images avec les légendes correspondantes et vice versa. La recherche est effectuée en extrayant d'abord des fonctionnalités des trames vidéo à l'aide du codeur d'image de clip, puis en obtenant les fonctionnalités de la requête de recherche via l'encodeur de texte clip. Les fonctionnalités sont ensuite appariées par la similitude et les résultats supérieurs sont renvoyés, si vous êtes au-dessus d'un seuil défini.
Pour permettre une utilisation facile du backend CLIFS, un serveur Web simple exécutant Django est utilisé pour fournir une interface au moteur de recherche.
Pour donner une idée de la capacité de ce modèle, quelques exemples sont présentés ci-dessous, avec la requête de recherche en gras et le résultat ci-dessous. Ces requêtes de recherche sont effectuées contre la vidéo Sherbrooke de 2 minutes de l'ensemble de données UrbanTracker. Seul le résultat de l'image supérieure pour chaque requête est affiché. Notez que le modèle est en fait tout à fait capable d'OCR.



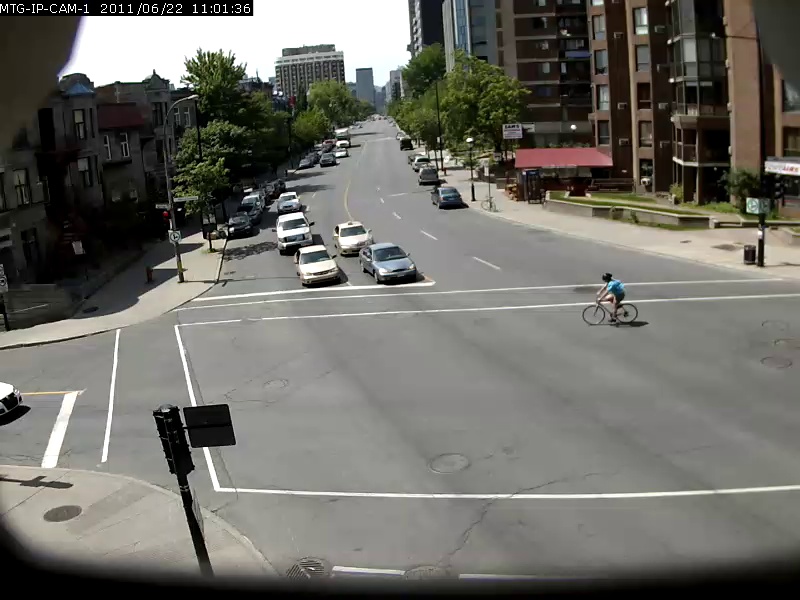
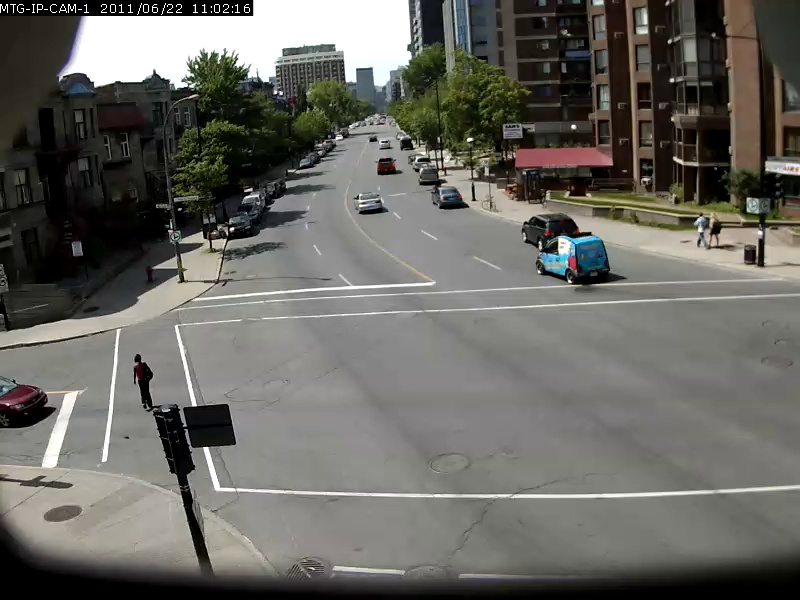
./setup.sh Mettez vos propres fichiers vidéo que vous souhaitez indexer dans le répertoire data/input
Créer et démarrer le moteur de recherche et les conteneurs de serveurs Web via Docker-Compose:
docker-compose build && docker-compose upFacultativement, un fichier Docker-Compose avec le support GPU peut être utilisé si l'environnement hôte a un GPU NVIDIA et est configuré pour le support GPU Docker:
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input ont été encodées, comme indiqué dans le journal, accédez à 127.0.0.1:8000 et recherchez.

