clifs
1.0.0
O CLIFS é uma prova de conceito para o texto gratuito pesquisando em vídeos por quadros de vídeo com conteúdo correspondente. Isso é feito usando o modelo de clipe do OpenAI, que é treinado para combinar imagens com as legendas correspondentes e vice -versa. A pesquisa é feita pela primeira extração de recursos de quadros de vídeo usando o codificador de imagem de clipe e, em seguida, obtendo os recursos da consulta de pesquisa através do codificador de texto do clipe. Os recursos são então correspondidos pela similaridade e os resultados superiores são retornados, se acima de um limite definido.
Para permitir o uso fácil do back -end do CLIFS, um servidor da web simples executando o Django é usado para fornecer uma interface ao mecanismo de pesquisa.
Para dar uma idéia da capacidade desse modelo, alguns exemplos são mostrados abaixo, com a consulta de pesquisa em negrito e o resultado abaixo. Essas consultas de pesquisa são feitas contra o vídeo Sherbrooke de 2 minutos do conjunto de dados UrbanTracker. Somente o resultado da imagem superior para cada consulta é mostrado. Observe que o modelo é de fato bastante capaz de OCR.



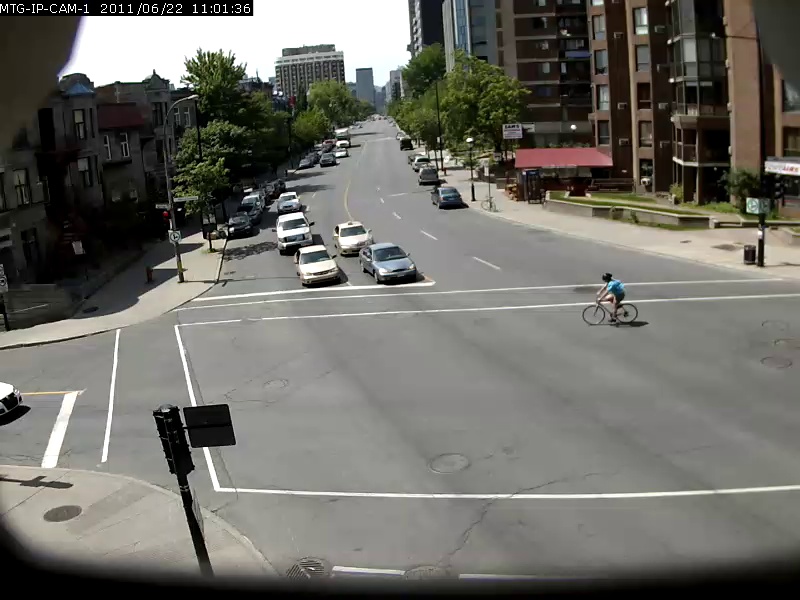
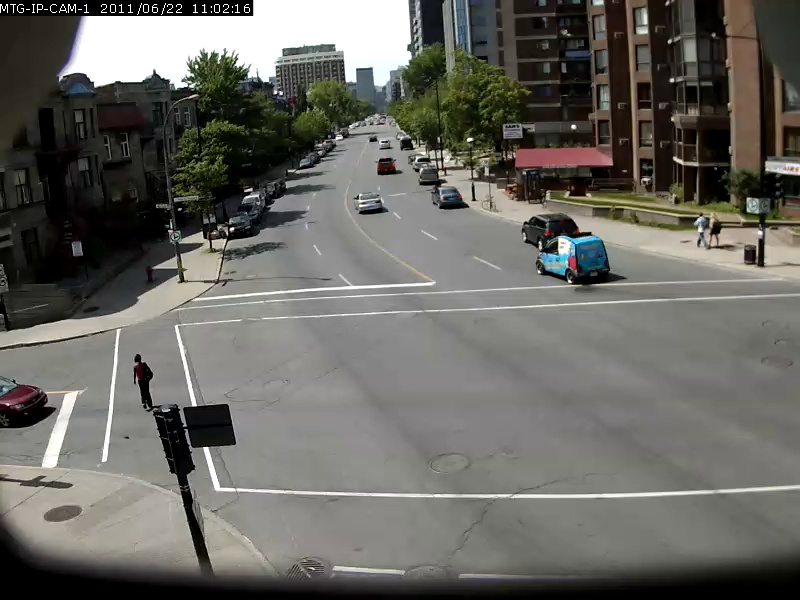
./setup.sh Coloque seus próprios arquivos de vídeo que você deseja indexar no diretório data/input
Crie e inicie o mecanismo de pesquisa e os contêineres do servidor da web através do Docker-CompomPe:
docker-compose build && docker-compose upOpcionalmente, um arquivo do Docker-Compose com suporte à GPU pode ser usado se o ambiente do host tiver uma GPU da NVIDIA e estiver configurada para o suporte à GPU do Docker:
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input forem codificados, conforme mostrado no log, navegue para 127.0.1:8000 e pesquise.

