clifs
1.0.0
CLIFS es una prueba de concepto para la búsqueda de texto gratuito a través de videos para marcos de video con contenido coincidente. Esto se realiza utilizando el modelo Clip de OpenAI, que está entrenado para coincidir con las imágenes con los subtítulos y viceversa correspondientes. La búsqueda se realiza primero extrayendo características de los marcos de video utilizando el codificador de imagen de clip y luego obteniendo las características de la consulta de búsqueda a través del codificador de texto del clip. Las características se combinan con similitud y los resultados superiores se devuelven, si están por encima de un umbral establecido.
Para permitir un uso fácil del backend de CLIFS, se utiliza un servidor web simple que ejecuta Django para proporcionar una interfaz al motor de búsqueda.
Para dar una idea de la capacidad de este modelo, algunos ejemplos se muestran a continuación, con la consulta de búsqueda en negrita y el resultado a continuación. Estas consultas de búsqueda se realizan contra el video de Sherbrooke de 2 minutos desde el conjunto de datos UrbanTracker. Solo se muestra el resultado de la imagen superior para cada consulta. Tenga en cuenta que el modelo es de hecho bastante capaz de OCR.



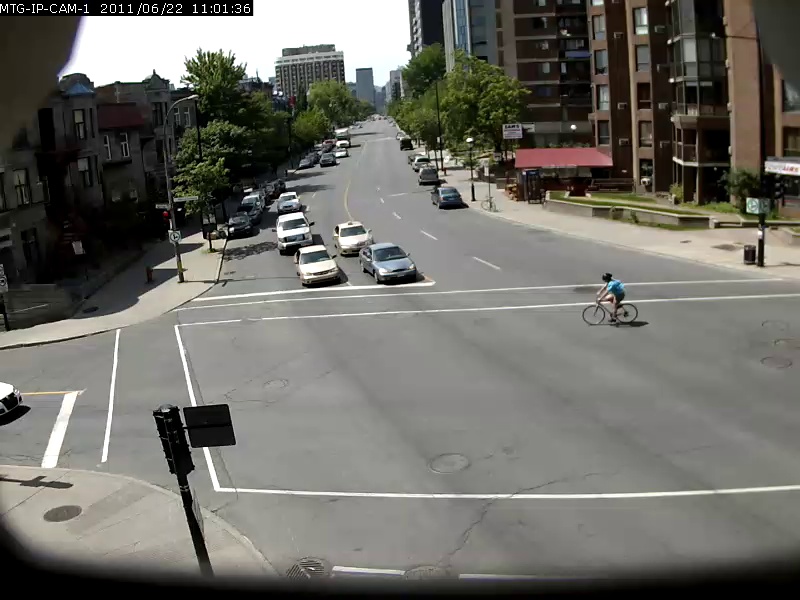
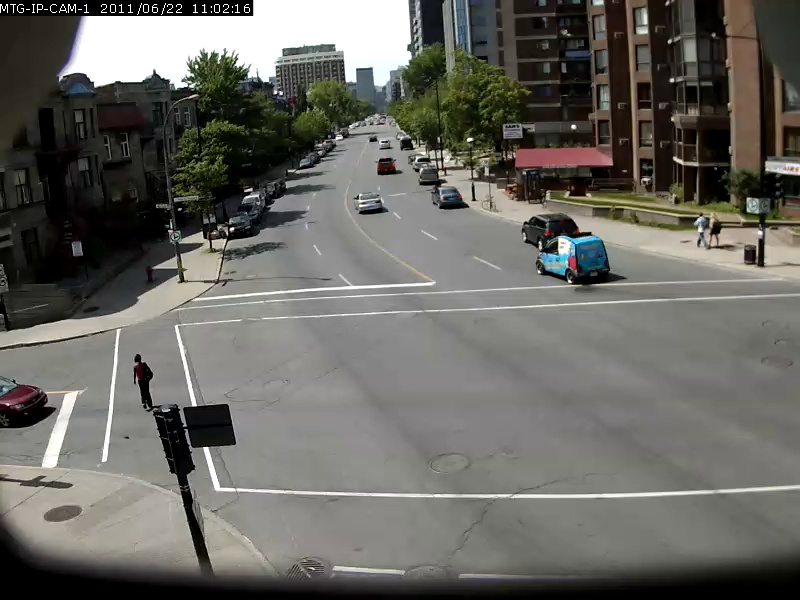
./setup.sh Pon sus propios archivos de video que desea indexar en el directorio data/input
Construya e inicie el motor de búsqueda y los contenedores del servidor web a través de Docker-Compose:
docker-compose build && docker-compose upOpcionalmente, se puede utilizar un archivo Docker-Compose con soporte de GPU si el entorno de host tiene una GPU NVIDIA y está configurada para el soporte de GPU de Docker:
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input , como se muestra en el registro, navegue a 127.0.0.1:8000 y busque.

