clifs
1.0.0
Clifs는 내용이 일치하는 비디오 프레임에 대한 비디오를 통해 무료 텍스트 검색을위한 개념 증명입니다. 이것은 이미지를 해당 캡션과 일치시키고 그 반대를 일치하도록 훈련 된 OpenAI의 클립 모델을 사용하여 수행됩니다. 검색은 클립 이미지 인코더를 사용하여 비디오 프레임에서 기능을 먼저 추출한 다음 클립 텍스트 인코더를 통해 검색 쿼리 기능을 얻음으로써 수행됩니다. 그런 다음 기능은 유사성과 일치하며 설정 임계 값 위에있는 경우 상단 결과가 반환됩니다.
Clifs 백엔드를 쉽게 사용할 수 있도록 Django를 실행하는 간단한 웹 서버는 검색 엔진에 대한 인터페이스를 제공하는 데 사용됩니다.
이 모델의 기능에 대한 아이디어를 제공하기 위해 검색 쿼리와 아래의 결과와 함께 몇 가지 예가 아래에 나와 있습니다. 이러한 검색 쿼리는 UrbanTracker 데이터 세트의 2 분 Sherbrooke 비디오에 대해 수행됩니다. 각 쿼리의 상단 이미지 결과 만 표시됩니다. 이 모델은 실제로 OCR이 가능합니다.



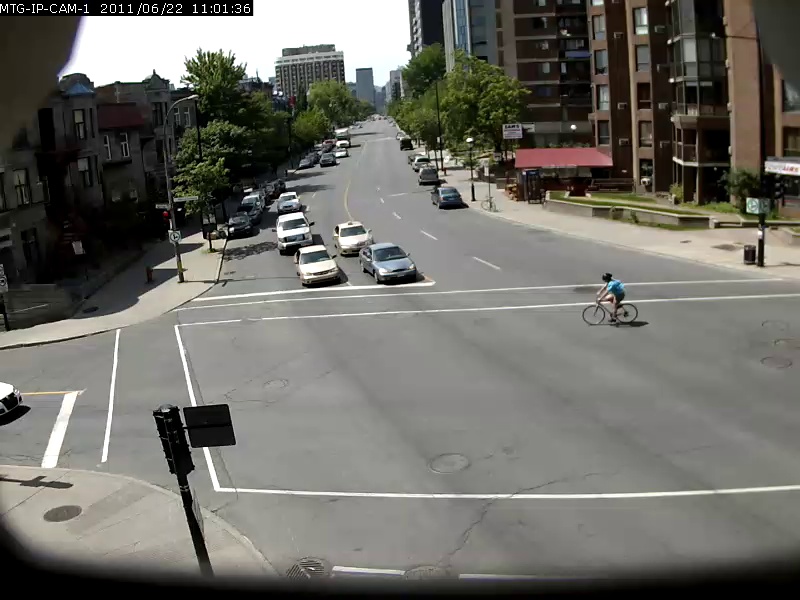
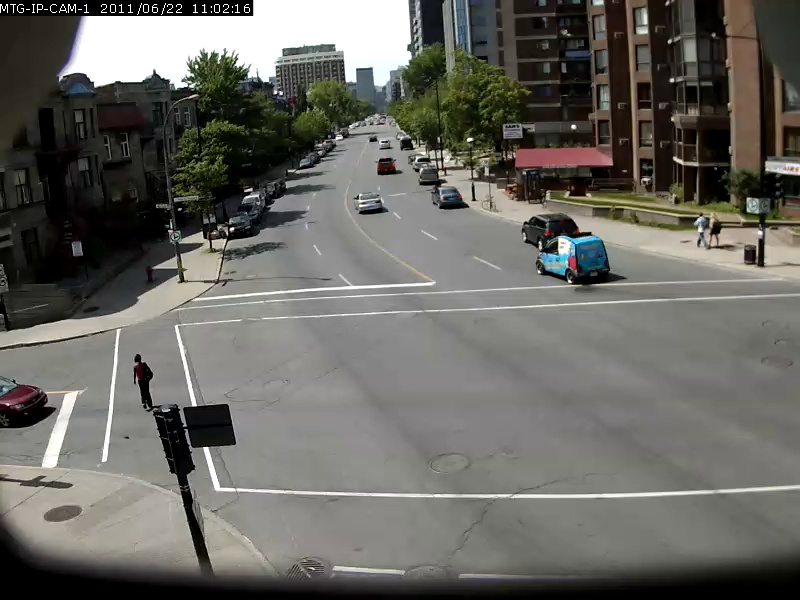
./setup.sh data/input 디렉토리에 인덱싱하려는 나만의 비디오 파일을 넣으십시오.
Docker-Compose를 통해 검색 엔진 및 웹 서버 컨테이너를 구축하고 시작하십시오.
docker-compose build && docker-compose up선택적으로 호스트 환경에 NVIDIA GPU가 있고 Docker GPU 지원을위한 설정인 경우 GPU 지원이있는 Docker-Compose 파일을 사용할 수 있습니다.
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input 디렉토리의 파일의 기능이 인코딩되면 127.0.0.1:8000으로 이동하여 검색하십시오.

