clifs
1.0.0
CLIFS ist ein Proof-of-Concept-für kostenlose Text, der Videos nach Videobildern mit passenden Inhalten durchsucht. Dies geschieht mithilfe von OpenAIs Clip -Modell, das so geschult wird, dass sie Bilder mit den entsprechenden Bildunterschriften übereinstimmen und umgekehrt. Die Suche wird durchgeführt, indem zuerst Funktionen aus Videorahmen mit dem Clip -Bild -Encoder extrahiert und dann die Funktionen für die Suchabfrage über den Clip -Text -Encoder abgerufen werden. Die Funktionen werden dann mit Ähnlichkeit übereinstimmen und die Top -Ergebnisse werden zurückgegeben, falls über einem festgelegten Schwellenwert.
Um das CLIFS -Backend eine einfache Verwendung zu ermöglichen, wird ein einfacher Webserver mit Django verwendet, um eine Schnittstelle zur Suchmaschine bereitzustellen.
Um eine Vorstellung von der Fähigkeit dieses Modells zu geben, werden unten einige Beispiele angezeigt, wobei die Suchabfrage fett und das Ergebnis unten ist. Diese Suchanfragen werden gegen das 2 -minütige Sherbrooke -Video aus dem UrbanTracker -Datensatz durchgeführt. Es wird nur das Top -Bild -Ergebnis für jede Abfrage angezeigt. Beachten Sie, dass das Modell in der Tat durch OCR in der Lage ist.



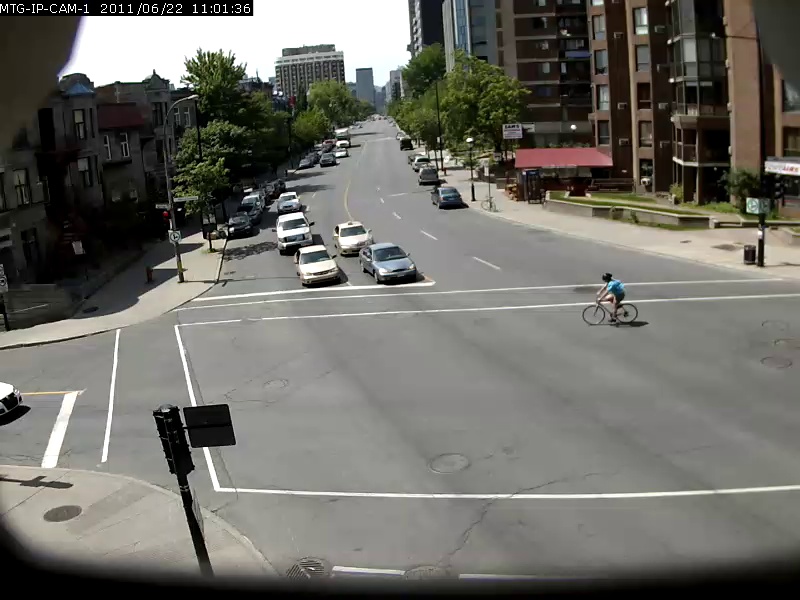
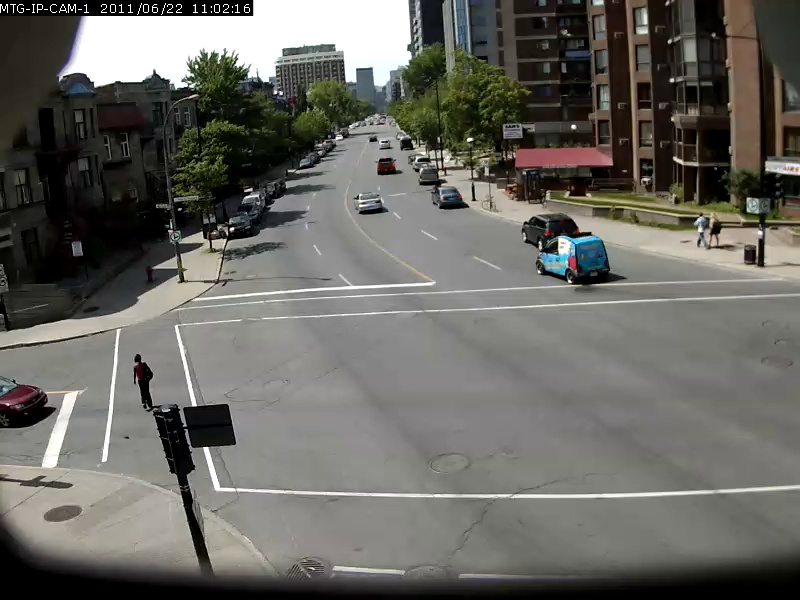
./setup.sh Setzen Sie Ihre eigenen Videodateien ein, die Sie in das data/input indexieren möchten
Erstellen und starten Sie die Suchmaschinen- und Webserver-Container über Docker-Compose:
docker-compose build && docker-compose upOptional kann eine Docker-Compose-Datei mit GPU-Unterstützung verwendet werden, wenn die Hostumgebung über eine NVIDIA-GPU verfügt und für die Docker-GPU-Unterstützung eingerichtet ist:
docker-compose build && docker-compose -f docker-compose-gpu.yml updata/input codiert wurden, wie im Protokoll gezeigt, navigieren Sie zu 127.0.0.1:8000 und suchen Sie weg.

