Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
โครงการนี้สำรวจการจำแนกประเภทข้อความอารมณ์โดยใช้โมเดล LLAMA3-8B ซึ่งได้รับการปรับปรุงด้วยเทคนิค LORA และ Flashattention แบบจำลองได้รับการปรับให้เหมาะสมสำหรับการระบุประเภทอารมณ์หกประเภท: ความสุขความโศกเศร้าความโกรธความกลัวความรักและความประหลาดใจ โมเดล LLAMA3-8B แสดงให้เห็นถึงประสิทธิภาพที่เหนือกว่าด้วยความแม่นยำ 0.9262 ซึ่งเหนือกว่ารุ่นหม้อแปลงอื่น ๆ เช่น Bert-Base, Bert-Large, Roberta-Base และ Roberta-Large
การประมวลผลภาษาธรรมชาติ (NLP) ได้กลายเป็นพื้นที่โฟกัสที่สำคัญสำหรับการวิเคราะห์ความเชื่อมั่นหรือที่เรียกว่าการจำแนกความเชื่อมั่นหรือการตรวจจับความเชื่อมั่น เทคโนโลยีนี้ช่วยให้ธุรกิจเข้าใจอารมณ์และความคิดเห็นของผู้บริโภคเพิ่มความพึงพอใจของลูกค้าและการพัฒนาผลิตภัณฑ์ ข้อมูลจำนวนมากใน บริษัท ขนาดใหญ่ทำให้การวิเคราะห์ด้วยตนเองไม่สามารถทำได้นำไปสู่การยอมรับอัลกอริทึม AI และ NLP
โมเดล LLAMA3-8B ที่พัฒนาโดย Meta AI เป็นรูปแบบภาษาขนาดใหญ่ที่ได้รับการปรับให้เหมาะสมสำหรับกรณีการใช้งานบทสนทนา มันมีพารามิเตอร์ 8 พันล้านพารามิเตอร์และคุณสมบัติการปรับปรุงที่สำคัญมากกว่ารุ่นก่อนหน้า ซีรี่ส์ LLAMA3 รวมกระบวนการฝึกอบรมหลายเฟสซึ่งรวมถึงการปรับแต่งการปรับแต่งการปรับแต่งและการปรับแต่งซ้ำ ๆ โดยใช้การเรียนรู้การเสริมแรงด้วยความคิดเห็นของมนุษย์ (RLHF) กระบวนการนี้ช่วยให้มั่นใจได้ว่าแบบจำลองจะสอดคล้องกับความชอบของมนุษย์เพื่อความช่วยเหลือและความปลอดภัย
ความก้าวหน้าทางสถาปัตยกรรมใน LLAMA3 รวมถึงการดำเนินการตามคำถามแบบกลุ่ม (GQA) GQA Clusters Queries เพื่อแบ่งปันคู่คีย์-ค่าซึ่งจะช่วยลดหน่วยความจำและค่าใช้จ่ายในการคำนวณในขณะที่ยังคงประสิทธิภาพสูง วิธีนี้ช่วยเพิ่มประสิทธิภาพของการคำนวณความสนใจอย่างมีนัยสำคัญโดยเฉพาะในแบบจำลองขนาดใหญ่
LLAMA3-8B ได้รับการปรับแต่งในชุดข้อมูลที่หลากหลายซึ่งประกอบด้วยโทเค็นมากกว่า 15 ล้านล้านโทเค็นจากข้อมูลสาธารณะที่เปิดเผยโดยมีการตัดความรู้ของแบบจำลองเมื่อเดือนมีนาคม 2566 ขั้นตอนการปรับจูนใช้ชุดข้อมูลการเรียนการสอนที่เปิดเผยต่อสาธารณชน
| คุณสมบัติ | ข้อมูลจำเพาะ |
|---|---|
| ข้อมูลการฝึกอบรม | ข้อมูลที่เปิดเผยต่อสาธารณะ |
| พารามิเตอร์ | 8B |
| ความยาวบริบท | 8K |
| GQA | ใช่ |
| จำนวนโทเค็น | 15t+ |
| ตัดความรู้ | มีนาคม 2566 |
การเรียนการสอนการปรับแต่งช่วยเพิ่มความสามารถในการเรียนรู้แบบไม่เป็นศูนย์ของโมเดลในงานที่หลากหลาย เทคนิคนี้เกี่ยวข้องกับการฝึกอบรมโมเดลในชุดข้อมูลที่ออกแบบมาโดยเฉพาะเพื่อปรับปรุงความสามารถในการปฏิบัติตามคำแนะนำ ตัวอย่างเช่นโมเดลที่ผ่านการฝึกอบรมเกี่ยวกับชุดข้อมูลเช่น Alpaca-7B สามารถแสดงพฤติกรรมคล้ายกับ Text-DavincI-003 ของ OpenAI ในการทำความเข้าใจและดำเนินการตามคำแนะนำ
LORA (การปรับระดับต่ำ) เป็นเทคนิคที่ใช้ในการรวมเมทริกซ์การสลายตัวของอันดับฝึกอบรมเข้ากับแต่ละชั้นของสถาปัตยกรรมหม้อแปลง วิธีนี้จะช่วยลดจำนวนพารามิเตอร์ที่สามารถฝึกอบรมได้อย่างมีนัยสำคัญในขณะที่ปรับรูปแบบภาษาขนาดใหญ่ให้เข้ากับงานหรือโดเมนที่เฉพาะเจาะจง ซึ่งแตกต่างจากการปรับแต่งแบบเต็มรูปแบบ LORA รักษาน้ำหนักรุ่นที่ผ่านการฝึกฝนไว้ไม่เปลี่ยนแปลงอัปเดตเฉพาะเมทริกซ์ระดับต่ำในระหว่างกระบวนการปรับตัว วิธีการนี้ช่วยเพิ่มประสิทธิภาพการฝึกอบรมลดความต้องการในการจัดเก็บและไม่เพิ่มเวลาแฝงการอนุมานเมื่อเทียบกับแบบจำลองที่ปรับแต่งได้อย่างสมบูรณ์
Flashattention V2 เป็นเทคนิคการเพิ่มประสิทธิภาพที่ออกแบบมาเพื่อเร่งกลไกความสนใจในแบบจำลองหม้อแปลง มันมุ่งเน้นไปที่การปรับปรุงประสิทธิภาพการคำนวณและลดการใช้หน่วยความจำในระหว่างการฝึกอบรม Flashattention ประสบความสำเร็จโดยการทำลายการคำนวณความสนใจเป็นชิ้นเล็ก ๆ ที่จัดการได้มากขึ้นซึ่งจะช่วยเพิ่มการใช้แคชและลดการเข้าถึงหน่วยความจำ นอกจากนี้ยังใช้การดำเนินการเมทริกซ์แบบเบาบางเพื่อใช้ประโยชน์จากกลไกความสนใจซึ่งช่วยหลีกเลี่ยงการคำนวณที่ไม่จำเป็น การดำเนินการ Pipelined ช่วยให้การดำเนินการแบบขนานของขั้นตอนการคำนวณที่แตกต่างกันลดเวลาในการประมวลผลเพิ่มเติม
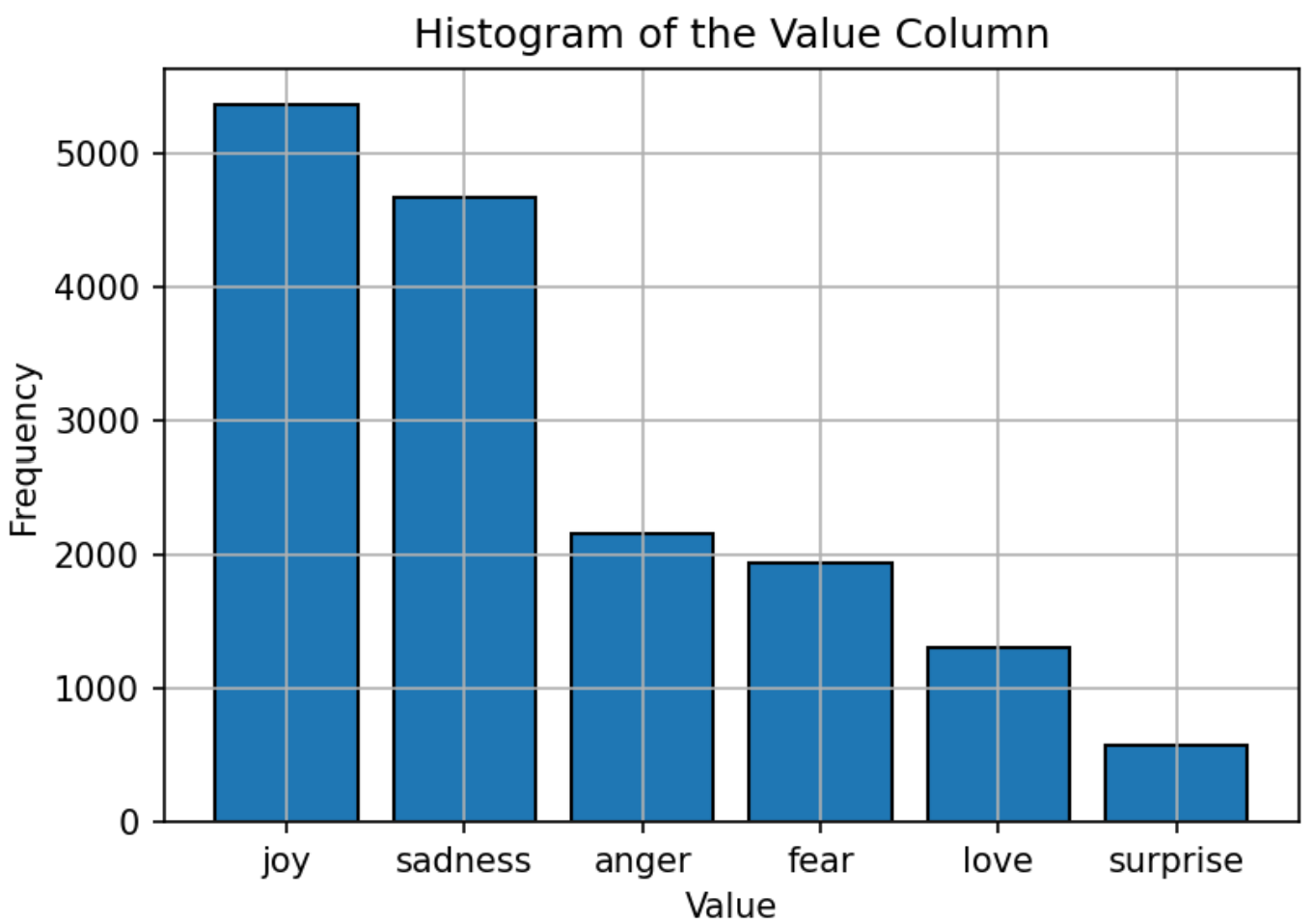
ชุดข้อมูลที่ใช้สำหรับการฝึกอบรมแบบจำลองประกอบด้วยข้อความที่มีอารมณ์หกอารมณ์: ความสุขความโศกเศร้าความโกรธความกลัวความรักและความประหลาดใจ การกระจายของชุดข้อมูลนั้นค่อนข้างสมดุลด้วย "ความสุข" เป็นอารมณ์ที่พบได้บ่อยที่สุดและ "ประหลาดใจ" น้อยที่สุด การกระจายที่สมดุลนี้เป็นรากฐานที่แข็งแกร่งสำหรับแบบจำลองในการจำแนกอารมณ์อย่างแม่นยำโดยไม่มีอคติต่อหมวดหมู่ใด ๆ
พารามิเตอร์ Hyperparameters ของรุ่น LLAMA3-8B ถูกตั้งค่าดังนี้:
| พารามิเตอร์ | การตั้งค่า |
|---|---|
| การเพิ่มประสิทธิภาพ | อดัม |
| อัตราการเรียนรู้ | 5E-5 |
| ขนาดแบทช์ | 5 |
| ยุค | 3 |
| อันดับ Lora | 8 |
| ขั้นตอนการสะสมไล่ระดับสี | 4 |
| ความยาวสูงสุด | 512 |
โมเดลได้รับการฝึกฝนโดยใช้ Adam Optimizer ซึ่งเป็นที่รู้จักกันดีในเรื่องความสามารถในการเรียนรู้ที่ปรับตัวได้ มีการใช้ตารางอัตราการเรียนรู้ของโคไซน์เพื่อปรับอัตราการเรียนรู้ในระหว่างการฝึกอบรม ขนาดแบทช์ถูกตั้งค่าเป็น 5 พร้อมการสะสมการไล่ระดับสีมากกว่า 4 ขั้นตอนเพื่อเพิ่มประสิทธิภาพการใช้หน่วยความจำ โมเดลได้รับการฝึกฝนสำหรับ 3 ยุคด้วยรูปแบบความแม่นยำ FP16 ที่ใช้ในการบันทึกหน่วยความจำ GPU ในขณะที่ยังคงประสิทธิภาพ อันดับ LORA ของ 8 หมายถึงลำดับของเมทริกซ์ระดับต่ำที่ใช้ในกระบวนการปรับตัว
ตัวชี้วัดหลักที่ใช้ในการประเมินประสิทธิภาพของโมเดลคือความแม่นยำ ตัวชี้วัดนี้วัดสัดส่วนของการทำนายที่ถูกต้องโดยแบบจำลองจากการคาดการณ์ทั้งหมด สูตรเพื่อความแม่นยำคือ:
ที่ไหน:
ประสิทธิภาพของโมเดลถูกเปรียบเทียบกับรุ่น NLP ยอดนิยมอื่น ๆ เช่น Bert-Base, Bert-Large, Roberta-Base และ Roberta-Large โมเดล LLAMA3-8B บรรลุความแม่นยำสูงสุด 0.9262 แสดงให้เห็นถึงประสิทธิภาพของการปรับแต่งการเรียนการสอนและชุดพารามิเตอร์ขนาดใหญ่ของโมเดล ประสิทธิภาพที่เหนือกว่าของ LLAMA3-8B ในงานนี้เน้นย้ำข้อดีของแบบจำลองภาษาขนาดใหญ่ในการบรรลุความแม่นยำสูงในงานการจำแนกประเภทข้อความที่หลากหลายและท้าทาย
| แบบอย่าง | ความแม่นยำ |
|---|---|
| เบิร์ตเบส | 0.9063 |
| เบิร์ตขนาดใหญ่ | 0.9086 |
| เบสโรเบอร์ต้า | 0.9125 |
| Roberta-large | 0.9189 |
| LLAMA3-8B | 0.9262 |
โครงการนี้แสดงให้เห็นถึงศักยภาพของแบบจำลองภาษาขนาดใหญ่เช่น LLAMA3-8B ในงานเฉพาะโดเมนเช่นการจำแนกข้อความอารมณ์ ประสิทธิภาพของโมเดลซึ่งได้รับการสนับสนุนจากเทคนิคพิเศษเช่น Lora และ Flashattention ซึ่งเน้นย้ำถึงประสิทธิภาพของโมเดลขนาดใหญ่ในการบรรลุความแม่นยำสูงในแอปพลิเคชัน NLP
โครงการนี้ได้รับอนุญาตภายใต้ Apache License 2.0 - ดูไฟล์ใบอนุญาตสำหรับรายละเอียด
โครงการนี้ขึ้นอยู่กับการปรับเปลี่ยนงานต้นฉบับที่มีอยู่ภายใต้ Llama-Factory ซึ่งได้รับใบอนุญาตภายใต้ Apache License 2.0
สำหรับคำถามหรือปัญหาใด ๆ โปรดติดต่อ daoyuan li ที่ [email protected]


