Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
Este proyecto explora la clasificación de texto emocional utilizando el modelo LLAMA3-8B, mejorado con Lora y técnicas de flashatención. El modelo está optimizado para identificar seis categorías de emociones: alegría, tristeza, ira, miedo, amor y sorpresa. El modelo LLAMA3-8B demuestra un rendimiento superior con una precisión de 0.9262, superando otros modelos de transformadores como Bert-Base, Bert-Large, Roberta-Base y Roberta-Large.
El procesamiento del lenguaje natural (PNL) se ha convertido en un área de enfoque clave para el análisis de sentimientos, también conocido como clasificación de sentimientos o detección de sentimientos. Esta tecnología ayuda a las empresas a comprender las emociones y opiniones de los consumidores, mejorando la satisfacción del cliente y el desarrollo de productos. La gran cantidad de datos en las grandes empresas hace que el análisis manual sea poco práctico, lo que lleva a la adopción de algoritmos de IA y PNL.
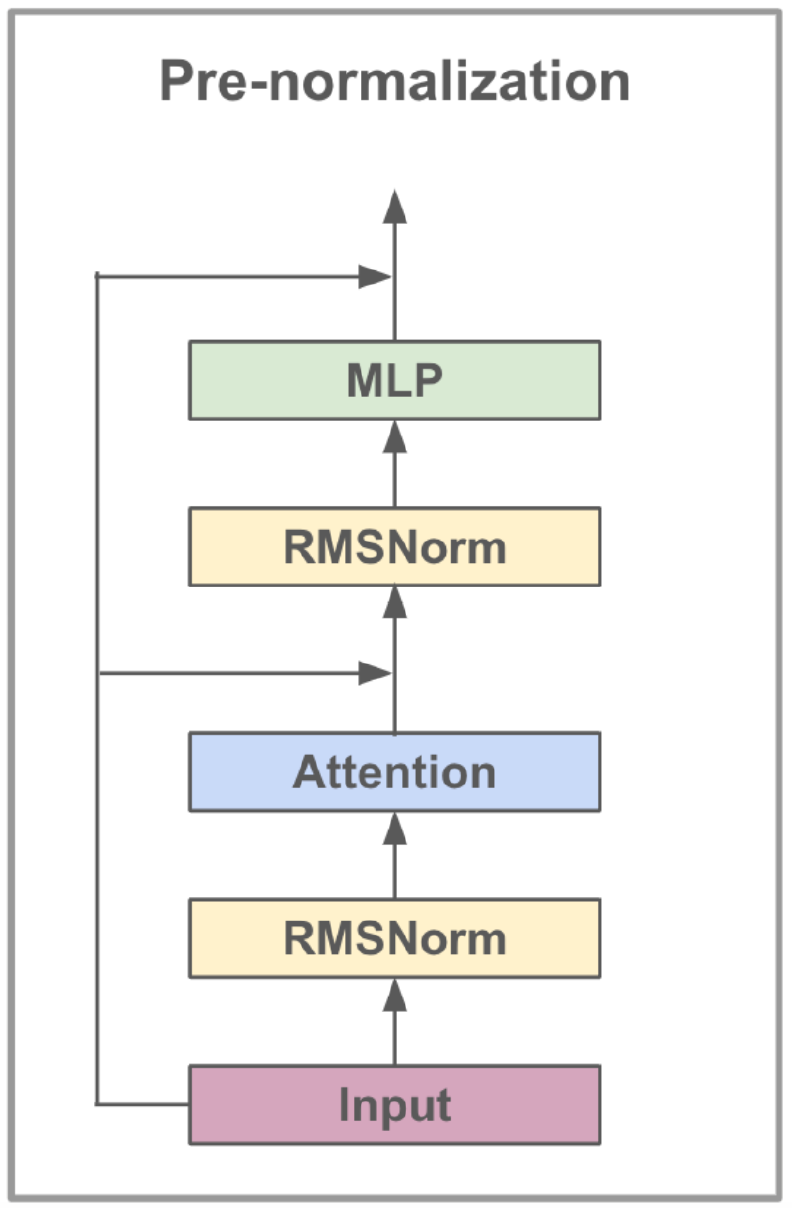
El modelo LLAMA3-8B, desarrollado por Meta AI, es un modelo de lenguaje grande optimizado para casos de uso de diálogo. Contiene 8 mil millones de parámetros y presenta mejoras significativas sobre los modelos anteriores. La serie LLAMA3 incorpora un proceso de capacitación en fases múltiples que incluye preventivo, ajuste fino supervisado y refinamiento iterativo utilizando el aprendizaje de refuerzo con retroalimentación humana (RLHF). Este proceso asegura que el modelo se alinee estrechamente con las preferencias humanas para su ayuda y seguridad.
Los avances arquitectónicos en LLAMA3 incluyen la implementación de la atención agrupada (GQA). GQA Clusters consultas para compartir pares de valores clave, reduciendo así la memoria y los costos computacionales mientras mantienen un alto rendimiento. Este método mejora significativamente la eficiencia de los cálculos de atención, particularmente en los modelos a gran escala.
LLAMA3-8B está en un conjunto de datos diverso que comprende más de 15 billones de tokens de datos disponibles públicamente, con el corte de conocimiento del modelo establecido en marzo de 2023. La fase de ajuste fino utilizó conjuntos de datos de instrucciones disponibles públicamente y más de 10 millones de ejemplos anotados humanos, asegurando una comprensión robusta de varias tareas de idiomas.
| Característica | Especificación |
|---|---|
| Datos de capacitación | Datos disponibles públicamente |
| Parámetros | 8b |
| Longitud de contexto | 8k |
| GQA | Sí |
| Recuento de tokens | 15T+ |
| Corte de conocimiento | Marzo de 2023 |
La instrucción ajustada mejora las capacidades de aprendizaje de disparo cero del modelo en diversas tareas. Esta técnica implica capacitar el modelo en conjuntos de datos diseñados específicamente para mejorar su capacidad para seguir las instrucciones. Por ejemplo, los modelos capacitados en conjuntos de datos como ALPACA-7B pueden exhibir comportamientos similares al texto de Openi-Davinci-003 para comprender y ejecutar instrucciones.
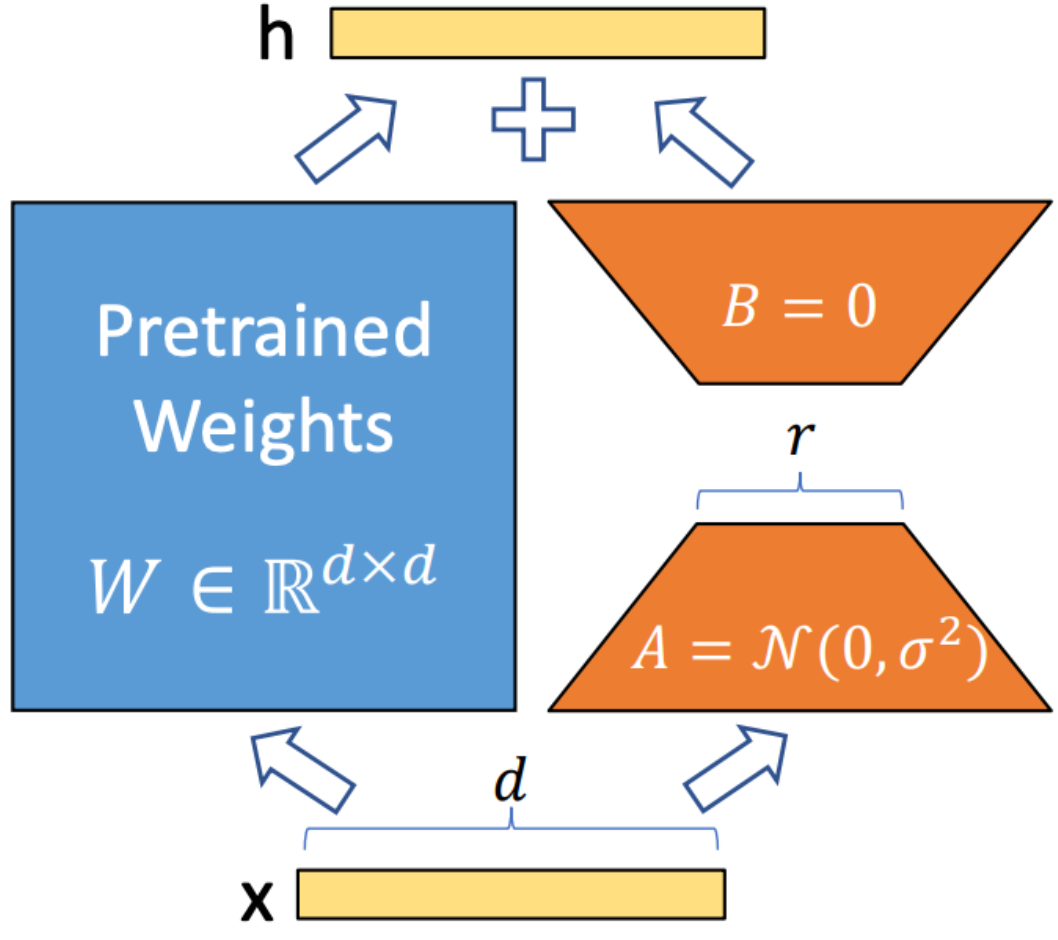
Lora (adaptación de bajo rango) es una técnica utilizada para integrar matrices de descomposición de rango entrenable en cada capa de la arquitectura del transformador. Este método reduce significativamente el número de parámetros capacitables al tiempo que se adapta modelos de lenguaje grandes a tareas o dominios específicos. A diferencia del ajuste completo, Lora mantiene los pesos del modelo previos a los productos sin cambios, actualizando solo las matrices de bajo rango durante el proceso de adaptación. Este enfoque mejora la eficiencia de entrenamiento, reduce las necesidades de almacenamiento y no aumenta la latencia de inferencia en comparación con los modelos completamente ajustados.
FlashAttent V2 es una técnica de optimización diseñada para acelerar el mecanismo de atención en los modelos de transformadores. Se centra en mejorar la eficiencia computacional y reducir el uso de la memoria durante el entrenamiento. El flashatent logra esto descomponiendo el cálculo de atención en trozos más pequeños y más manejables, mejorando así la utilización de caché y reduciendo el acceso a la memoria. Además, emplea operaciones de matriz dispersa para aprovechar la escasez en los mecanismos de atención, lo que ayuda a evitar los cálculos innecesarios. Las operaciones canalizadas permiten la ejecución paralela de diferentes etapas de cálculo, minimizando aún más el tiempo de procesamiento.
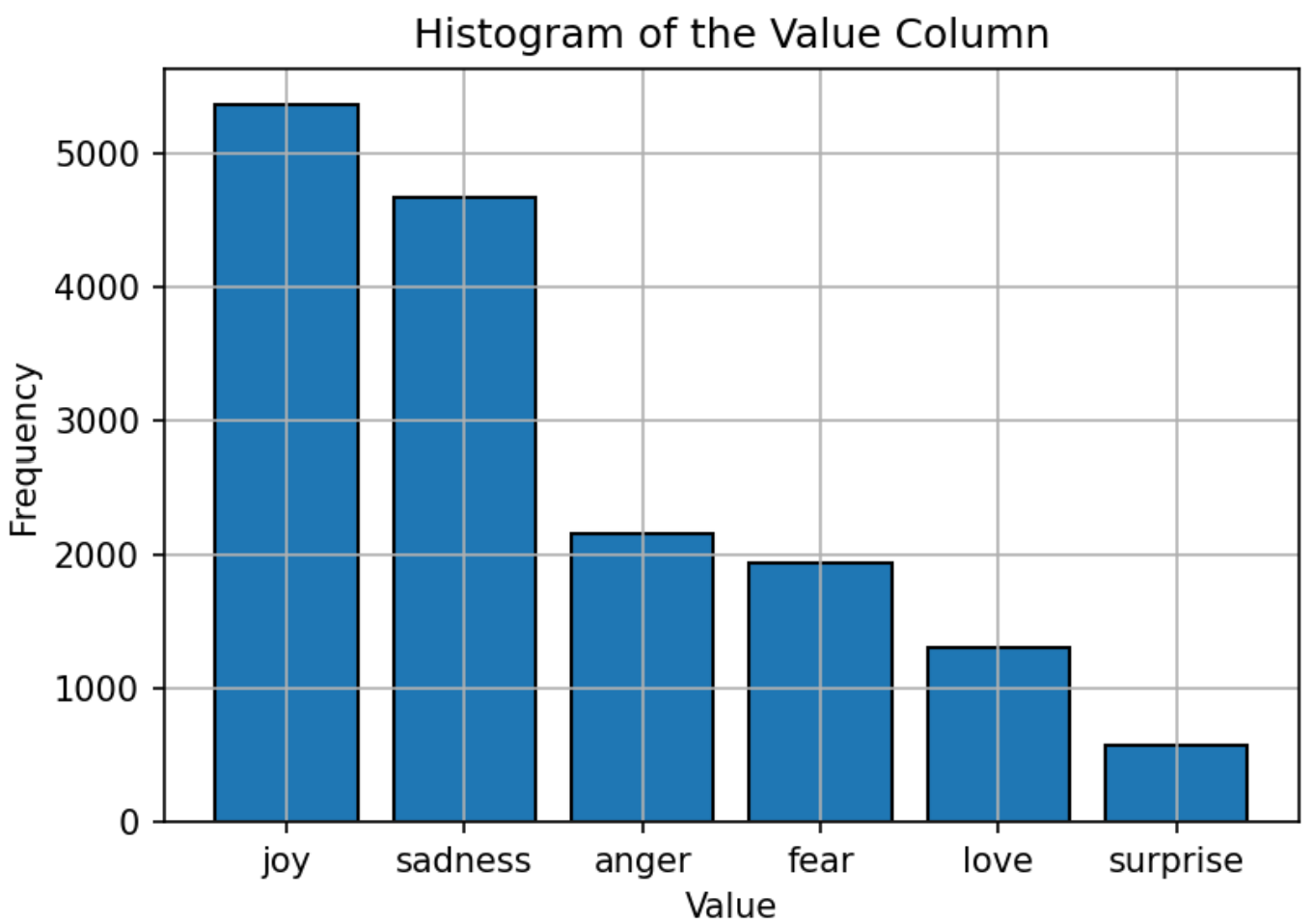
El conjunto de datos utilizado para entrenar el modelo consiste en texto etiquetado con seis emociones: alegría, tristeza, ira, miedo, amor y sorpresa. La distribución del conjunto de datos es relativamente equilibrada, siendo la "alegría" la emoción más común y la "sorpresa" menos. Esta distribución equilibrada proporciona una base sólida para que el modelo clasifique con precisión las emociones sin sesgo hacia ninguna categoría en particular.
Los hiperparámetros del modelo LLAMA3-8B se establecen como sigue:
| Parámetro | Configuración |
|---|---|
| Optimizador | Adán |
| Tasa de aprendizaje | 5E-5 |
| Tamaño por lotes | 5 |
| Épocas | 3 |
| Rango de lora | 8 |
| Pasos de acumulación de gradiente | 4 |
| Longitud máxima | 512 |
El modelo está entrenado utilizando el Adam Optimizer, conocido por sus capacidades de tasa de aprendizaje adaptativa. Se emplea un programa de tarifas de aprendizaje coseno para ajustar la tasa de aprendizaje durante la capacitación. El tamaño del lote se establece en 5, con acumulación de gradiente en 4 pasos para optimizar el uso de la memoria. El modelo está entrenado para 3 épocas, con el formato de precisión FP16 utilizado para guardar la memoria de GPU mientras mantiene el rendimiento. El rango Lora de 8 indica el orden de la matriz de bajo rango utilizado en el proceso de adaptación.
La métrica principal utilizada para evaluar el rendimiento del modelo es la precisión. Esta métrica mide la proporción de predicciones correctas hechas por el modelo a partir de todas las predicciones. La fórmula para la precisión es:
Dónde:
El rendimiento del modelo se compara con otros modelos PNL populares, como Bert-Base, Bert-Large, Roberta-Base y Roberta-Large. El modelo LLAMA3-8B logra la mayor precisión de 0.9262, lo que demuestra la efectividad de la instrucción ajustado y el gran conjunto de parámetros del modelo. El rendimiento superior de LLAMA3-8B en esta tarea subraya las ventajas de los modelos de idiomas grandes para lograr una alta precisión en tareas de clasificación de texto diversas y desafiantes.
| Modelo | Exactitud |
|---|---|
| Base | 0.9063 |
| Bernemacia | 0.9086 |
| Base Roberta | 0.9125 |
| Roberta-Large | 0.9189 |
| Llama3-8b | 0.9262 |
Este proyecto demuestra el potencial de modelos de idiomas grandes, como LLAMA3-8B, en tareas específicas de dominio como la clasificación de texto emocional. El rendimiento del modelo, impulsado por técnicas especializadas como Lora y Flashatent, subraya la efectividad de los grandes modelos para lograr una alta precisión en las aplicaciones de PNL.
Este proyecto tiene licencia bajo la licencia APACHE 2.0; consulte el archivo de licencia para obtener más detalles.
Este proyecto se basa en las modificaciones del trabajo original disponible en Llama-Factory, que tiene licencia bajo la licencia de Apache 2.0.
Para cualquier pregunta o problema, comuníquese con Daoyuan Li en [email protected].


