Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
Proyek ini mengeksplorasi klasifikasi teks emosi menggunakan model LLAMA3-8B, ditingkatkan dengan teknik Lora dan flashattention. Model ini dioptimalkan untuk mengidentifikasi enam kategori emosi: kegembiraan, kesedihan, kemarahan, ketakutan, cinta, dan kejutan. Model LLAMA3-8B menunjukkan kinerja yang unggul dengan akurasi 0,9262, melampaui model transformator lain seperti Bert-Base, Bert-Large, Roberta-Base, dan Roberta-Large.
Natural Language Processing (NLP) telah menjadi area fokus utama untuk analisis sentimen, juga dikenal sebagai klasifikasi sentimen atau deteksi sentimen. Teknologi ini membantu bisnis memahami emosi dan pendapat konsumen, meningkatkan kepuasan pelanggan dan pengembangan produk. Sejumlah besar data di perusahaan besar membuat analisis manual tidak praktis, yang mengarah pada adopsi algoritma AI dan NLP.
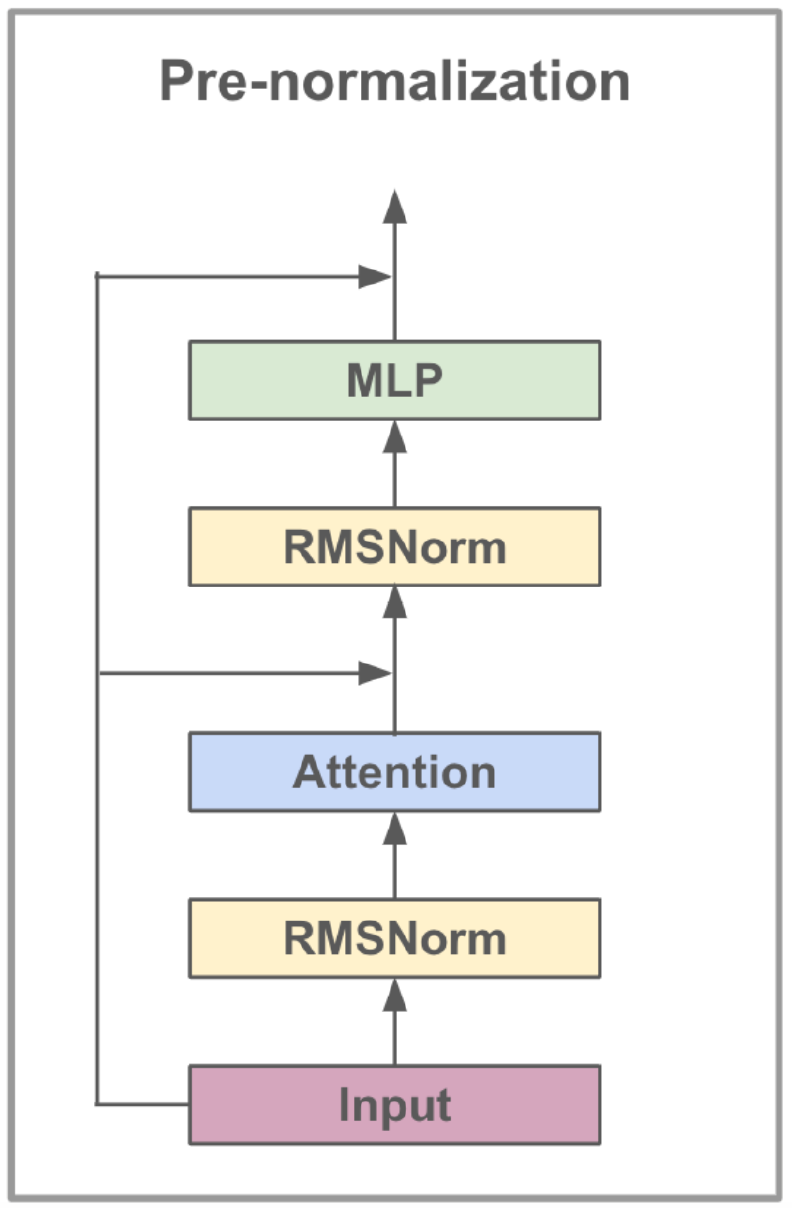
Model LLAMA3-8B, yang dikembangkan oleh Meta AI, adalah model bahasa besar yang dioptimalkan untuk kasus penggunaan dialog. Ini berisi 8 miliar parameter dan fitur peningkatan yang signifikan dibandingkan model sebelumnya. Seri LLAMA3 menggabungkan proses pelatihan multi-fase yang mencakup pretraining, fine-tuning yang diawasi, dan penyempurnaan berulang menggunakan pembelajaran penguatan dengan umpan balik manusia (RLHF). Proses ini memastikan bahwa model ini selaras dengan preferensi manusia untuk bantuan dan keselamatan.
Kemajuan arsitektur di LLAMA3 meliputi implementasi Perhatian Query (GQA) yang dikelompokkan. GQA Clusters menanyai untuk berbagi pasangan nilai kunci, sehingga mengurangi biaya memori dan komputasi sambil mempertahankan kinerja tinggi. Metode ini secara signifikan meningkatkan efisiensi perhitungan perhatian, terutama dalam model skala besar.
LLAMA3-8B diawali dengan beragam dataset yang terdiri dari lebih dari 15 triliun token dari data yang tersedia untuk umum, dengan pemotongan pengetahuan model yang ditetapkan pada Maret 2023. Fase penyempurnaan memanfaatkan dataset instruksi yang tersedia untuk umum dan lebih dari 10 juta contoh manusia yang dianotasi manusia, memastikan pemahaman yang kuat tentang berbagai bahasa.
| Fitur | Spesifikasi |
|---|---|
| Data pelatihan | Data yang tersedia untuk umum |
| Parameter | 8b |
| Panjang konteks | 8k |
| GQA | Ya |
| Hitungan token | 15t+ |
| Cutoff Pengetahuan | Maret 2023 |
Fine-tuning instruksi meningkatkan kemampuan belajar nol-tembakan model di berbagai tugas. Teknik ini melibatkan pelatihan model pada dataset yang dirancang khusus untuk meningkatkan kemampuannya mengikuti instruksi. Misalnya, model yang dilatih pada dataset seperti ALPACA-7B dapat menunjukkan perilaku yang mirip dengan teks-davinsi-003 Openai dalam memahami dan melaksanakan instruksi.
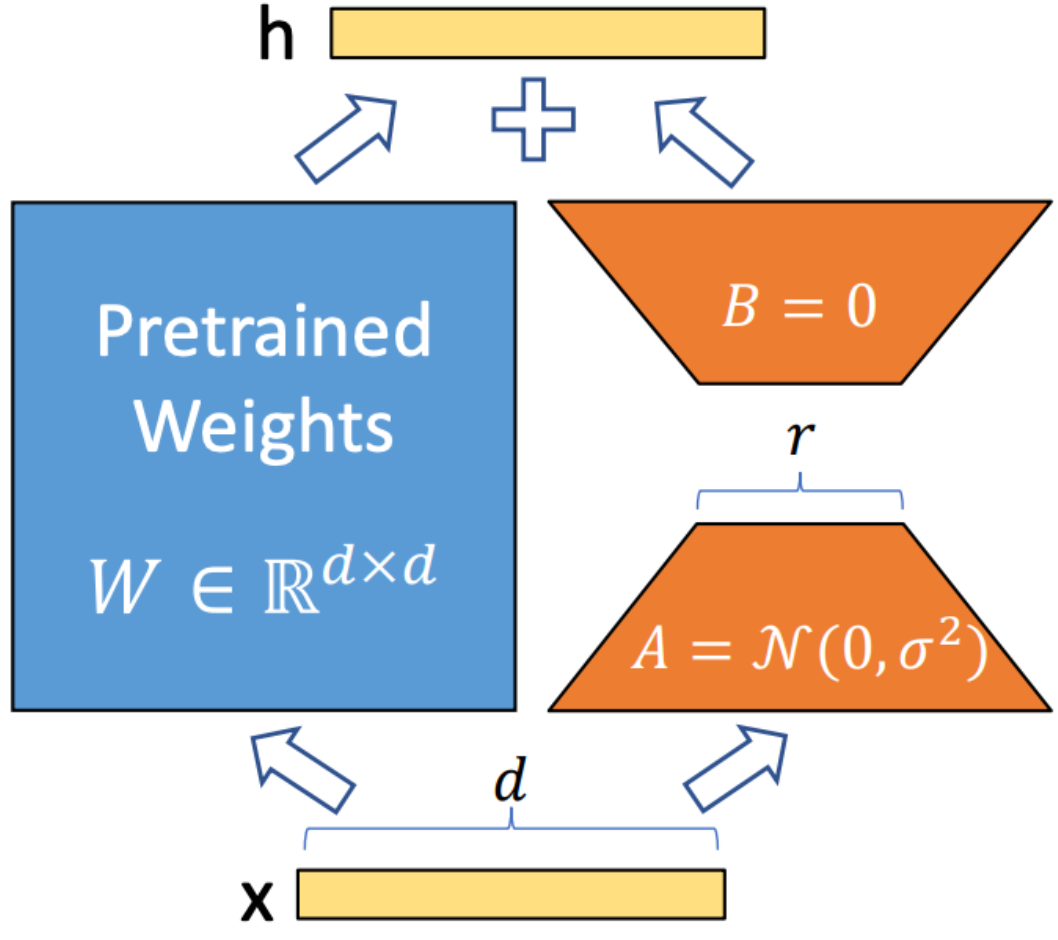
Lora (adaptasi rendah) adalah teknik yang digunakan untuk mengintegrasikan matriks dekomposisi peringkat yang dapat dilatih ke dalam setiap lapisan arsitektur transformator. Metode ini secara signifikan mengurangi jumlah parameter yang dapat dilatih sambil mengadaptasi model bahasa besar dengan tugas atau domain tertentu. Tidak seperti fine-tuning penuh, Lora menjaga bobot model pretrain yang tidak berubah, hanya memperbarui matriks peringkat rendah selama proses adaptasi. Pendekatan ini meningkatkan efisiensi pelatihan, mengurangi kebutuhan penyimpanan, dan tidak meningkatkan latensi inferensi dibandingkan dengan model yang sepenuhnya disempurnakan.
Flashattention V2 adalah teknik optimasi yang dirancang untuk mempercepat mekanisme perhatian dalam model transformator. Ini berfokus pada peningkatan efisiensi komputasi dan mengurangi penggunaan memori selama pelatihan. Flashattention mencapai hal ini dengan memecah perhitungan perhatian menjadi potongan yang lebih kecil dan lebih mudah dikelola, sehingga meningkatkan pemanfaatan cache dan mengurangi akses memori. Selain itu, ia menggunakan operasi matriks yang jarang untuk memanfaatkan sparsity dalam mekanisme perhatian, yang membantu melewati perhitungan yang tidak perlu. Operasi pipa memungkinkan pelaksanaan paralel dari berbagai tahap komputasi, lebih lanjut meminimalkan waktu pemrosesan.
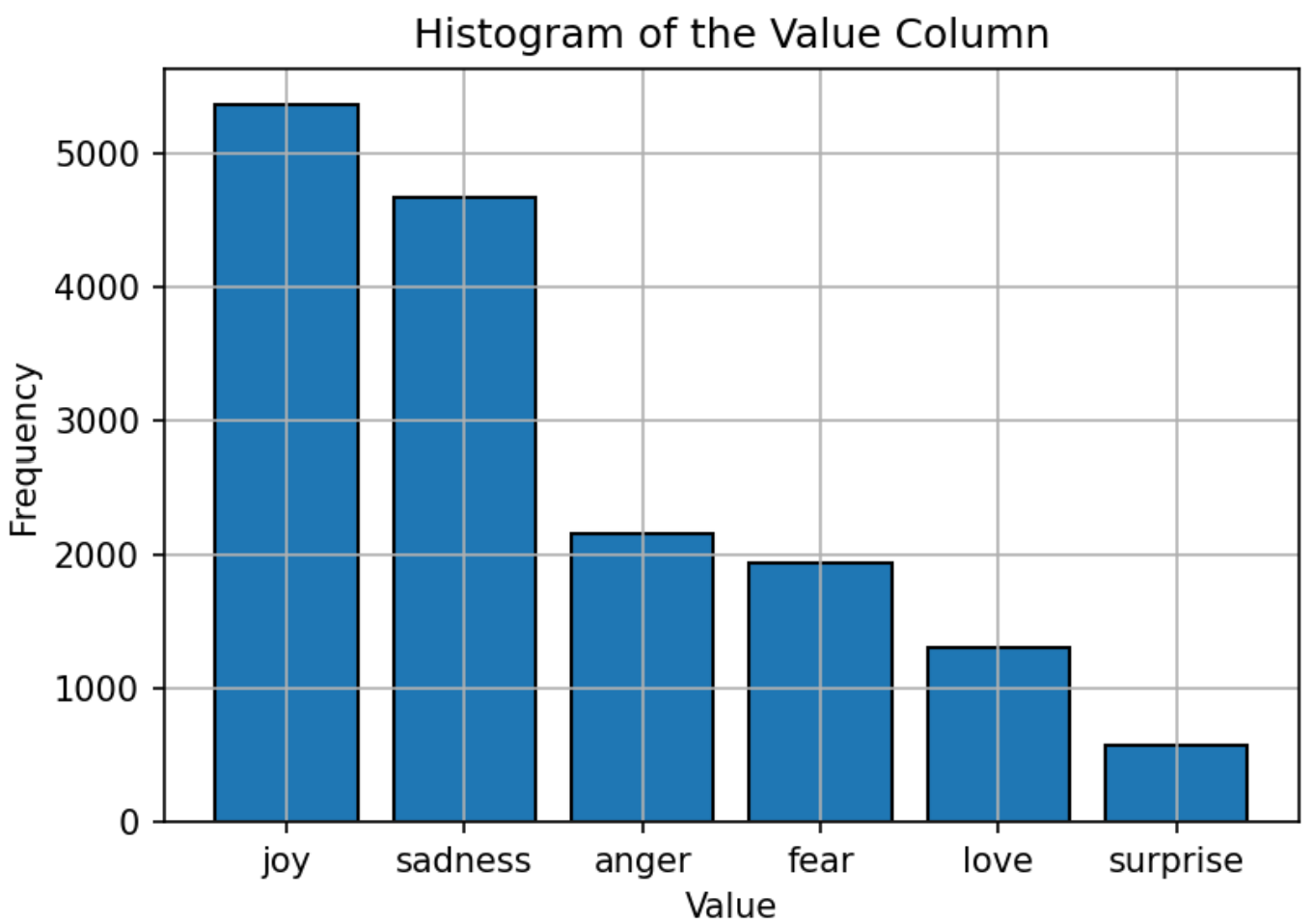
Dataset yang digunakan untuk melatih model terdiri dari teks yang diberi label dengan enam emosi: kegembiraan, kesedihan, kemarahan, ketakutan, cinta, dan kejutan. Distribusi dataset relatif seimbang, dengan "kegembiraan" menjadi emosi yang paling umum dan "mengejutkan" paling sedikit. Distribusi yang seimbang ini memberikan dasar yang kuat bagi model untuk secara akurat mengklasifikasikan emosi tanpa bias terhadap kategori tertentu.
Hyperparameters model LLAMA3-8B ditetapkan sebagai berikut:
| Parameter | Pengaturan |
|---|---|
| Pengoptimal | Adam |
| Tingkat pembelajaran | 5e-5 |
| Ukuran batch | 5 |
| Zaman | 3 |
| Peringkat lora | 8 |
| Langkah akumulasi gradien | 4 |
| Panjang maksimal | 512 |
Model ini dilatih menggunakan Adam Optimizer, yang dikenal karena kemampuan laju pembelajaran adaptifnya. Jadwal tingkat pembelajaran kosinus digunakan untuk menyesuaikan tingkat pembelajaran selama pelatihan. Ukuran batch diatur ke 5, dengan akumulasi gradien lebih dari 4 langkah untuk mengoptimalkan penggunaan memori. Model ini dilatih untuk 3 zaman, dengan format presisi FP16 yang digunakan untuk menyimpan memori GPU sambil mempertahankan kinerja. Peringkat LORA dari 8 menunjukkan urutan matriks peringkat rendah yang digunakan dalam proses adaptasi.
Metrik utama yang digunakan untuk mengevaluasi kinerja model adalah akurasi. Metrik ini mengukur proporsi prediksi yang benar yang dibuat oleh model dari semua prediksi. Formula untuk akurasi adalah:
Di mana:
Kinerja model dibandingkan dengan model NLP populer lainnya, seperti Bert-Base, Bert-Large, Roberta-Base, dan Roberta-Large. Model LLAMA3-8B mencapai akurasi tertinggi 0,9262, menunjukkan efektivitas penyempurnaan instruksi dan set parameter besar model. Kinerja superior LLAMA3-8B dalam tugas ini menggarisbawahi keunggulan model bahasa besar dalam mencapai akurasi tinggi di berbagai tugas klasifikasi teks yang menantang dan menantang.
| Model | Ketepatan |
|---|---|
| Bert-base | 0.9063 |
| Bert-Large | 0.9086 |
| Roberta-Base | 0.9125 |
| Roberta-Large | 0.9189 |
| Llama3-8b | 0.9262 |
Proyek ini menunjukkan potensi model bahasa besar, seperti LLAMA3-8B, dalam tugas khusus domain seperti klasifikasi teks emosi. Kinerja model, didorong oleh teknik khusus seperti Lora dan flashattention, menggarisbawahi efektivitas model besar dalam mencapai akurasi tinggi dalam aplikasi NLP.
Proyek ini dilisensikan di bawah Lisensi Apache 2.0 - lihat file lisensi untuk detailnya.
Proyek ini didasarkan pada modifikasi pada karya asli yang tersedia di bawah Llama-Factory, yang dilisensikan di bawah Lisensi Apache 2.0.
Untuk pertanyaan atau masalah, silakan hubungi Daoyuan Li di [email protected].


