Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
In diesem Projekt werden die Emotionstextklassifizierung unter Verwendung des LLAMA3-8B-Modells untersucht, das mit LORA- und Flashattention-Techniken verbessert wird. Das Modell ist optimiert, um sechs Emotionskategorien zu identifizieren: Freude, Traurigkeit, Wut, Angst, Liebe und Überraschung. Das LLAMA3-8B-Modell zeigt eine überlegene Leistung mit einer Genauigkeit von 0,9262 und übertrifft andere Transformatormodelle wie Bert-Base, Bert-Large, Roberta-Base und Roberta-Large.
Die natürliche Sprachverarbeitung (NLP) ist zu einem wichtigen Schwerpunkt für die Stimmungsanalyse geworden, auch als Stimmungsklassifizierung oder Stimmungserkennung bezeichnet. Diese Technologie hilft Unternehmen, Verbrauchergefühle und Meinungen zu verstehen und die Kundenzufriedenheit und die Produktentwicklung zu verbessern. Die große Datenmenge in großen Unternehmen macht manuelle Analyse unpraktisch, was zur Einführung von AI- und NLP -Algorithmen führt.
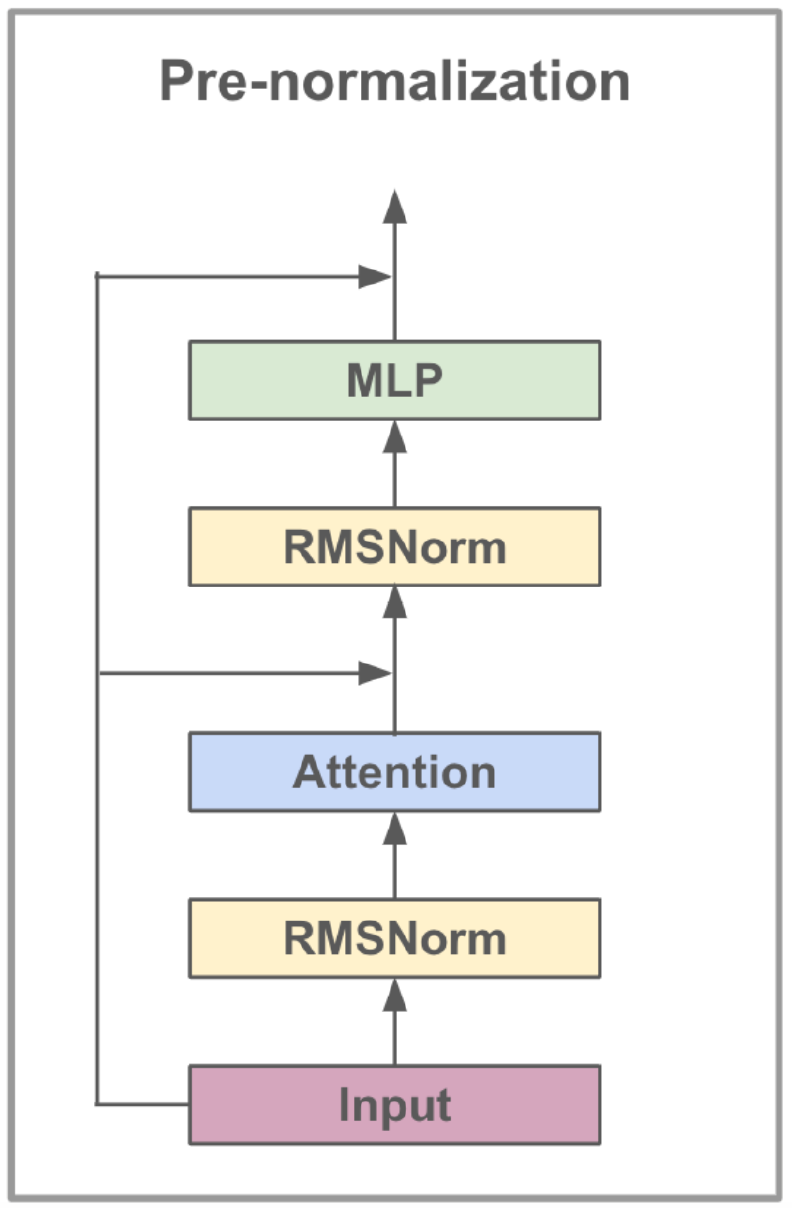
Das von Meta AI entwickelte LLAMA3-8B-Modell ist ein großes Sprachmodell, das für Dialog-Anwendungsfälle optimiert ist. Es enthält 8 Milliarden Parameter und verfügt über signifikante Verbesserungen gegenüber früheren Modellen. Die LLAMA3-Serie enthält einen Mehrphasen-Trainingsprozess, der voraber, beaufsichtigte Feinabstimmung und iterative Verfeinerung unter Verwendung von Verstärkungslernen mit menschlichem Feedback (RLHF) umfasst. Dieser Prozess stellt sicher, dass das Modell eng mit den menschlichen Vorlieben für Hilfsmaßnahmen und Sicherheit übereinstimmt.
Zu den architektonischen Fortschritten in LLAMA3 gehört die Umsetzung der Aufmerksamkeit von Gruppiergraden (GQA). GQA-Cluster Fragen zum Austausch von Schlüsselwertpaaren, wodurch die Speicher- und Rechenkosten gesenkt und gleichzeitig eine hohe Leistung aufrechterhalten wird. Diese Methode verbessert die Effizienz von Aufmerksamkeitsberechnungen erheblich, insbesondere in großen Modellen.
LLAMA3-8B ist in einem vielfältigen Datensatz mit mehr als 15 Billionen Token aus öffentlich verfügbaren Daten vorgelegt, wobei der Kenntnis der Kenntnisse des Modells im März 2023 festgelegt ist. Die feinabstimmige Phase verwendete öffentlich verfügbare Datensätze und über 10 Millionen Menschen mit Menschenannot mit menschlichem Anbieter und gewährten sich einen robusten Verständnis für verschiedene Sprachaufgaben.
| Besonderheit | Spezifikation |
|---|---|
| Trainingsdaten | Öffentlich verfügbare Daten |
| Parameter | 8b |
| Kontextlänge | 8k |
| GQA | Ja |
| Token Count | 15t+ |
| Wissens Cutoff | März 2023 |
Die Feinabstimmung der Unterricht verbessert die Null-Shot-Lernfunktionen des Modells über verschiedene Aufgaben hinweg. Diese Technik umfasst das Training des Modells auf Datensätzen, die speziell für die Verbesserung der Fähigkeit zur Befolgung von Anweisungen entwickelt wurden. Beispielsweise können Modelle, die auf Datensätzen wie Alpaca-7b ausgebildet sind, Verhaltensweisen aufweisen, die dem OpenAI-Text-Davin-003 ähnlich sind, um Anweisungen zu verstehen und auszuführen.
LORA (Anpassung mit niedriger Rang) ist eine Technik, mit der trainierbare Rang-Zersetzungsmatrizen in jede Schicht der Transformatorarchitektur integriert werden. Diese Methode reduziert die Anzahl der trainierbaren Parameter signifikant, während große Sprachmodelle an bestimmte Aufgaben oder Domänen angepasst werden. Im Gegensatz zur vollständigen Feinabstimmung hält Lora die vorbereiteten Modellgewichte unverändert und aktualisiert nur die niedrigen Matrizen während des Anpassungsprozesses. Dieser Ansatz verbessert die Schulungseffizienz, verringert die Speicheranforderungen und erhöht die Latenz des Inferenz im Vergleich zu vollständig abgestimmten Modellen nicht.
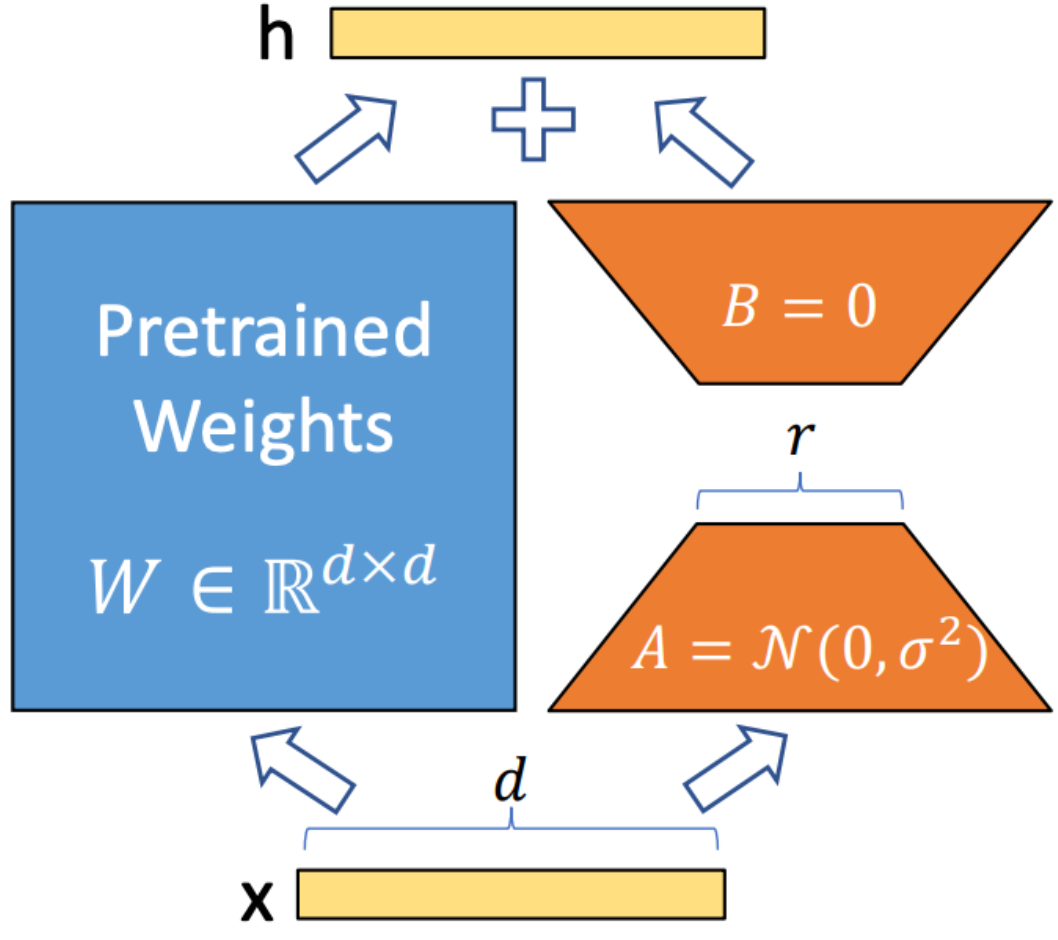
Flashattention V2 ist eine Optimierungstechnik, die den Aufmerksamkeitsmechanismus in Transformatormodellen beschleunigt. Es konzentriert sich auf die Verbesserung der Recheneffizienz und die Reduzierung des Speicherverbrauchs während des Trainings. Flashattention erreicht dies, indem sie die Aufmerksamkeitsberechnung in kleinere, überschaubarere Stücke unterteilt, wodurch die Cache -Nutzung verbessert und den Speicherzugriff verringert wird. Darüber hinaus werden spärliche Matrixoperationen verwendet, um die Sparsity in Aufmerksamkeitsmechanismen zu nutzen, die dazu beitragen, unnötige Berechnungen zu umgehen. Pipelined Operations ermöglichen die parallele Ausführung verschiedener Berechnungsstadien und minimieren die Verarbeitungszeit weiter.
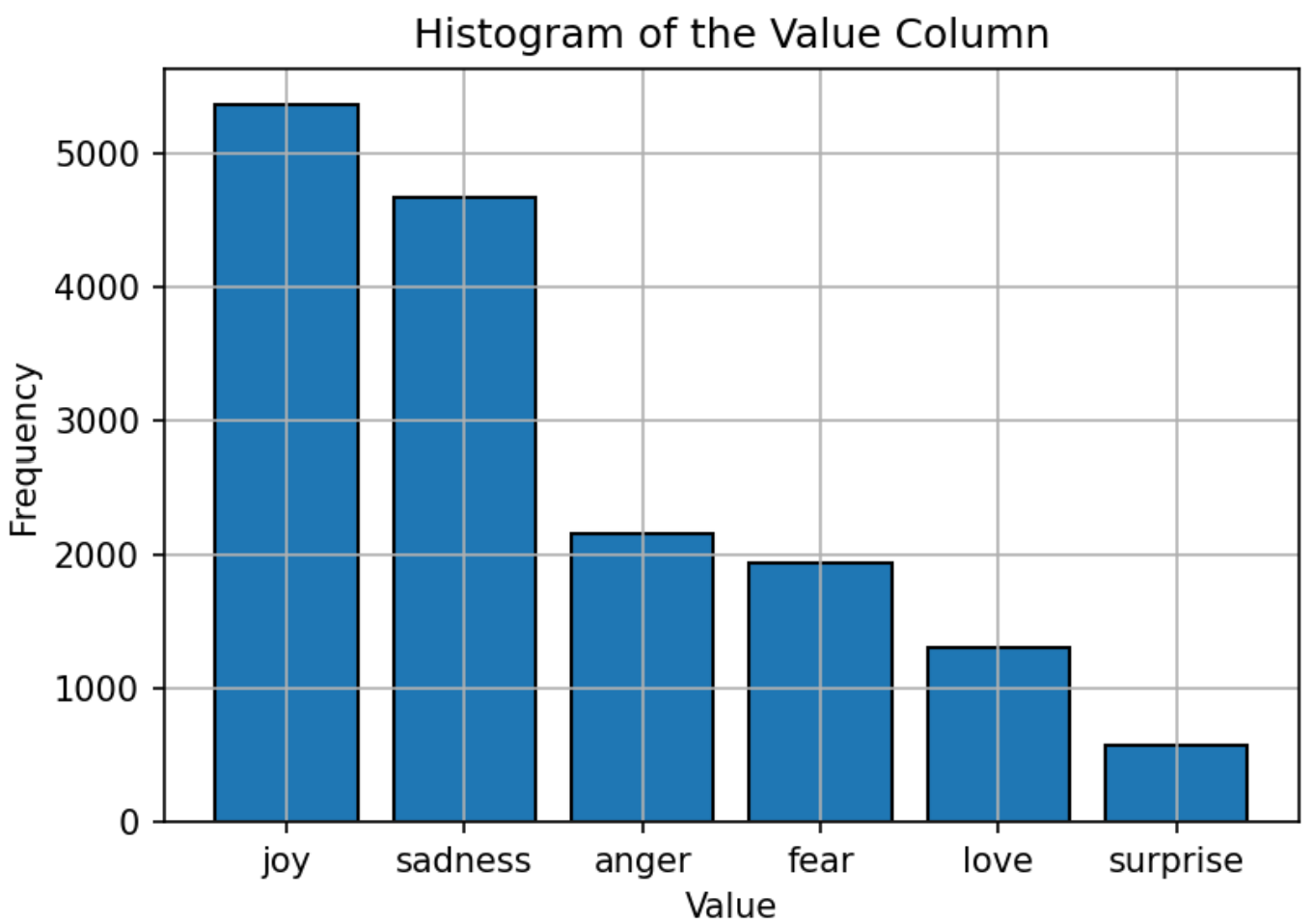
Der Datensatz, der zum Training verwendet wird, das Modell besteht aus Text mit sechs Emotionen: Freude, Traurigkeit, Wut, Angst, Liebe und Überraschung. Die Verteilung des Datensatzes ist relativ ausgewogen, wobei "Freude" die häufigste Emotion und "Überraschung" am wenigsten ist. Diese ausgewogene Verteilung bietet eine starke Grundlage für das Modell, um Emotionen ohne Verzerrung in eine bestimmte Kategorie genau zu klassifizieren.
Die Hyperparameter des LLAMA3-8B-Modells sind wie folgt festgelegt:
| Parameter | Einstellung |
|---|---|
| Optimierer | Adam |
| Lernrate | 5e-5 |
| Chargengröße | 5 |
| Epochen | 3 |
| Lora Rang | 8 |
| Gradientenakkumulationsschritte | 4 |
| Maximale Länge | 512 |
Das Modell wird mit dem Adam Optimizer geschult, der für seine adaptiven Lernrate -Funktionen bekannt ist. Ein Kosinus -Lernrate -Zeitplan für die Lernrate wird verwendet, um die Lernrate während des Trainings anzupassen. Die Chargengröße ist auf 5 eingestellt, wobei die Gradientenakkumulation über 4 Schritte zur Optimierung des Speicherverbrauchs ist. Das Modell wird für 3 Epochen trainiert, wobei das FP16 -Präzisionsformat zum Speichern des GPU -Speichers verwendet wird und gleichzeitig die Leistung beibehalten wird. Der Lora-Rang von 8 gibt die Reihenfolge der im Anpassungsverfahren verwendeten niedrigen Matrix an.
Die primäre Metrik zur Bewertung der Leistung des Modells ist die Genauigkeit. Diese metrische misst den Anteil der korrekten Vorhersagen, die das Modell aus allen Vorhersagen herausgegeben hat. Die Genauigkeitsformel lautet:
Wo:
Die Leistung des Modells wird mit anderen beliebten NLP-Modellen wie Bert-Base, Bert-Large, Roberta-Base und Roberta-Large verglichen. Das LLAMA3-8B-Modell erreicht die höchste Genauigkeit von 0,9262 und zeigt die Wirksamkeit der Feinabstimmung des Modells und den großen Parametersatz des Modells. Die überlegene Leistung von LLAMA3-8B in dieser Aufgabe unterstreicht die Vorteile von Großsprachmodellen bei der Erreichung einer hohen Genauigkeit bei verschiedenen und herausfordernden Textklassifizierungsaufgaben.
| Modell | Genauigkeit |
|---|---|
| Bert-Base | 0,9063 |
| Bert-Large | 0,9086 |
| Roberta-Base | 0,9125 |
| Roberta-Large | 0,9189 |
| LAMA3-8B | 0,9262 |
Dieses Projekt zeigt das Potenzial großer Sprachmodelle wie LLAMA3-8B in domänenspezifischen Aufgaben wie der Klassifizierung von Emotionen. Die Leistung des Modells, die durch spezialisierte Techniken wie Lora und Flashattention verstärkt wird, unterstreicht die Wirksamkeit großer Modelle bei der Erzielung einer hohen Genauigkeit bei NLP -Anwendungen.
Dieses Projekt ist unter der Apache -Lizenz 2.0 lizenziert. Weitere Informationen finden Sie in der Lizenzdatei.
Dieses Projekt basiert auf Modifikationen an der ursprünglichen Arbeit, die unter Lama-Factory verfügbar ist, die unter der Apache-Lizenz 2.0 lizenziert ist.
Für Fragen oder Probleme wenden Sie sich bitte an Daoyuan Li unter [email protected].


