Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
يستكشف هذا المشروع تصنيف نص العاطفة باستخدام نموذج LLAMA3-8B ، والذي تم تعزيزه مع تقنيات LORA و Flashattention. تم تحسين النموذج لتحديد ست فئات العاطفة: الفرح والحزن والغضب والخوف والحب والمفاجأة. يوضح نموذج LLAMA3-8B أداءً فائقًا بدقة قدره 0.9262 ، متجاوزًا نماذج المحولات الأخرى مثل Bert-Base و Bert-Large و Roberta-Base و Roberta-Large.
أصبحت معالجة اللغة الطبيعية (NLP) مجال تركيز رئيسي لتحليل المشاعر ، والمعروف أيضًا باسم تصنيف المشاعر أو اكتشاف المشاعر. تساعد هذه التكنولوجيا الشركات على فهم عواطف وآراء المستهلك ، وتعزيز رضا العملاء وتطوير المنتجات. إن كمية البيانات الواسعة في الشركات الكبيرة تجعل التحليل اليدوي غير عملي ، مما يؤدي إلى اعتماد خوارزميات AI و NLP.
يعد نموذج LLAMA3-8B ، الذي تم تطويره بواسطة META AI ، نموذجًا كبيرًا للغة محسّن لحالات استخدام الحوار. أنه يحتوي على 8 مليارات معلمات ويتميز بتحسينات كبيرة على النماذج السابقة. تتضمن سلسلة LLAMA3 عملية تدريب متعددة المراحل تتضمن تدريبيًا ، وصقلًا خاضعًا للإشراف ، والصقل التكراري باستخدام التعلم التعزيز مع التعليقات البشرية (RLHF). تضمن هذه العملية أن النموذج يتماشى عن كثب مع التفضيلات البشرية للمساعدة والسلامة.
تشمل التطورات المعمارية في LLAMA3 تنفيذ انتباه المساعد المجمع (GQA). يستفسر GQA Clusters لتبادل أزواج القيمة الرئيسية ، وبالتالي تقليل الذاكرة والتكاليف الحسابية مع الحفاظ على أداء مرتفع. تعزز هذه الطريقة بشكل كبير كفاءة حسابات الانتباه ، وخاصة في النماذج واسعة النطاق.
تم تجهيز LLAMA3-8B على مجموعة بيانات متنوعة تضم أكثر من 15 تريليون رمز من البيانات المتاحة للجمهور ، مع تحديد مقطع المعرفة للنموذج في مارس 2023. وقد استخدمت المرحلة الدقيقة مجموعات بيانات التعليم المتاحة للجمهور وأكثر من 10 ملايين أمثلة مصنوعة من الإنسان ، مما يضمن فهمًا قويًا لمختلف لغة اللغة.
| ميزة | مواصفة |
|---|---|
| بيانات التدريب | البيانات المتاحة للجمهور |
| حدود | 8 ب |
| طول السياق | 8K |
| GQA | نعم |
| عدد الرمز المميز | 15T+ |
| قطع المعرفة | مارس 2023 |
يعزز ضبط التعليمات الدقيقة قدرات التعلم صفرية من النموذج عبر المهام المتنوعة. تتضمن هذه التقنية تدريب النموذج على مجموعات البيانات المصممة خصيصًا لتحسين قدرتها على اتباع التعليمات. على سبيل المثال ، يمكن للموديلات المدربة على مجموعات البيانات مثل Alpaca-7B إظهار سلوكيات مماثلة لنص Openai-Davinci-003 في فهم التعليمات وتنفيذها.
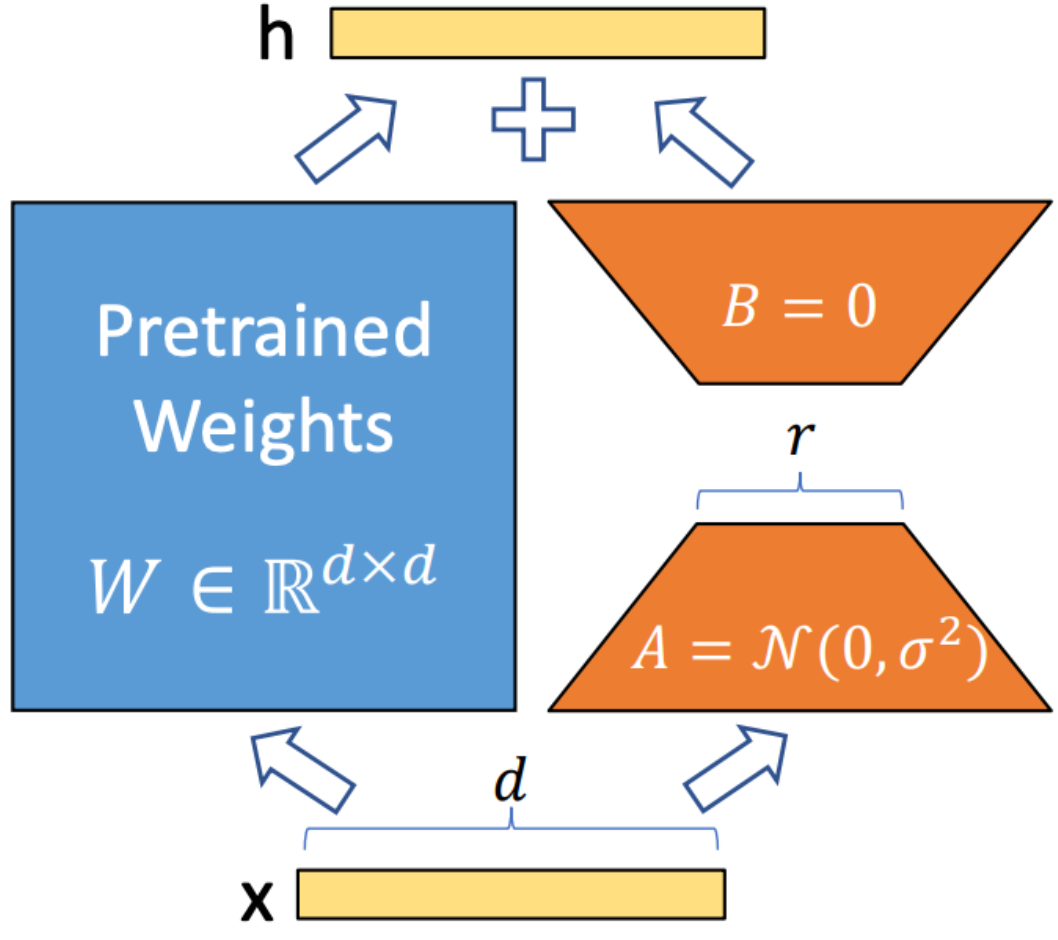
Lora (التكيف منخفض الرتبة) هي تقنية تستخدم لدمج مصفوفات تحلل الرتبة القابلة للتدريب في كل طبقة من بنية المحول. هذه الطريقة تقلل بشكل كبير من عدد المعلمات القابلة للتدريب مع تكييف نماذج اللغة الكبيرة مع مهام أو مجالات محددة. على عكس التثبيت الكامل ، تحافظ Lora على الأوزان النموذجية المسبقة دون تغيير ، مما يحديث المصفوفات ذات الرتبة المنخفضة فقط أثناء عملية التكيف. يعزز هذا النهج كفاءة التدريب ، ويقلل من احتياجات التخزين ، ولا يزيد من زمن الاستدلال مقارنة بالنماذج التي تم ضبطها بالكامل.
Flashattention V2 هي تقنية تحسين مصممة لتسريع آلية الانتباه في نماذج المحولات. وهو يركز على تحسين الكفاءة الحسابية وتقليل استخدام الذاكرة أثناء التدريب. يحقق Flashattention هذا من خلال تقسيم حساب الانتباه إلى أجزاء أصغر وأكثر قابلية للإدارة ، وبالتالي تعزيز استخدام ذاكرة التخزين المؤقت وتقليل الوصول إلى الذاكرة. بالإضافة إلى ذلك ، توظف عمليات المصفوفة المتفرقة للاستفادة من التباين في آليات الانتباه ، مما يساعد على تجاوز الحسابات غير الضرورية. تتيح عمليات الأنابيب تنفيذًا متوازيًا لمراحل حساب مختلفة ، مما يزيد من وقت المعالجة إلى الحد الأدنى.
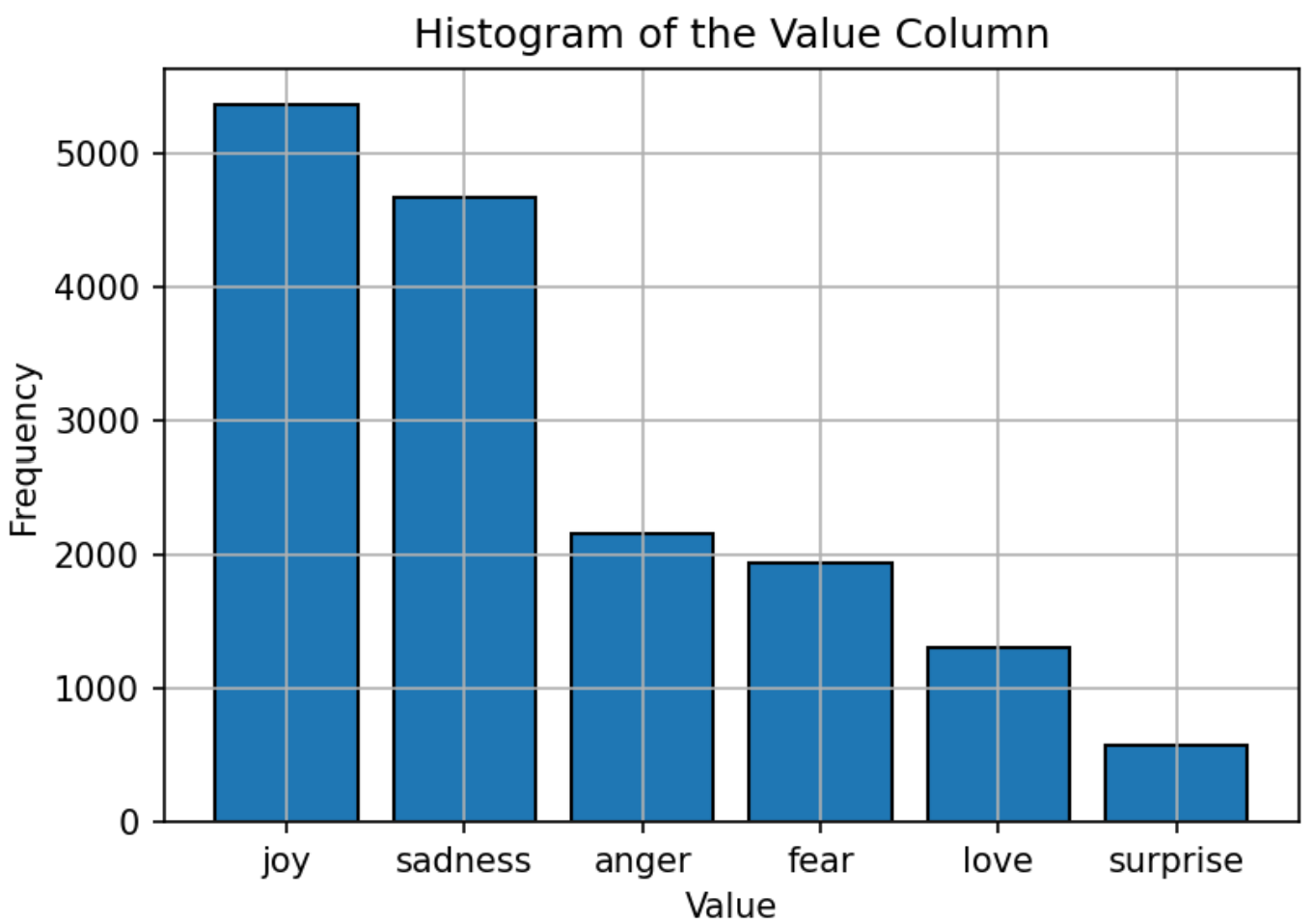
تتكون مجموعة البيانات المستخدمة لتدريب النموذج من نص مُسمى بست مشاعر: الفرح والحزن والغضب والخوف والحب والمفاجأة. توزيع مجموعة البيانات متوازنة نسبيًا ، حيث يكون "الفرح" هو العاطفة الأكثر شيوعًا و "المفاجأة" على الأقل. يوفر هذا التوزيع المتوازن أساسًا قويًا للنموذج لتصنيف المشاعر بدقة دون تحيز تجاه أي فئة معينة.
يتم تعيين HyperParameters ل LLAMA3-8B على النحو التالي:
| المعلمة | جلسة |
|---|---|
| مُحسّن | آدم |
| معدل التعلم | 5e-5 |
| حجم الدُفعة | 5 |
| الحقبة | 3 |
| رتبة لورا | 8 |
| خطوات تراكم التدرج | 4 |
| الحد الأقصى طول | 512 |
تم تدريب النموذج على استخدام Adam Optimizer ، المعروف بقدرات معدل التعلم التكيفية. يتم استخدام جدول معدل تعلم جيب التمام لضبط معدل التعلم أثناء التدريب. يتم تعيين حجم الدُفعة على 5 ، مع تراكم التدرج على أكثر من 4 خطوات لتحسين استخدام الذاكرة. تم تدريب النموذج على 3 عصر ، مع استخدام تنسيق الدقة FP16 لحفظ ذاكرة GPU مع الحفاظ على الأداء. تشير رتبة Lora من 8 إلى ترتيب المصفوفة منخفضة الرتبة المستخدمة في عملية التكيف.
المقياس الأساسي المستخدم لتقييم أداء النموذج هو الدقة. يقيس هذا المقياس نسبة التنبؤات الصحيحة التي قام بها النموذج من بين جميع التنبؤات. صيغة الدقة هي:
أين:
تتم مقارنة أداء النموذج مع نماذج NLP الشهيرة الأخرى ، مثل Bert-Base و Bert-Large و Roberta-Base و Roberta-Large. يحقق طراز LLAMA3-8B أعلى دقة قدره 0.9262 ، مما يدل على فعالية تعليمات ضبط الدقة ومجموعة المعلمات الكبيرة للنموذج. يؤكد الأداء المتفوق لـ llama3-8b في هذه المهمة على مزايا نماذج اللغة الكبيرة في تحقيق دقة عالية عبر مهام تصنيف النص المتنوعة والصعبة.
| نموذج | دقة |
|---|---|
| bert-base | 0.9063 |
| بيرت large | 0.9086 |
| روبرتا قاعدة | 0.9125 |
| روبرتا لارج | 0.9189 |
| Llama3-8b | 0.9262 |
يوضح هذا المشروع إمكانات نماذج اللغة الكبيرة ، مثل LLAMA3-8B ، في المهام الخاصة بالمجال مثل تصنيف نص العاطفة. يؤكد أداء النموذج ، الذي يعززه تقنيات متخصصة مثل Lora و Flashattention ، على فعالية النماذج الكبيرة في تحقيق دقة عالية في تطبيقات NLP.
تم ترخيص هذا المشروع بموجب ترخيص Apache 2.0 - راجع ملف الترخيص للحصول على التفاصيل.
يعتمد هذا المشروع على تعديلات على العمل الأصلي المتاح بموجب Llama-Factory ، وهو مرخص بموجب ترخيص Apache 2.0.
للحصول على أي أسئلة أو مشكلات ، يرجى الاتصال بـ Daoyuan Li على [email protected].


