Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
Ce projet explore la classification du texte des émotions à l'aide du modèle LLAMA3-8B, améliorée avec les techniques LORA et Flashattention. Le modèle est optimisé pour identifier six catégories d'émotions: la joie, la tristesse, la colère, la peur, l'amour et la surprise. Le modèle LLAMA3-8B démontre des performances supérieures avec une précision de 0,9262, dépassant d'autres modèles de transformateurs tels que Bert-base, Bert-Large, Roberta-Base et Roberta-Large.
Le traitement du langage naturel (PNL) est devenu un domaine de mise au point clé pour l'analyse des sentiments, également connue sous le nom de classification des sentiments ou de détection des sentiments. Cette technologie aide les entreprises à comprendre les émotions et les opinions des consommateurs, améliorant la satisfaction des clients et le développement de produits. La grande quantité de données dans les grandes entreprises rend l'analyse manuelle impraticable, conduisant à l'adoption des algorithmes d'IA et de PNL.
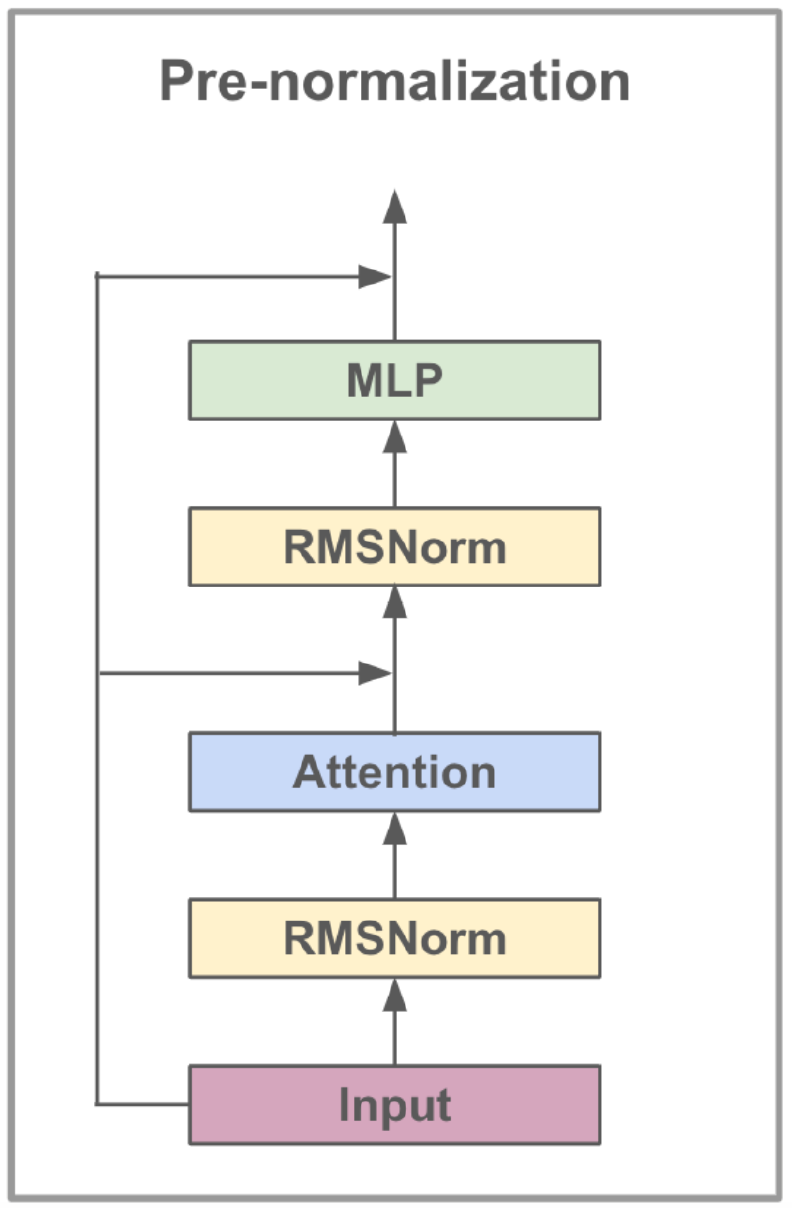
Le modèle LLAMA3-8B, développé par Meta AI, est un modèle de langue large optimisé pour les cas d'utilisation du dialogue. Il contient 8 milliards de paramètres et présente des améliorations significatives par rapport aux modèles précédents. La série LLAMA3 intègre un processus de formation multi-phases qui comprend une pré-entraînement, un réglage fin supervisé et un raffinement itératif en utilisant l'apprentissage du renforcement avec la rétroaction humaine (RLHF). Ce processus garantit que le modèle s'aligne étroitement avec les préférences humaines pour l'aide et la sécurité.
Les progrès architecturaux de LLAMA3 incluent la mise en œuvre de l'attention groupée (GQA). GQA Clusters Requêtes pour partager les paires de valeurs clés, réduisant ainsi la mémoire et les coûts de calcul tout en maintenant des performances élevées. Cette méthode améliore considérablement l'efficacité des calculs d'attention, en particulier dans les modèles à grande échelle.
LLAMA3-8B est pré-entraîné sur un ensemble de données diversifié comprenant plus de 15 billions de jetons provenant de données accessibles au public, avec le coupure des connaissances du modèle fixé en mars 2023. La phase de réglage fin a utilisé une compréhension robuste des deux tâches linguistiques.
| Fonctionnalité | Spécification |
|---|---|
| Données de formation | Données accessibles au public |
| Paramètres | 8b |
| Durée du contexte | 8K |
| GQA | Oui |
| Dénombrement de jetons | 15T + |
| Coupure de connaissances | Mars 2023 |
Le réglage fin des instructions améliore les capacités d'apprentissage zéro du modèle à travers diverses tâches. Cette technique consiste à former le modèle sur les ensembles de données spécialement conçus pour améliorer sa capacité à suivre les instructions. Par exemple, des modèles formés sur des ensembles de données comme Alpaca-7B peuvent présenter des comportements similaires à Text-Davinci-003 d'OpenAI pour comprendre et exécuter des instructions.
LORA (adaptation de faible rang) est une technique utilisée pour intégrer les matrices de décomposition de rang entraînable dans chaque couche de l'architecture du transformateur. Cette méthode réduit considérablement le nombre de paramètres formables lors de l'adaptation de modèles de langage à grande envergure à des tâches ou des domaines spécifiques. Contrairement au réglage fin complet, Lora maintient les poids du modèle pré-entraînés inchangés, mettant à jour uniquement les matrices de bas rang pendant le processus d'adaptation. Cette approche améliore l'efficacité de la formation, réduit les besoins de stockage et n'augmente pas la latence d'inférence par rapport aux modèles entièrement affinés.
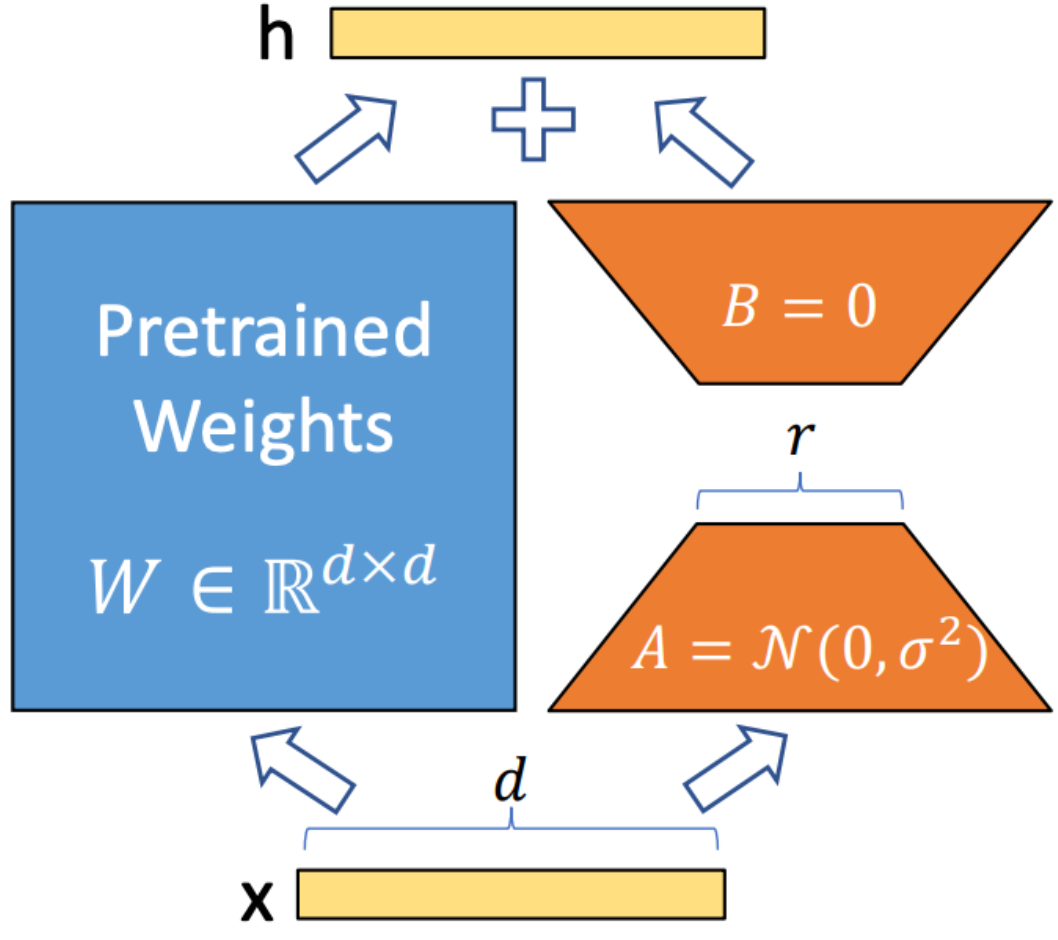
FlashAntiser V2 est une technique d'optimisation conçue pour accélérer le mécanisme d'attention dans les modèles de transformateurs. Il se concentre sur l'amélioration de l'efficacité de calcul et la réduction de l'utilisation de la mémoire pendant la formation. Flashattention y parvient en décomposant le calcul de l'attention en morceaux plus petits et plus gérables, améliorant ainsi l'utilisation du cache et réduisant l'accès à la mémoire. De plus, il utilise des opérations de matrice clairsemées pour tirer parti de la rareté des mécanismes d'attention, ce qui aide à contourner les calculs inutiles. Les opérations pipelinées permettent l'exécution parallèle de différentes étapes de calcul, minimisant davantage le temps de traitement.
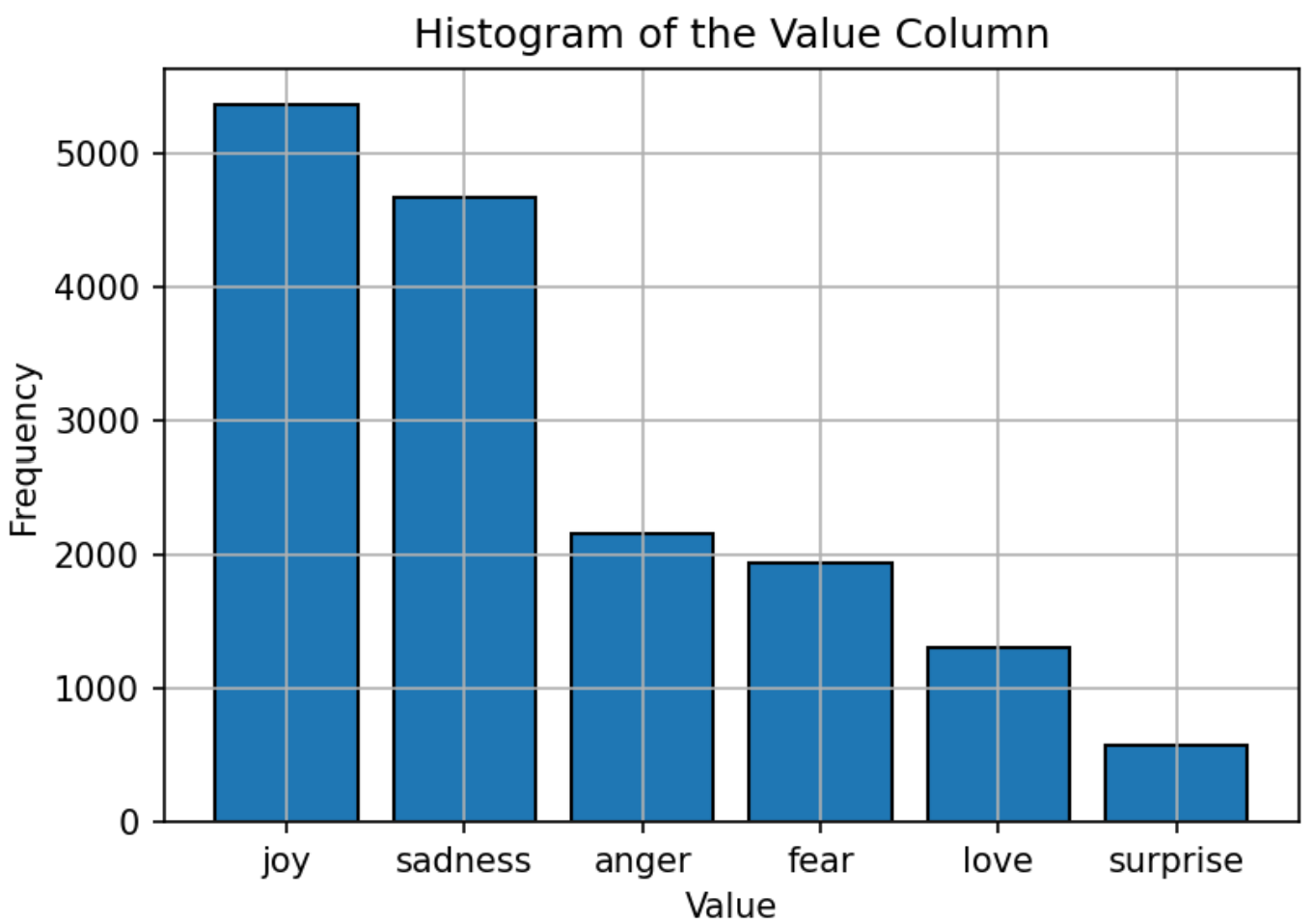
L'ensemble de données utilisé pour la formation du modèle se compose de texte étiqueté avec six émotions: joie, tristesse, colère, peur, amour et surprise. La distribution de l'ensemble de données est relativement équilibrée, la «joie» étant l'émotion la plus courante et la «surprise» le moins. Cette distribution équilibrée fournit une base solide pour le modèle pour classer avec précision les émotions sans biais vers une catégorie particulière.
Les hyperparamètres du modèle LLAMA3-8B sont définis comme suit:
| Paramètre | Paramètre |
|---|---|
| Optimiseur | Adam |
| Taux d'apprentissage | 5E-5 |
| Taille de lot | 5 |
| Époques | 3 |
| Rang lora | 8 |
| Étapes d'accumulation de gradient | 4 |
| Longueur maximale | 512 |
Le modèle est formé à l'aide de l'ADAM Optimizer, connu pour ses capacités de taux d'apprentissage adaptatif. Un calendrier de taux d'apprentissage en cosinus est utilisé pour ajuster le taux d'apprentissage pendant la formation. La taille du lot est définie sur 5, avec une accumulation de gradient sur 4 étapes pour optimiser l'utilisation de la mémoire. Le modèle est formé pour 3 époques, avec le format de précision FP16 utilisé pour enregistrer la mémoire GPU tout en maintenant les performances. Le rang LORA de 8 indique l'ordre de la matrice de bas rang utilisée dans le processus d'adaptation.
La métrique principale utilisée pour évaluer les performances du modèle est la précision. Cette métrique mesure la proportion de prédictions correctes faites par le modèle à partir de toutes les prédictions. La formule de précision est:
Où:
Les performances du modèle sont comparées à d'autres modèles PNL populaires, tels que Bert-Base, Bert-Garn, Roberta-Base et Roberta-Large. Le modèle LLAMA3-8B atteint la précision la plus élevée de 0,9262, démontrant l'efficacité du réglage fin de l'instruction et le grand ensemble de paramètres du modèle. La performance supérieure de LLAMA3-8B dans cette tâche souligne les avantages des modèles de grandes langues pour atteindre une grande précision à travers des tâches de classification de texte diverses et difficiles.
| Modèle | Précision |
|---|---|
| Bascule | 0,9063 |
| Bert-grand | 0,9086 |
| Base de Roberta | 0,9125 |
| Plus grand | 0,9189 |
| Llama3-8b | 0,9262 |
Ce projet démontre le potentiel de modèles de grandes langues, tels que LLAMA3-8B, dans des tâches spécifiques au domaine comme la classification du texte des émotions. Les performances du modèle, stimulées par des techniques spécialisées comme LORA et Flashattention, soulignent l'efficacité des grands modèles pour atteindre une grande précision dans les applications PNL.
Ce projet est concédé sous licence Apache 2.0 - Voir le fichier de licence pour plus de détails.
Ce projet est basé sur des modifications des travaux originaux disponibles sous Llama-Factory, qui est concédé sous licence Apache 2.0.
Pour toute question ou problème, veuillez contacter Daoyuan Li à [email protected].


