Llama3 8B_Emotion_Text_Classification_LoRA
1.0.0
Этот проект исследует классификацию текста эмоций с использованием модели Llama3-8B, улучшенной с помощью LORA и методов вспышки. Модель оптимизирована для определения шести категорий эмоций: радость, грусть, гнев, страх, любовь и удивление. Модель Llama3-8B демонстрирует превосходную производительность с точностью 0,9262, превзойдя другие модели трансформатора, такие как BERT-Base, Bert-Large, Roberta-Base и Roberta-Large.
Обработка естественного языка (NLP) стала ключевой целью для анализа настроений, также известной как классификация настроений или обнаружение настроений. Эта технология помогает предприятиям понять потребительские эмоции и мнения, повышая удовлетворенность клиентов и разработку продукта. Огромное количество данных в крупных компаниях делает ручной анализ непрактичным, что приводит к принятию алгоритмов ИИ и НЛП.
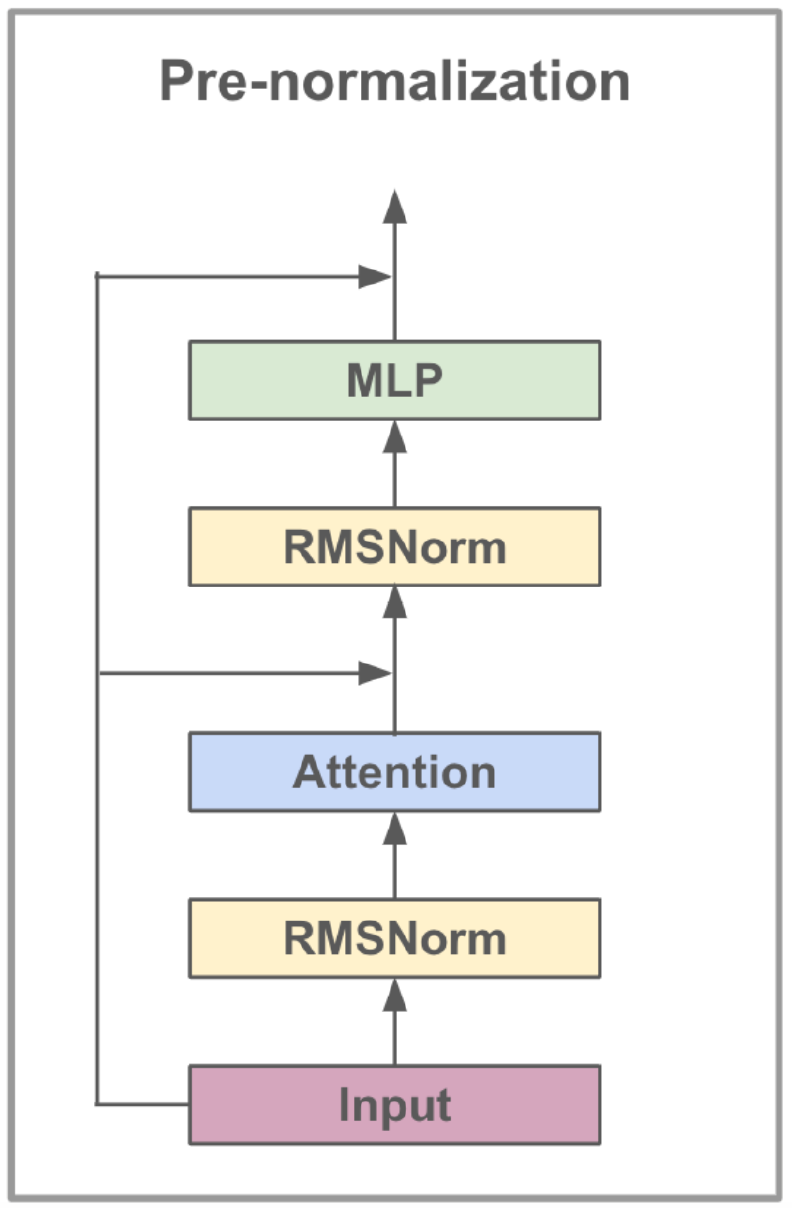
Модель Llama3-8B, разработанная Meta AI, представляет собой большую языковую модель, оптимизированную для вариантов использования диалога. Он содержит 8 миллиардов параметров и имеет значительные улучшения по сравнению с предыдущими моделями. Серия Llama3 включает в себя многофазный процесс обучения, который включает в себя предварительную подготовку, контролируемую тонкую настройку и итеративную уточнение с использованием обучения подкреплению с обратной связью с человеком (RLHF). Этот процесс гарантирует, что модель тесно связана с предпочтениями человека для полезности и безопасности.
Архитектурные достижения в LLAMA3 включают в себя реализацию внимания группированного цикла (GQA). Кластеры GQA запрашиваются, чтобы разделить пары ключевых значений, тем самым снижая память и вычислительные затраты, сохраняя при этом высокую производительность. Этот метод значительно повышает эффективность расчетов внимания, особенно в крупномасштабных моделях.
LLAMA3-8B предварительно подготовлен в разнообразном наборе данных, включающем более 15 триллионов токенов из общедоступных данных, причем снятие знаний модели в марте 2023 года. Фаза с тонкой настройкой, используемая общедоступными наборами данных инструкции и более 10 миллионов примеров, аннотируемых на человека, обеспечивав надежное понимание различных языковых наборов.
| Особенность | Спецификация |
|---|---|
| Данные обучения | Общедоступные данные |
| Параметры | 8B |
| Контекст длины | 8к |
| GQA | Да |
| Подсчет жетонов | 15t+ |
| Отказ знания | Март 2023 г. |
Инструкция тонкая настройка расширяет возможности обучения с нулевым выстрелом модели в разных задачах. Этот метод включает в себя обучение модели на наборы данных, специально разработанных для улучшения его способности следовать инструкциям. Например, модели, обученные наборам данных, таким как Alpaca-7B, могут демонстрировать поведение, аналогичное текстовому Davinci-003 Openai, в понимании и выполнении инструкций.
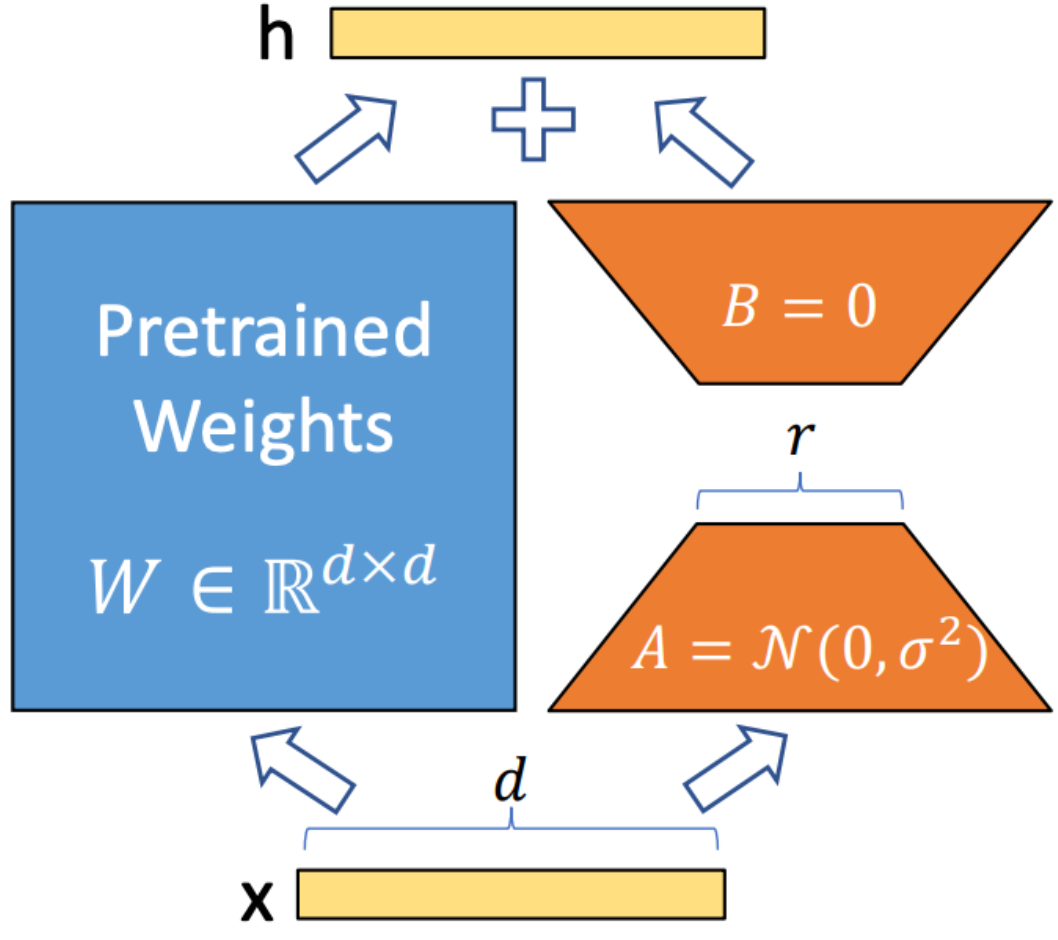
Лора (адаптация с низким уровнем ранга)-это метод, используемый для интеграции матриц декомпозиции обучения в каждый слой архитектуры трансформатора. Этот метод значительно уменьшает количество обучаемых параметров, адаптируя большие языковые модели к конкретным задачам или доменам. В отличие от полной точной настройки, Лора сохраняет предварительную модель без изменений, обновляя только матрицы с низким рейтингом в процессе адаптации. Этот подход повышает эффективность обучения, снижает потребности в хранении и не увеличивает задержку вывода по сравнению с полностью тонкими моделями.
Flashattention V2 - это метод оптимизации, предназначенный для ускорения механизма внимания в моделях трансформатора. Он фокусируется на повышении вычислительной эффективности и снижении использования памяти во время обучения. Flashattunition достигает этого, разбивая вычисление внимания на более мелкие, более управляемые куски, тем самым усиливая использование кэша и уменьшая доступ к памяти. Кроме того, он использует редкие операции матрицы, чтобы использовать разреженность в механизмах внимания, что помогает обходить ненужные вычисления. Конвейерные операции позволяют параллельно выполнять различные этапы вычисления, еще больше минимизируя время обработки.
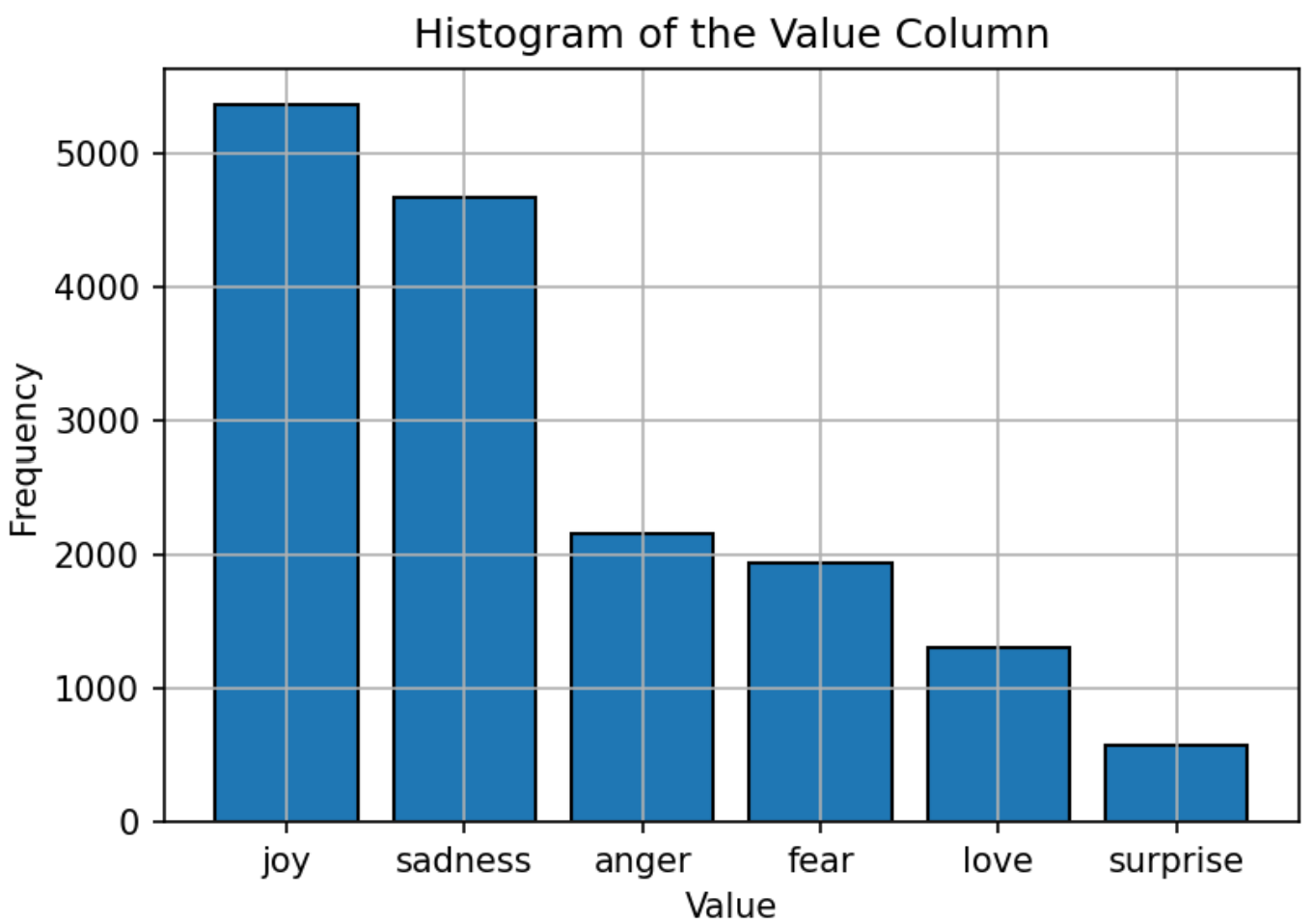
Набор данных, используемый для обучения модели, состоит из текста, помеченного шестью эмоциями: радость, грусть, гнев, страх, любовь и удивление. Распределение набора данных относительно сбалансировано: «радость» является наиболее распространенной эмоцией и «удивлением». Это сбалансированное распределение обеспечивает прочную основу для модели для точной классификации эмоций без предвзятости к какой -либо конкретной категории.
Гиперпараметры модели Llama3-8B установлены следующим образом:
| Параметр | Параметр |
|---|---|
| Оптимизатор | Адам |
| Скорость обучения | 5e-5 |
| Размер партии | 5 |
| Эпохи | 3 |
| Лора звание | 8 |
| Градиентные шаги накопления | 4 |
| Максимальная длина | 512 |
Модель обучается с использованием оптимизатора ADAM, известного своими адаптивными возможностями обучения. График ставки обучения косинуса используется для корректировки уровня обучения во время обучения. Размер партии устанавливается на 5, с накоплением градиента в течение 4 шагов для оптимизации использования памяти. Модель обучена для 3 эпох, с форматом точности FP16, используемом для сохранения памяти GPU при сохранении производительности. Ранг LORA 8 указывает на порядок матрицы с низким уровнем ранга, используемой в процессе адаптации.
Первичной метрикой, используемой для оценки производительности модели, является точность. Этот показатель измеряет долю правильных прогнозов, сделанных моделью из всех прогнозов. Формула для точности:
Где:
Производительность модели сравнивается с другими популярными моделями NLP, таких как Bert-Base, Bert-Large, Roberta-Base и Roberta-Large. Модель Llama3-8B достигает самой высокой точности 0,9262, демонстрируя эффективность тонкой настройки обучения и набора большого набора параметров модели. Высшая производительность Llama3-8B в этой задаче подчеркивает преимущества крупных языковых моделей в достижении высокой точности в разных и сложных задачах классификации текста.
| Модель | Точность |
|---|---|
| Берт-баз | 0,9063 |
| Берт-широкий | 0,9086 |
| Роберта-баз | 0,9125 |
| Роберта-Ларж | 0,9189 |
| Llama3-8b | 0,9262 |
Этот проект демонстрирует потенциал крупных языковых моделей, таких как Llama3-8B, в зависимости от доменных задач, таких как классификация текста эмоций. Производительность модели, повышенная специализированными методами, такими как Lora и Flashattention, подчеркивает эффективность крупных моделей в достижении высокой точности в приложениях NLP.
Этот проект лицензирован по лицензии Apache 2.0 - см. Файл лицензии для получения подробной информации.
Этот проект основан на модификациях оригинальной работы, доступной в рамках Llama-Factory, которая лицензирована в соответствии с лицензией Apache 2.0.
По любым вопросам или вопросам, пожалуйста, свяжитесь с Daoyuan Li по адресу [email protected].


