Podfai
แอพนี้อนุญาตให้ผู้ใช้สร้างเนื้อหาในรูปแบบของพอดคาสต์ตามไฟล์ที่ให้ไว้ ตัวอย่างบางส่วนจะจัดให้มีการบรรยายการบรรยายคำอธิบายโครงการประวัติส่วนตัวหรืออื่น ๆ อีกมากมาย
ฉันยังเขียนโพสต์บล็อกเพื่อพูดคุยเกี่ยวกับโครงการนี้ตรวจสอบให้แน่ใจว่าได้ตรวจสอบ " วิธีใช้ Generative AI เพื่อสร้างเนื้อหาสไตล์พอดคาสต์จากอินพุตใด ๆ "
มันทำงานอย่างไร
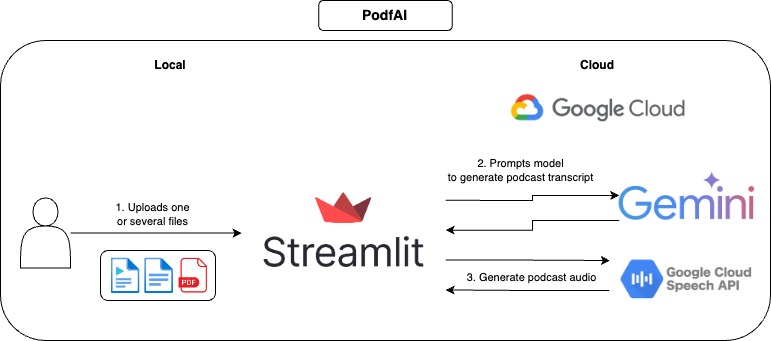
วิธีใช้
- ระบุไฟล์หนึ่งไฟล์ขึ้นไป
- เป็นทางเลือกปรับแต่งเสียงของแขกและโฮสต์คุณสามารถตรวจสอบตัวอย่างเสียงได้ที่นี่
- คลิกที่ "สร้างพอดคาสต์" และรอสักครู่
- เล่นเสียงและอย่าลังเลที่จะติดตามการถอดเสียงที่เป็นข้อความ
ตัวอย่าง
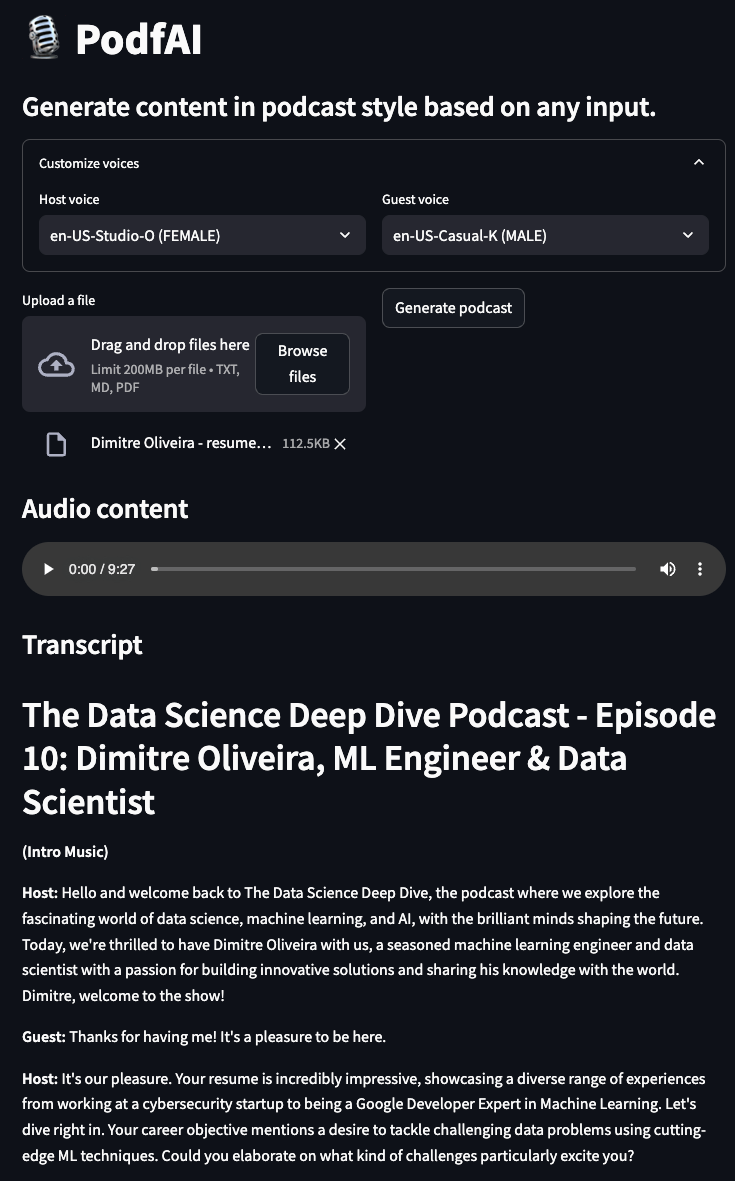
พอดคาสต์สร้างจากโครงการอื่น ๆ ของฉัน "AI Beats"
podcast-ai_beast.mp4
พอดคาสต์สร้างจากโครงการอื่น ๆ ของฉัน "AI Trailer"
podcast-ai_trailer.mp4
พอดคาสต์สร้างขึ้นจากคำอธิบาย "Morning Morning Morning Morning" ของ Andrew Huberman
พอดคาสต์ Andrew_hubermans.mp4
พอดคาสต์สร้างโดยประวัติส่วนตัว
Podcast-resume.mp4
การใช้งานท้องถิ่น
การตั้งค่า
- โคลนที่เก็บ GitHub
https://github.com/dimitreOliveira/PodfAI.git
cd PodfAI
- สร้าง venv ใหม่
python -m venv .venvs/podfai
- เปิดใช้งาน venv
source .venvs/podfai/bin/activate
- ติดตั้งข้อกำหนด
หรือคุณสามารถเรียกใช้โดยใช้ pip
pip install -r requirements
- ตั้งค่าการพึ่งพา Google API
- ทำตามคู่มือนี้หรืออีกเรื่องนี้
รันแอพ
ในการเริ่มต้นแอปให้เรียกใช้คำสั่ง Make ด้านล่าง
อีกทางเลือกหนึ่งคุณสามารถเรียกใช้โดยใช้ Python ธรรมดา
streamlit run src / app . py
กำหนดค่า
อย่าลังเลที่จะเปลี่ยนการกำหนดค่าเริ่มต้นเพื่อเปลี่ยนพฤติกรรมแอพหรือปรับให้เข้ากับความต้องการของคุณ
vertex:
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCATION}
transcript:
model_id: gemini-1.5-pro-002
transcript_len: 5000
max_output_tokens: 8192
temperature: 1
top_p: 0.95
top_k: 32
- จุดยอด
- โครงการ: ชื่อโครงการที่ใช้โดย Vertex AI
- สถานที่: ตำแหน่งโครงการที่ใช้โดย Vertex AI
- การถอดเสียง
- model_id: รุ่นที่ใช้ในการสร้าง Transcript Podcast
- transcript_len: ความยาวการถอดเสียงที่แนะนำ
- max_output_tokens: จำนวนสูงสุดของโทเค็นที่สร้างขึ้นโดยรุ่น
- อุณหภูมิ: อุณหภูมิควบคุมระดับของการสุ่มในการเลือกโทเค็น อุณหภูมิที่ต่ำกว่านั้นดีสำหรับการแจ้งเตือนที่คาดว่าจะมีการตอบสนองที่แท้จริงหรือถูกต้องในขณะที่อุณหภูมิที่สูงขึ้นสามารถนำไปสู่ผลลัพธ์ที่หลากหลายหรือไม่คาดคิดมากขึ้น ด้วยอุณหภูมิ 0 จะเลือกโทเค็นความน่าจะเป็นสูงสุดเสมอ
- TOP_P: TOP-P เปลี่ยนวิธีที่โมเดลเลือกโทเค็นสำหรับเอาต์พุต โทเค็นจะถูกเลือกจากความเป็นไปได้มากที่สุดอย่างน้อยที่สุดจนกว่าผลรวมของความน่าจะเป็นเท่ากับค่า Top-P ตัวอย่างเช่นหากโทเค็น A, B และ C มีความน่าจะเป็นที่. 3, .2 และ. 1 และค่าสูงสุด P คือ. 5 จากนั้นโมเดลจะเลือก A หรือ B เป็นโทเค็นถัดไป (ใช้อุณหภูมิ)
- TOP_K: Top-K เปลี่ยนวิธีที่โมเดลเลือกโทเค็นสำหรับเอาต์พุต Top-K ของ 1 หมายถึงโทเค็นที่เลือกนั้นเป็นไปได้มากที่สุดในบรรดาโทเค็นทั้งหมดในคำศัพท์ของโมเดล (เรียกอีกอย่างว่าการถอดรหัสโลภ) ในขณะที่ Top-K ของ 3 หมายความว่าโทเค็นถัดไปจะถูกเลือกจากโทเค็นที่น่าจะเป็นไปได้มากที่สุด 3 โท (โดยใช้อุณหภูมิ)
สิ่งที่ต้องทำ
- สนับสนุนการโคลนนิ่งเสียง
- สนับสนุนภาษาอื่น ๆ
- รองรับประเภทอินพุตอื่น ๆ (รูปภาพ, วิดีโอ, URL ของ YouTube)
- เพิ่มสมุดบันทึกตัวอย่างเพื่อทำงานใน colab
- ทำซ้ำเวิร์กโฟลว์ด้วยโมเดลโอเพนซอร์ซ
- ทดลองกับเวิร์กโฟลว์ตัวแทนเพื่อปรับปรุงการถอดเสียงพอดคาสต์
การอ้างอิง
- Google Cloud-ไลบรารีไคลเอนต์ข้อความเป็นคำพูด
- ตั้งค่า Google Cloud TTS ในเครื่อง
- รายการเสียงของ Google Cloud TTS
การบริจาค
หากคุณสนใจที่จะมีส่วนร่วมในโครงการนี้ขอบคุณมาก! ก่อนที่จะสร้างการประชาสัมพันธ์ของคุณตรวจสอบให้แน่ใจว่าผ้าสำลีของคุณเรียกใช้คำสั่งด้านล่าง:
กิตติกรรมประกาศ
- เครดิตของ Google Cloud มีไว้สำหรับโครงการนี้ โครงการนี้เป็นไปได้ด้วยการสนับสนุนทีมโปรแกรมนักพัฒนา ML ของ Google
- โครงการนี้ขึ้นอยู่กับสมุดบันทึกของ Google ซึ่งนอกเหนือจากเนื้อหาสไตล์พอดคาสต์แล้วยังมีคุณสมบัติอื่น ๆ อีกมากมายตรวจสอบให้แน่ใจว่าได้ตรวจสอบ


