Podfai
Aplikasi ini memungkinkan pengguna untuk membuat konten dengan gaya podcast berdasarkan file yang disediakan. Beberapa contoh akan menyediakan kertas, kuliah, deskripsi proyek, resume pribadi, atau banyak lainnya.
Saya juga menulis posting blog untuk membicarakan proyek ini, pastikan untuk memeriksa " cara menggunakan AI generatif untuk membuat konten gaya podcast dari input apa pun ".
Cara kerjanya
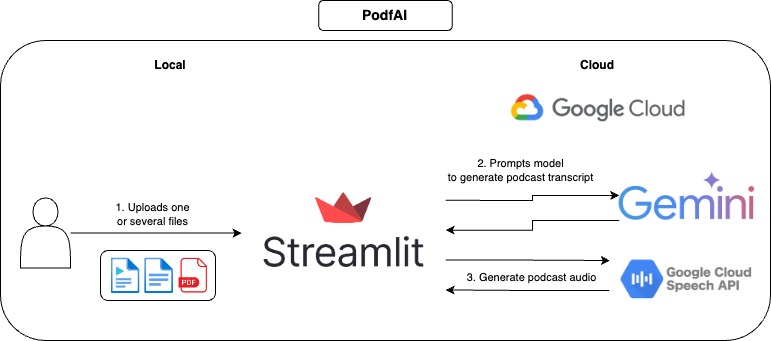
Cara menggunakan
- Berikan satu atau lebih file.
- Secara opsional, sesuaikan suara tamu dan host, Anda dapat memeriksa sampel suara di sini.
- Klik "Hasilkan Podcast" dan tunggu beberapa saat.
- Mainkan audio, dan jangan ragu untuk mengikuti transkrip tekstual.
Contoh
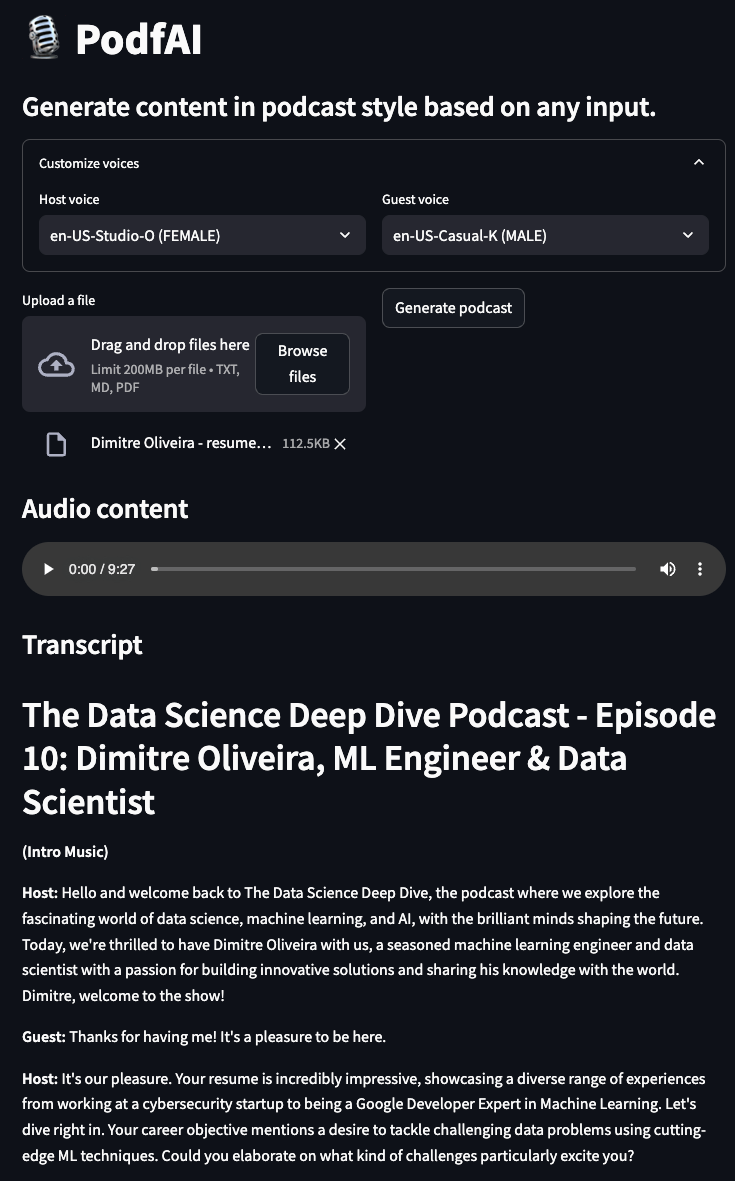
Podcast menghasilkan dari proyek saya yang lain "AI Beats"
podcast-ai_beast.mp4
Podcast menghasilkan dari proyek saya yang lain "AI Trailer"
podcast-ai_trailer.mp4
Podcast menghasilkan dari deskripsi "rutin pagi optimal" Andrew Huberman
podcast-andrew_hubermans.mp4
Podcast menghasilkan oleh resume pribadi
podcast-resume.mp4
Penggunaan lokal
Pengaturan
- Klon Repositori GitHub
https://github.com/dimitreOliveira/PodfAI.git
cd PodfAI
- Buat venv baru
python -m venv .venvs/podfai
- Aktifkan VENV
source .venvs/podfai/bin/activate
- Pasang persyaratan
Atau, Anda juga dapat menjalankan menggunakan pip
pip install -r requirements
- Siapkan dependensi Google API
- Ikuti panduan ini atau yang lainnya ini.
Menjalankan aplikasi
Untuk memulai aplikasi, jalankan perintah Make di bawah ini
Atau, Anda juga dapat berlari menggunakan ular python polos
streamlit run src / app . py
Konfigurasi
Jangan ragu untuk mengubah konfigurasi default untuk mengubah perilaku aplikasi atau menyesuaikan dengan kebutuhan Anda.
vertex:
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCATION}
transcript:
model_id: gemini-1.5-pro-002
transcript_len: 5000
max_output_tokens: 8192
temperature: 1
top_p: 0.95
top_k: 32
- puncak
- Proyek: Nama proyek yang digunakan oleh Vertex AI.
- Lokasi: Lokasi proyek yang digunakan oleh Vertex AI.
- salinan
- model_id: model yang digunakan untuk membuat transkrip podcast.
- Transcript_len: Panjang transkrip yang disarankan.
- MAX_OUTPUT_TOKENS: Jumlah token maksimum yang dihasilkan oleh model.
- Suhu: Suhu mengontrol tingkat keacakan dalam pemilihan token. Suhu yang lebih rendah baik untuk petunjuk yang mengharapkan respons yang benar atau benar, sementara suhu yang lebih tinggi dapat menyebabkan hasil yang lebih beragam atau tidak terduga. Dengan suhu 0 token probabilitas tertinggi selalu dipilih
- Top_p: Top-P mengubah cara model memilih token untuk output. Token dipilih dari kemungkinan paling tidak sampai jumlah probabilitasnya sama dengan nilai-P teratas. Misalnya, jika token A, B, dan C memiliki probabilitas .3, .2, dan .1 dan nilai-P teratas adalah .5, maka model akan memilih A atau B sebagai token berikutnya (menggunakan suhu)
- Top_K: Top-K mengubah cara model memilih token untuk output. Top-K dari 1 berarti token yang dipilih adalah yang paling mungkin di antara semua token dalam kosakata model (juga disebut decoding serakah), sedangkan top-K dari 3 berarti bahwa token berikutnya dipilih dari antara 3 token yang paling mungkin (menggunakan suhu)
Todo
- Mendukung kloning suara
- Mendukung bahasa lain
- Dukung jenis input lain (gambar, video, URL YouTube)
- Tambahkan contoh notebook untuk dijalankan di colab
- Reproduksi alur kerja dengan model open-source
- Eksperimen dengan alur kerja agen untuk meningkatkan transkrip podcast
Referensi
- Google Cloud-Perpustakaan Klien Teks-ke-Pidato
- Siapkan Google Cloud TTS secara lokal
- Daftar Suara Google Cloud TTS
Berkontribusi
Jika Anda tertarik untuk berkontribusi pada proyek ini, terima kasih banyak! Sebelum membuat PR Anda, pastikan untuk memasukkan kode Anda, menjalankan perintah di bawah ini:
Ucapan Terima Kasih
- Kredit Google Cloud disediakan untuk proyek ini. Proyek ini dimungkinkan berkat dukungan dari tim Program Pengembang ML Google.
- Proyek ini didasarkan pada notebooklm Google, yang, selain dari konten gaya podcast, memiliki banyak fitur lainnya, pastikan untuk memeriksanya.


