WaveGrad2
v1.0.0
การใช้ Pytorch ของ Google Brain's Wavegrad 2: การปรับแต่งซ้ำ ๆ สำหรับการสังเคราะห์แบบข้อความเป็นคำพูด
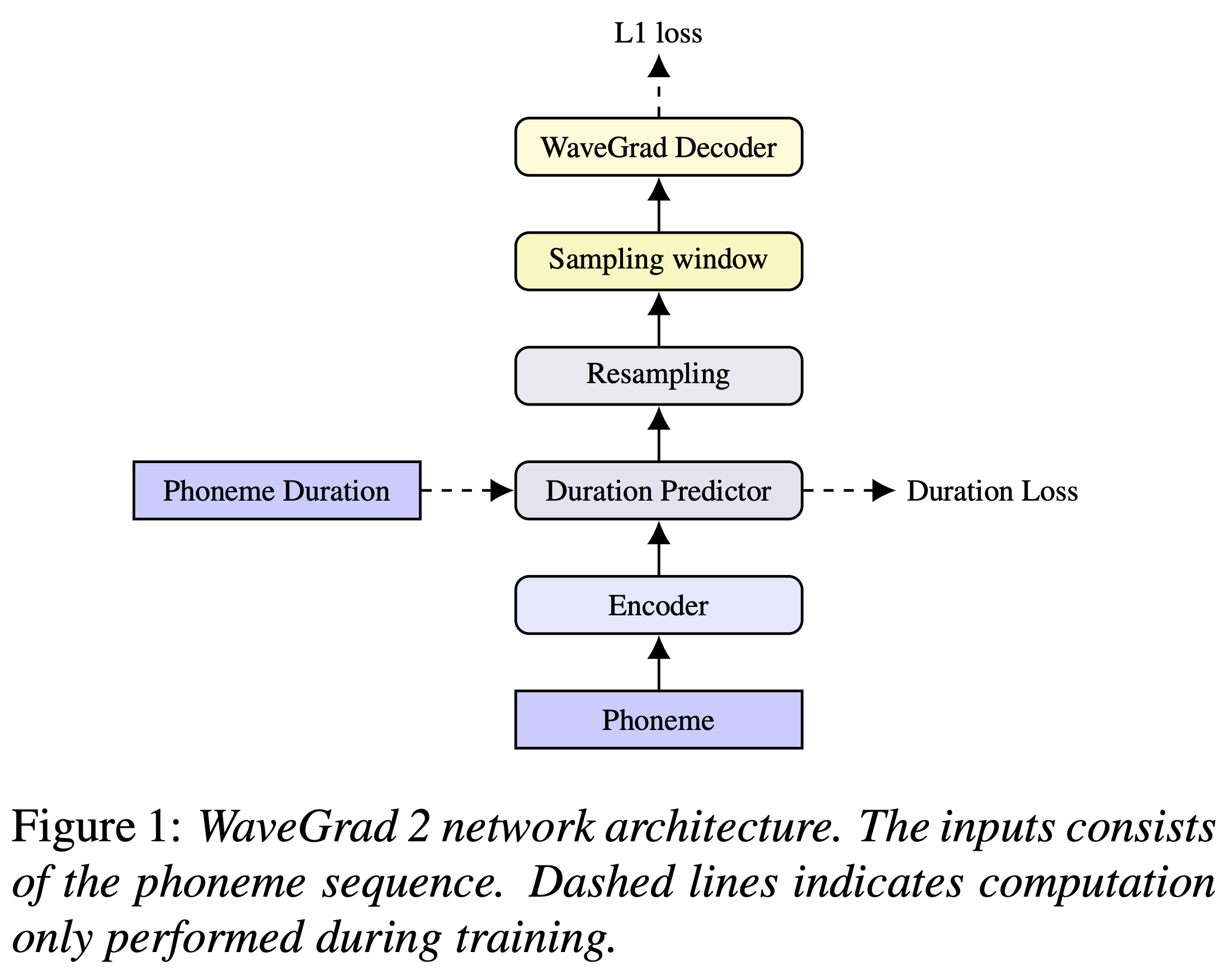
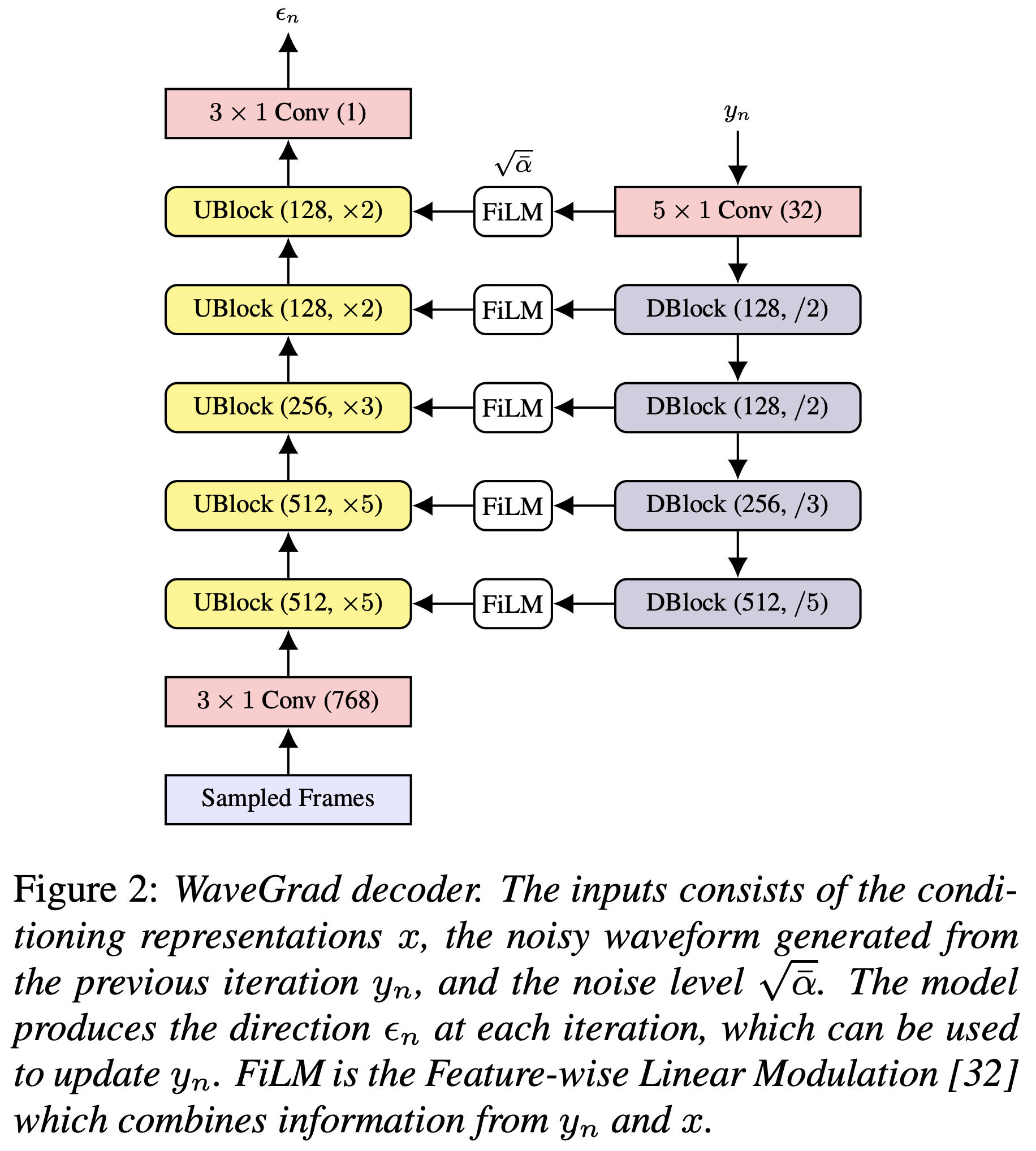
คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
คุณต้องดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมและวางไว้ใน output/ckpt/LJSpeech/
สำหรับ TTS ลำโพงเดี่ยวภาษาอังกฤษ Run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
คำพูดที่สร้างขึ้นจะถูกนำไปใช้ใน output/result/
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step RESTORE_STEP --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/LJSpeech/val.txt
อัตราการพูดของคำพูดสังเคราะห์สามารถควบคุมได้โดยการระบุอัตราส่วนระยะเวลาที่ต้องการ ตัวอย่างเช่นหนึ่งสามารถเพิ่มอัตราการพูดได้ 20 % โดย
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8
ชุดข้อมูลที่รองรับคือ
ก่อนอื่นวิ่ง
python3 prepare_align.py config/LJSpeech/preprocess.yaml
สำหรับการเตรียมการบางอย่าง
ตามที่อธิบายไว้ในกระดาษจะใช้ Montreal Forced Aligner (MFA) เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิม การจัดตำแหน่งสำหรับชุดข้อมูล LJSpeech มีให้ที่นี่ (ขอบคุณ FastSpeech2 ของ Ming024) คุณต้องคลายซิปไฟล์ใน preprocessed_data/LJSpeech/TextGrid/
หลังจากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้าโดย
python3 preprocess.py config/LJSpeech/preprocess.yaml
อีกวิธีหนึ่งคุณสามารถจัดเรียงคลังข้อมูลด้วยตัวเอง ดาวน์โหลดแพ็คเกจ MFA อย่างเป็นทางการและเรียกใช้
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
หรือ
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
เพื่อจัดแนวคลังข้อมูลแล้วเรียกใช้สคริปต์การประมวลผลล่วงหน้า
python3 preprocess.py config/LJSpeech/preprocess.yaml
ฝึกอบรมแบบจำลองของคุณด้วย
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
ใช้
tensorboard --logdir output/log/LJSpeech
เพื่อให้บริการ Tensorboard บนบ้านของคุณ เส้นโค้งการสูญเสีย mel-spectrograms สังเคราะห์และเสียงจะแสดง
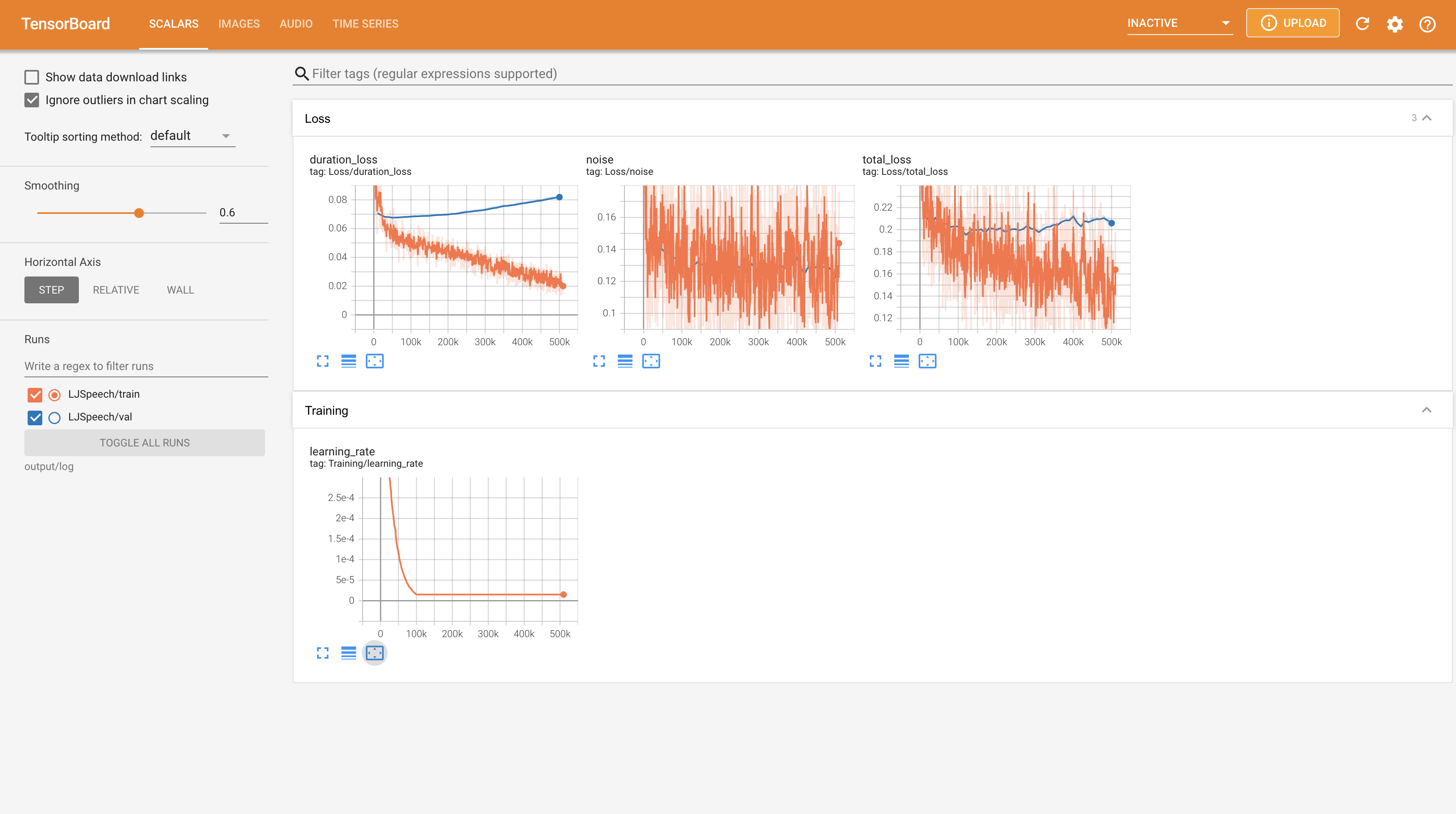
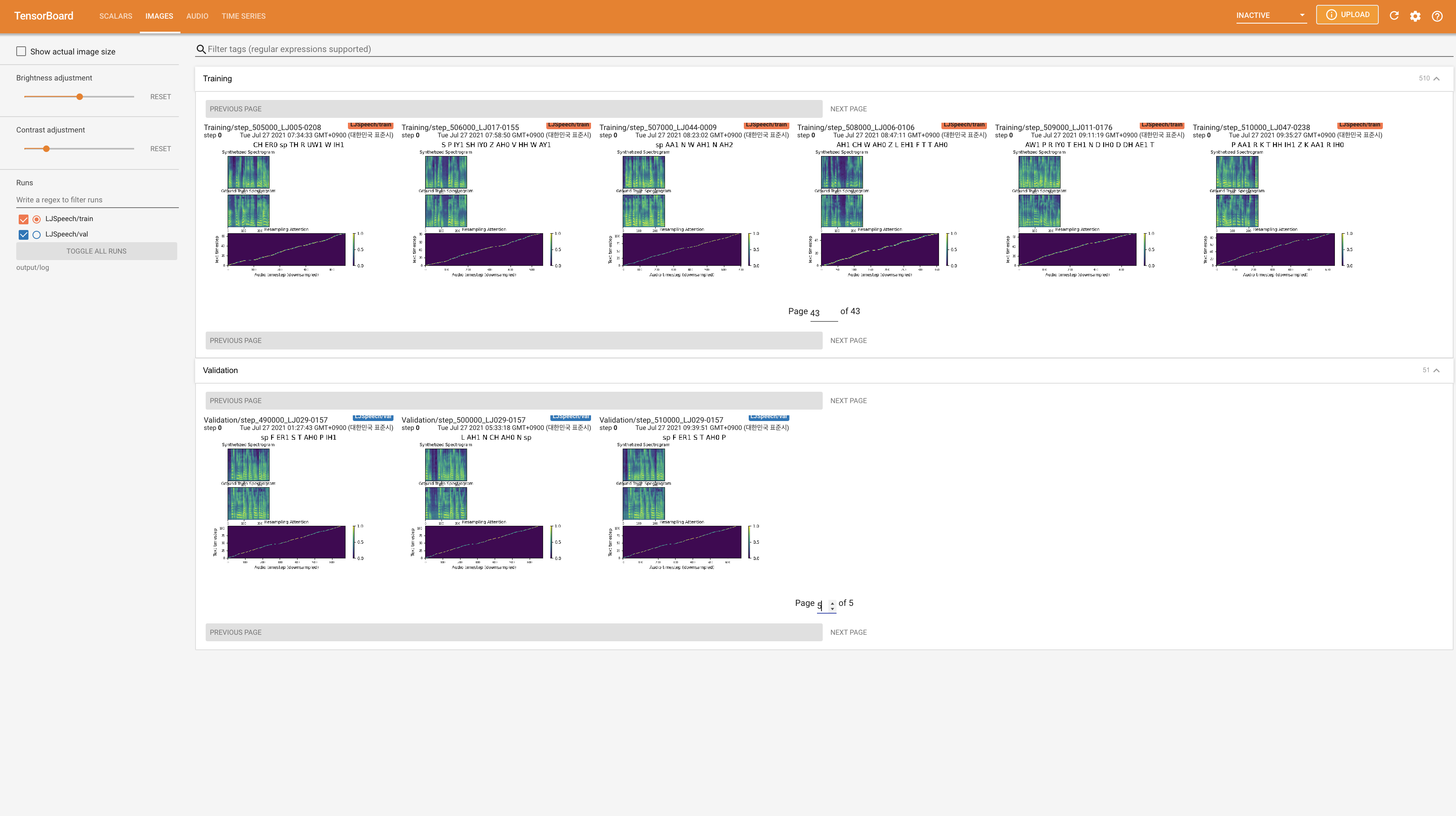
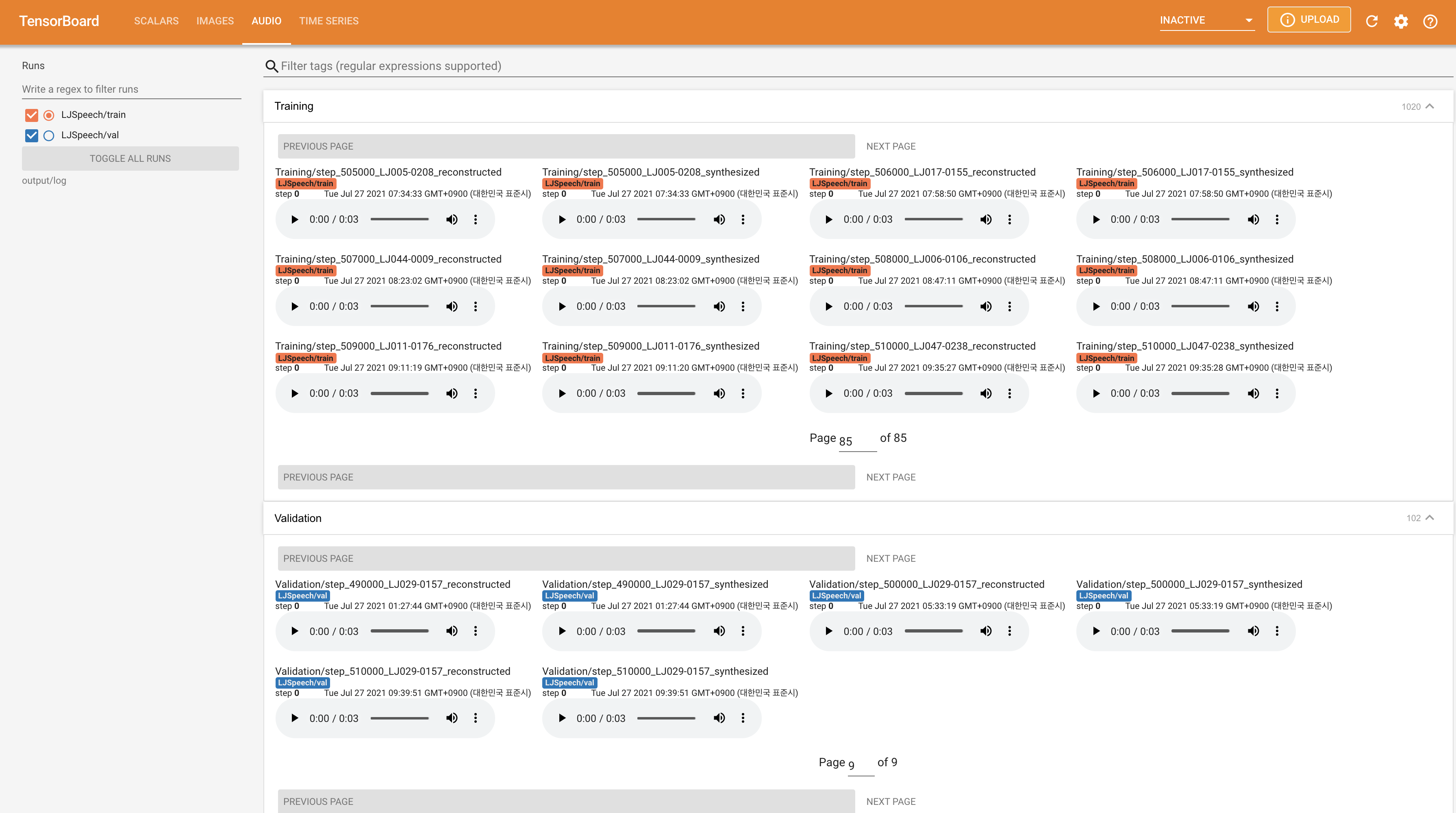
22050Hz แทน 24KHz และติดตามการกำหนดค่า LJSpeech ทั่วไปnn.LSTM แทน @misc{lee2021wavegrad2,
author = {Lee, Keon},
title = {WaveGrad2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/WaveGrad2}}
}


