WaveGrad2
v1.0.0
تنفيذ Pytorch لـ Google Brain's Wavegrad 2: التحسين التكراري لتوليف النص إلى الكلام.
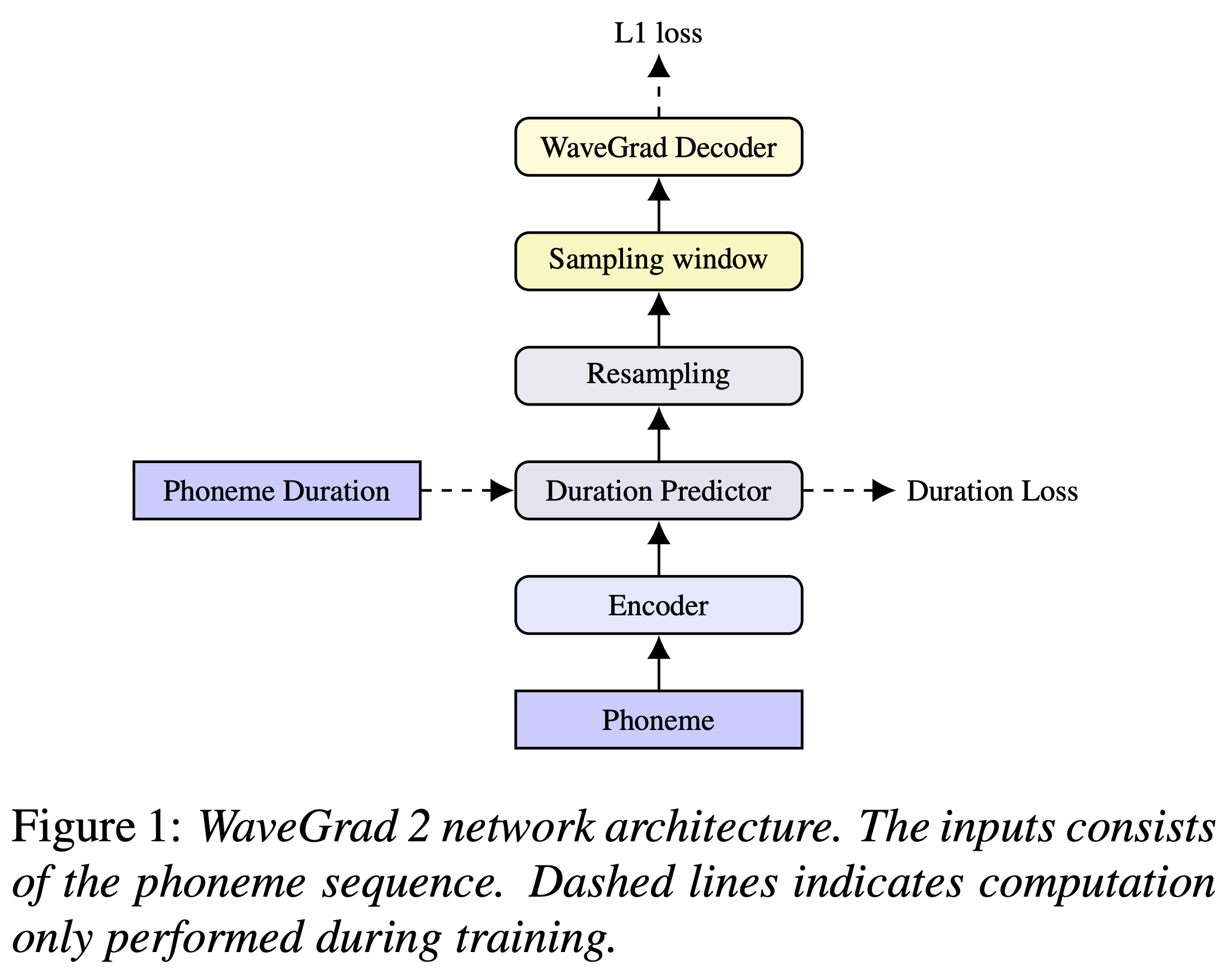
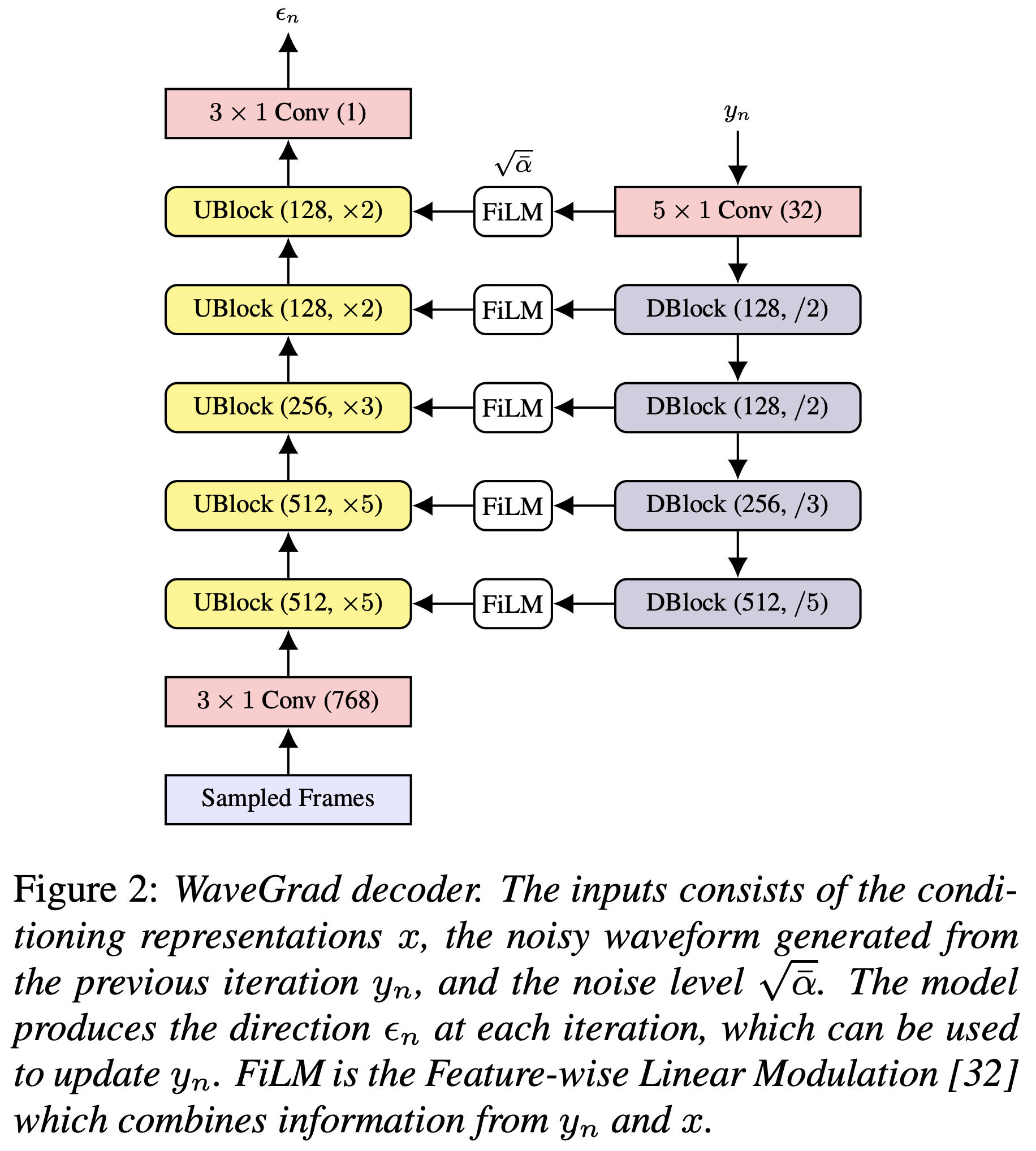
يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
يجب عليك تنزيل النماذج المسبقة ووضعها في output/ckpt/LJSpeech/ .
للحصول على TTS الفردية الإنجليزية ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
سيتم وضع الكلمات المولدة في output/result/ .
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step RESTORE_STEP --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
لتوليف جميع الكلمات في preprocessed_data/LJSpeech/val.txt
يمكن السيطرة على معدل التحدث للكلمات التوليف من خلال تحديد نسب المدة المطلوبة. على سبيل المثال ، يمكن للمرء زيادة معدل التحدث بنسبة 20 ٪
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8
مجموعات البيانات المدعومة
أولا ، الجري
python3 prepare_align.py config/LJSpeech/preprocess.yaml
لبعض الاستعدادات.
كما هو موضح في الورقة ، يتم استخدام Montreal القسري المحلي (MFA) للحصول على المحاذاة بين الكلمات وتسلسلات الصوت. يتم توفير محاذاة لمجموعات بيانات LJSpeech هنا (بفضل Ming024's fastspeade2). يجب عليك إلغاء ضغط الملفات في preprocessed_data/LJSpeech/TextGrid/ .
بعد ذلك ، قم بتشغيل البرنامج النصي المسبق
python3 preprocess.py config/LJSpeech/preprocess.yaml
بالتناوب ، يمكنك محاذاة المجموعة بنفسك. قم بتنزيل حزمة MFA الرسمية وتشغيلها
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
أو
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
لمحاذاة المجموعة ثم تشغيل البرنامج النصي المسبق.
python3 preprocess.py config/LJSpeech/preprocess.yaml
تدريب النموذج الخاص بك مع
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
يستخدم
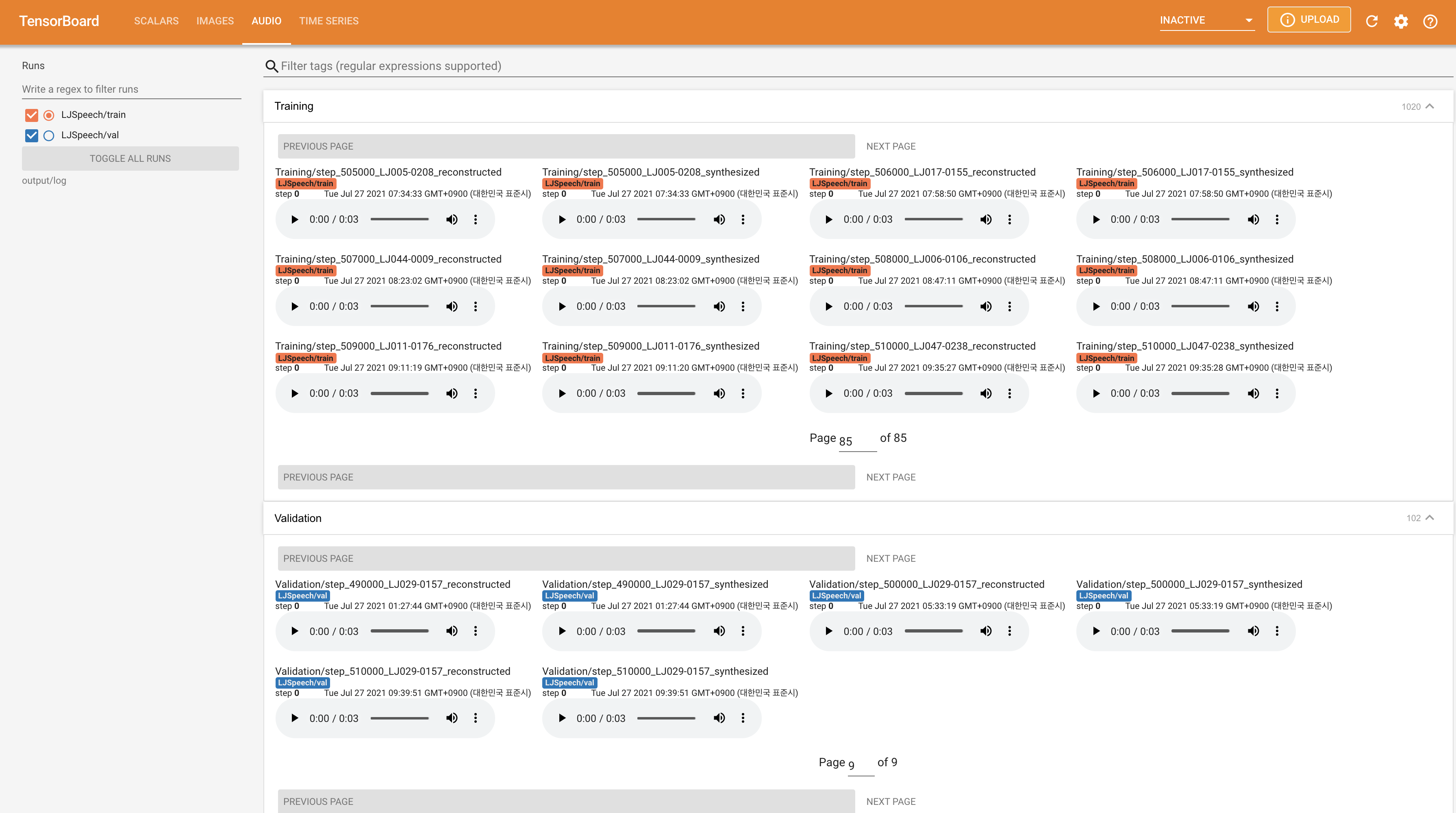
tensorboard --logdir output/log/LJSpeech
لخدمة Tensorboard على مضيفك المحلي. يتم عرض منحنيات الخسارة ، وتوليف الطيف الطيف ، والسمعات.
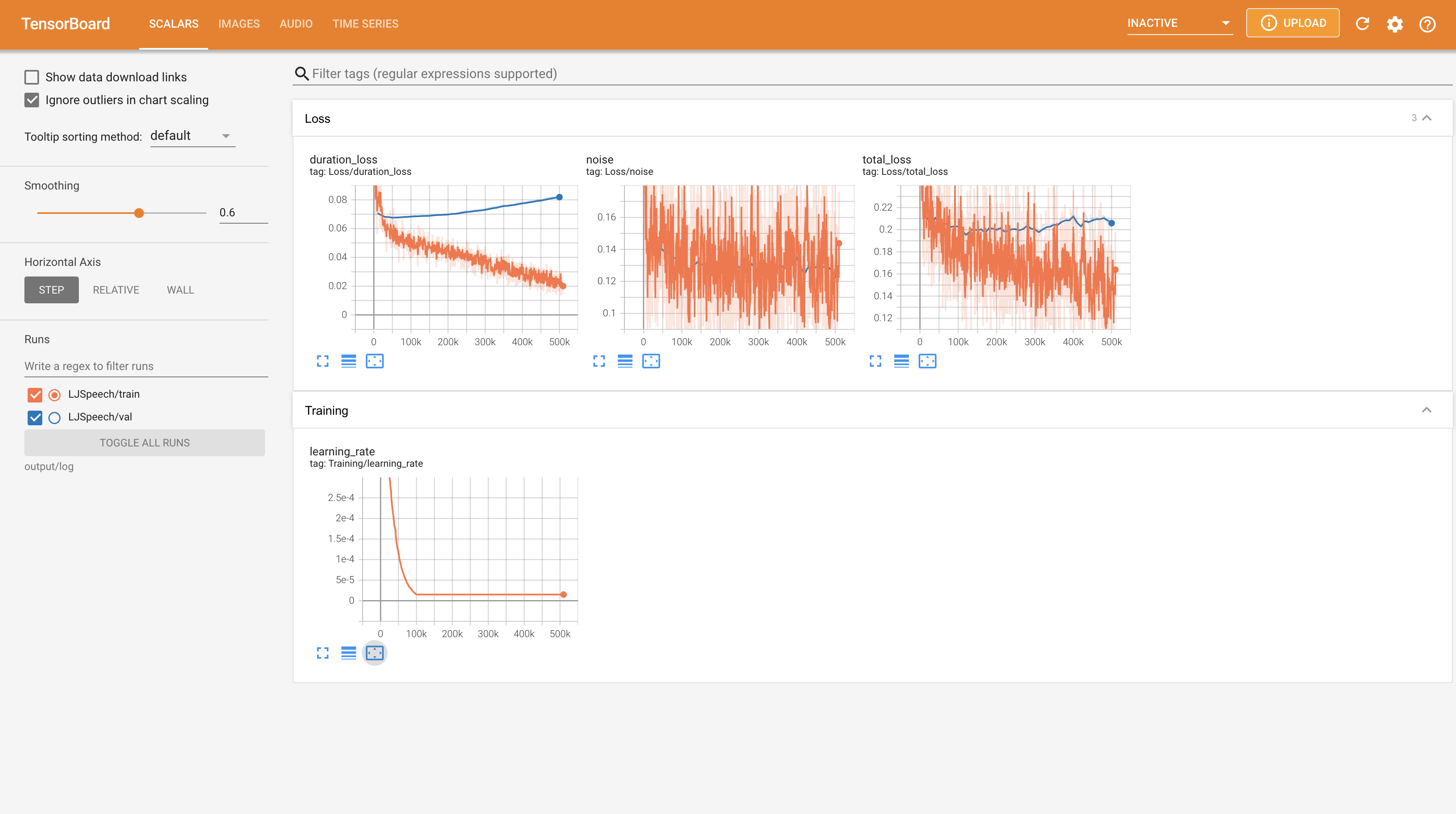
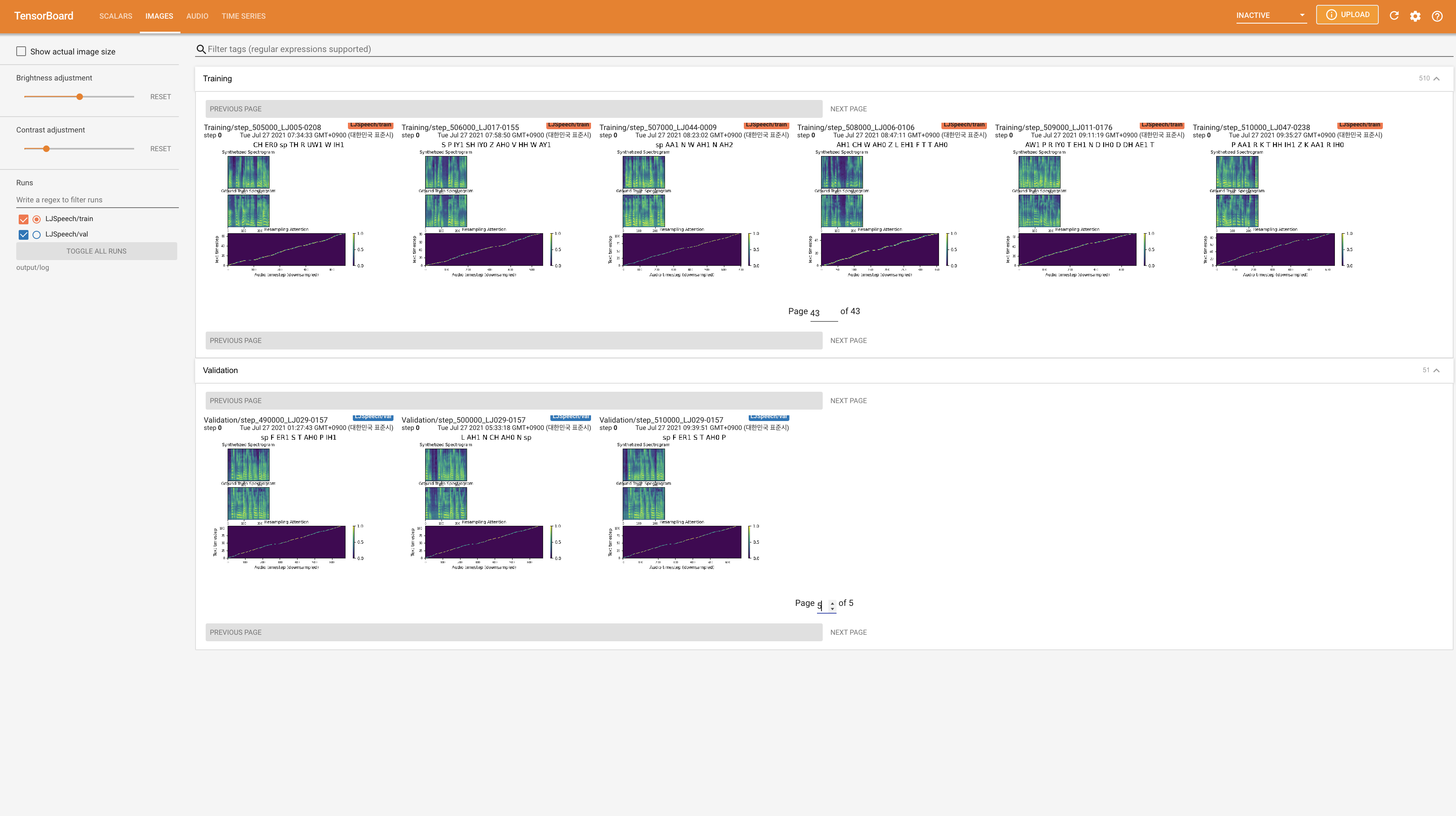
22050Hz بدلاً من 24KHz واتبع تكوينات LJSpeech العامة.nn.LSTM بدلاً من ذلك. @misc{lee2021wavegrad2,
author = {Lee, Keon},
title = {WaveGrad2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/WaveGrad2}}
}


