WaveGrad2
v1.0.0
Implementasi PyTorch dari Google Brain's Wavegrad 2: Penyempurnaan berulang untuk sintesis teks-ke-pidato.
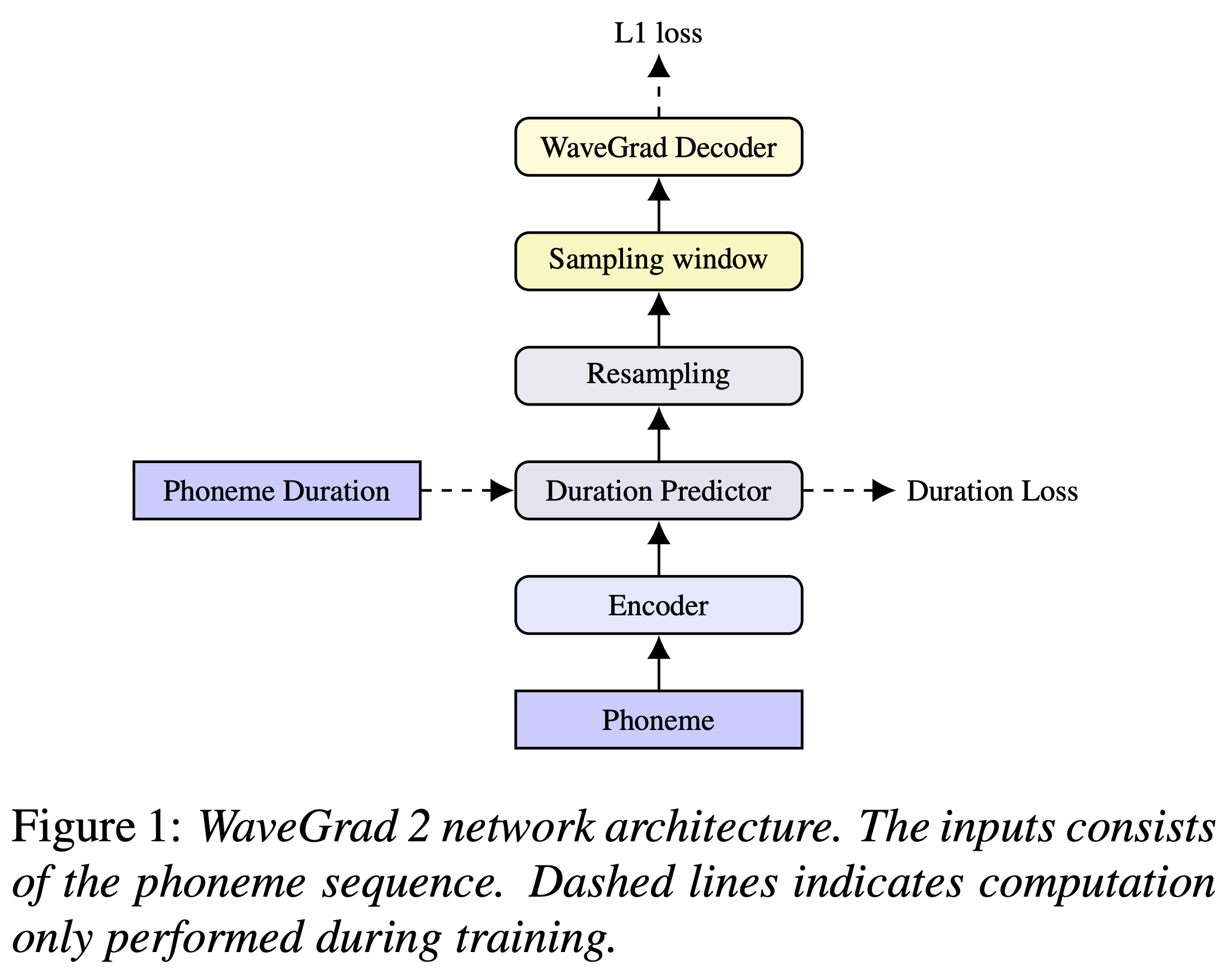
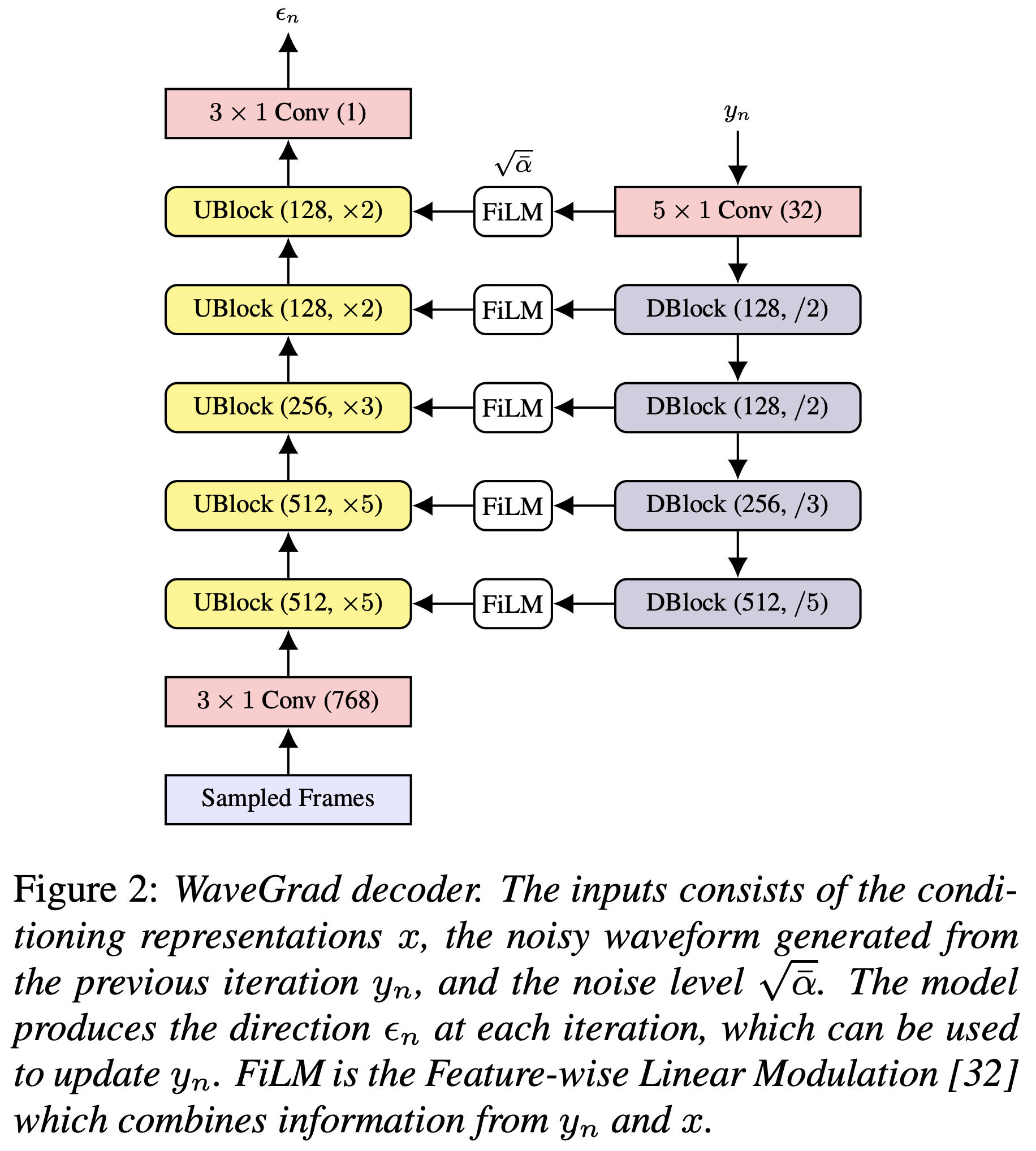
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
Anda harus mengunduh model pretrained dan memasukkannya ke dalam output/ckpt/LJSpeech/ .
Untuk TTS penutur tunggal bahasa Inggris, jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Ucapan yang dihasilkan akan dimasukkan ke dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step RESTORE_STEP --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Untuk mensintesis semua ucapan di preprocessed_data/LJSpeech/val.txt
Tingkat berbicara dari ucapan yang disintesis dapat dikontrol dengan menentukan rasio durasi yang diinginkan. Misalnya, seseorang dapat meningkatkan tingkat berbicara sebesar 20 %
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8
Dataset yang didukung adalah
Pertama, lari
python3 prepare_align.py config/LJSpeech/preprocess.yaml
untuk beberapa persiapan.
Seperti yang dijelaskan dalam makalah, Montreal memaksa Aligner (MFA) digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem. Penyelarasan untuk set data LJSPEECH disediakan di sini (terima kasih kepada FastSpeech2 Ming024). Anda harus membuka ritsleting file di preprocessed_data/LJSpeech/TextGrid/ .
Setelah itu, jalankan skrip preprocessing dengan
python3 preprocess.py config/LJSpeech/preprocess.yaml
Bergantian, Anda dapat menyelaraskan corpus sendiri. Unduh paket MFA resmi dan jalankan
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
atau
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
Untuk menyelaraskan corpus dan kemudian jalankan skrip preprocessing.
python3 preprocess.py config/LJSpeech/preprocess.yaml
Latih model Anda dengan
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Menggunakan
tensorboard --logdir output/log/LJSpeech
untuk melayani Tensorboard di Localhost Anda. Kurva kehilangan, sintesis mel-spectrograms, dan audio ditampilkan.
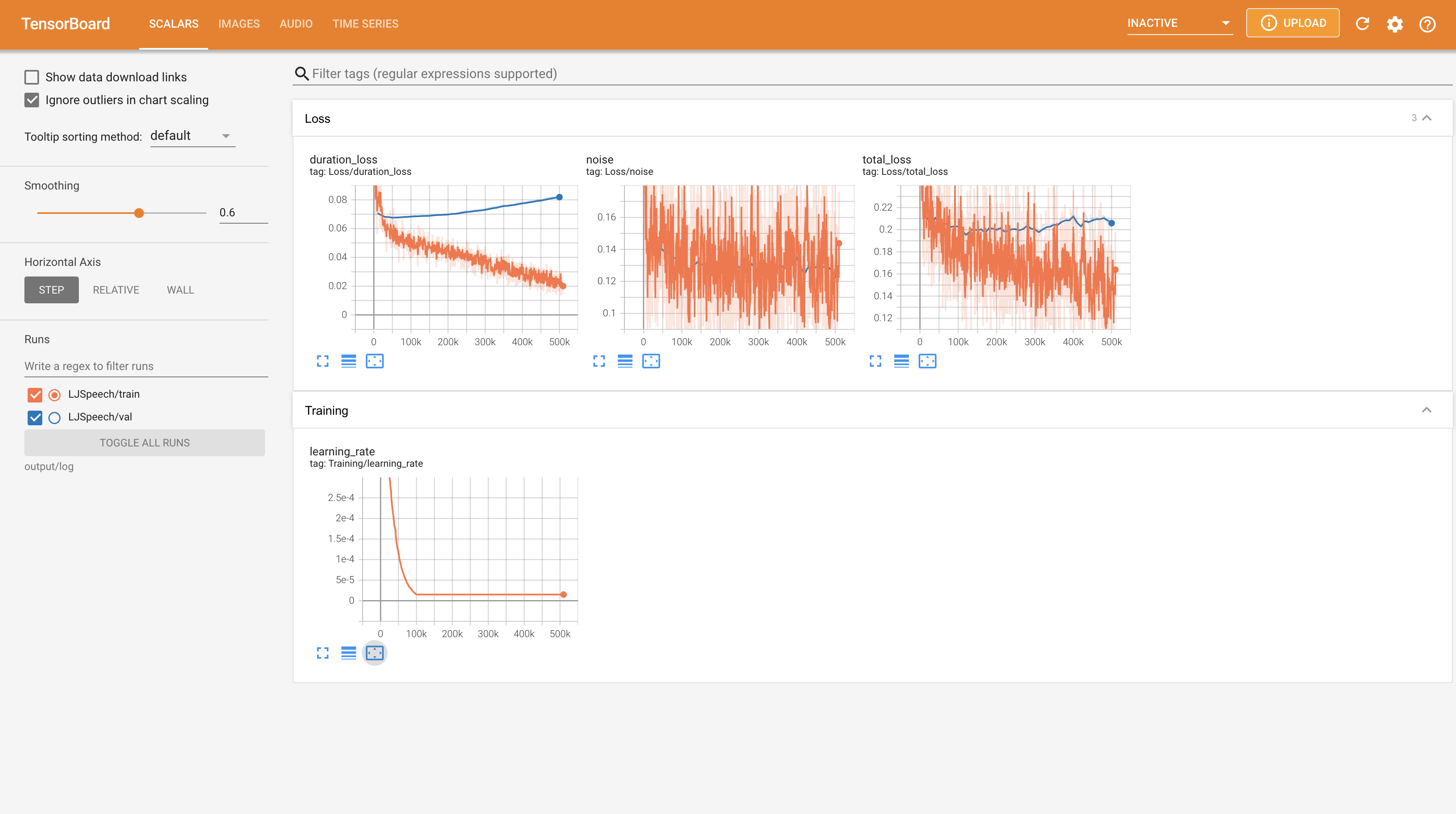
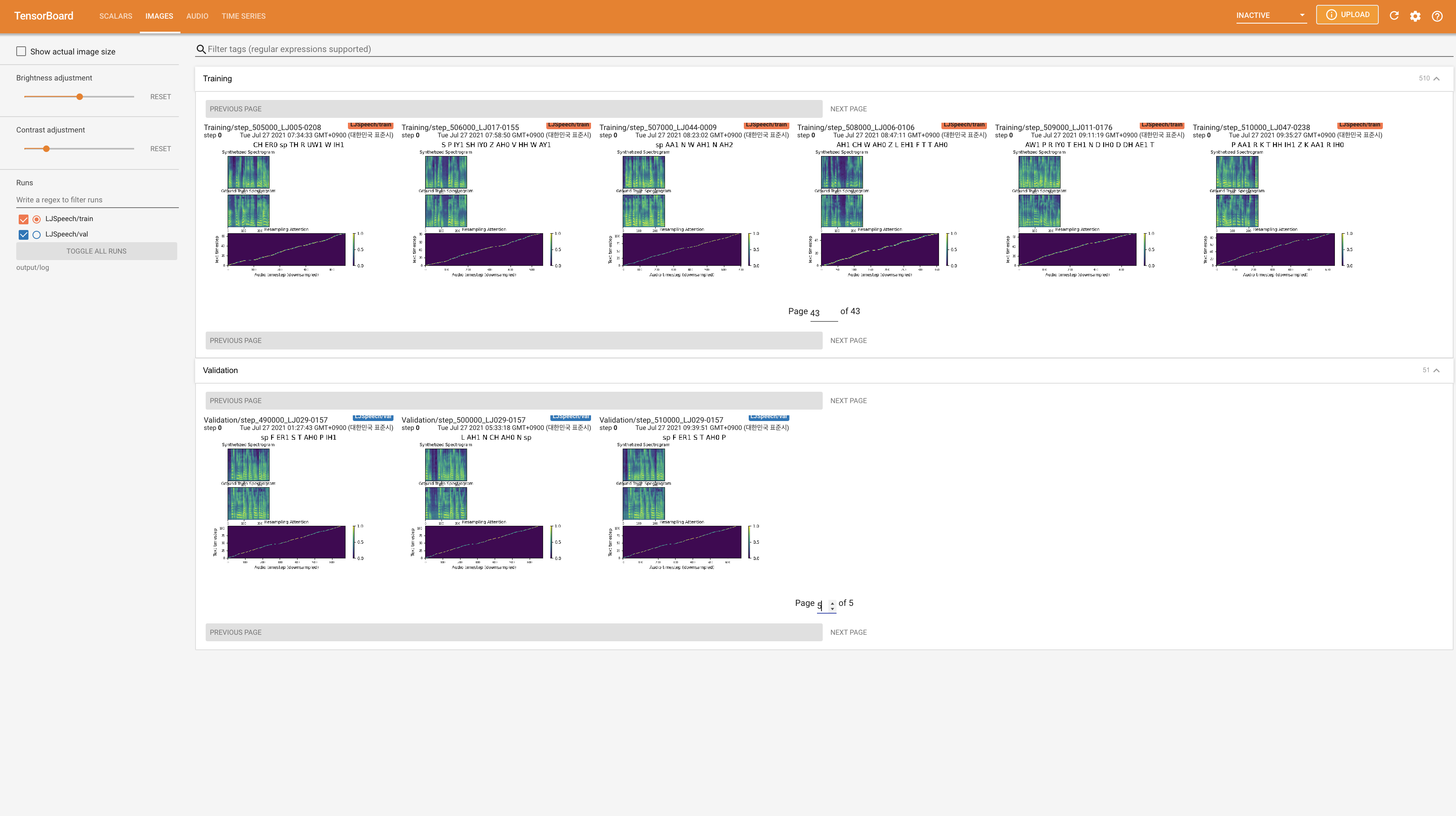
22050Hz bukannya 24KHz dan ikuti konfigurasi LJSPEECH umum.nn.LSTM sebagai gantinya. @misc{lee2021wavegrad2,
author = {Lee, Keon},
title = {WaveGrad2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/WaveGrad2}}
}


