WaveGrad2
v1.0.0
Implementação de Pytorch do WaveGrad 2 do Google Brain: Refinamento iterativo para síntese de texto em fala.
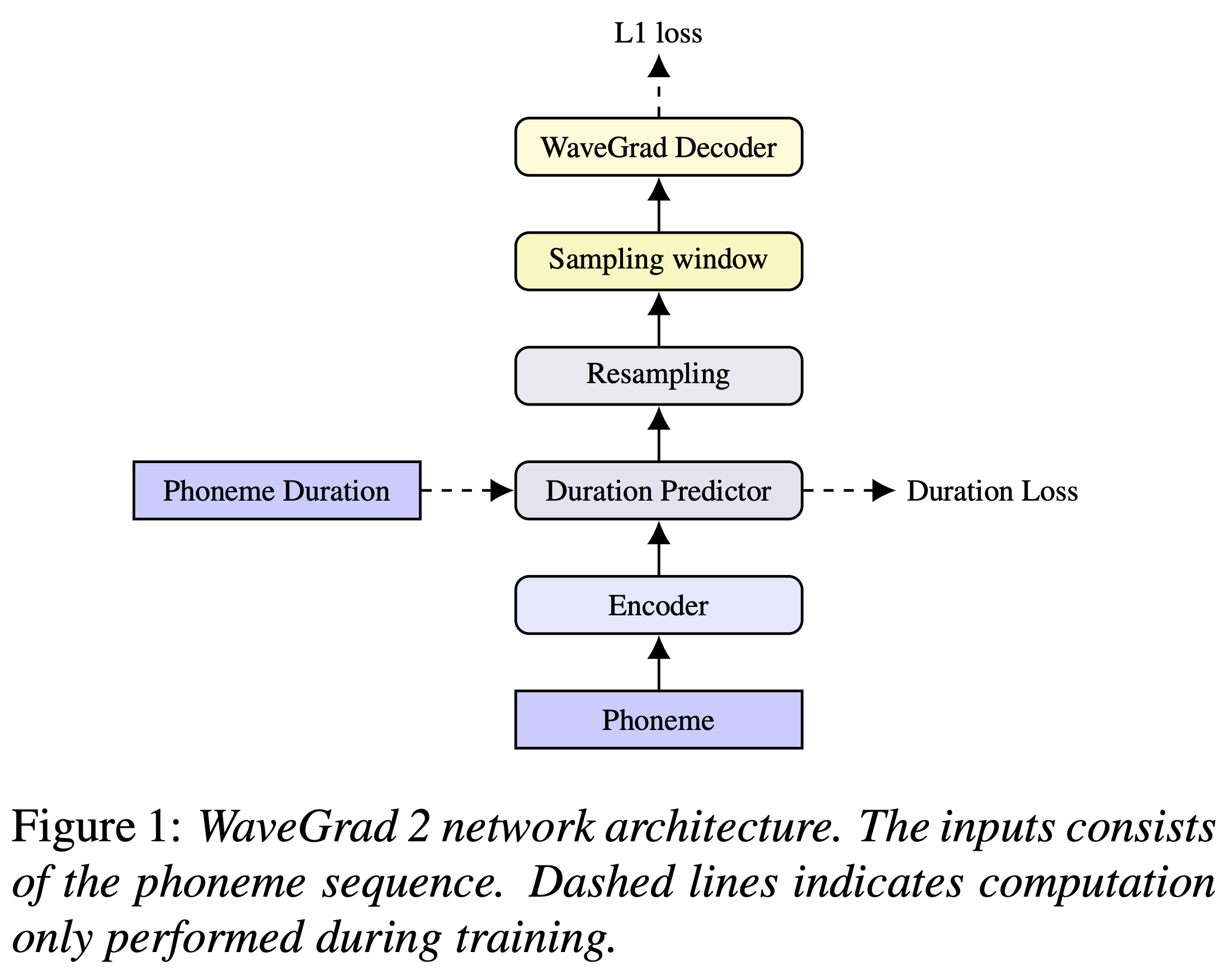
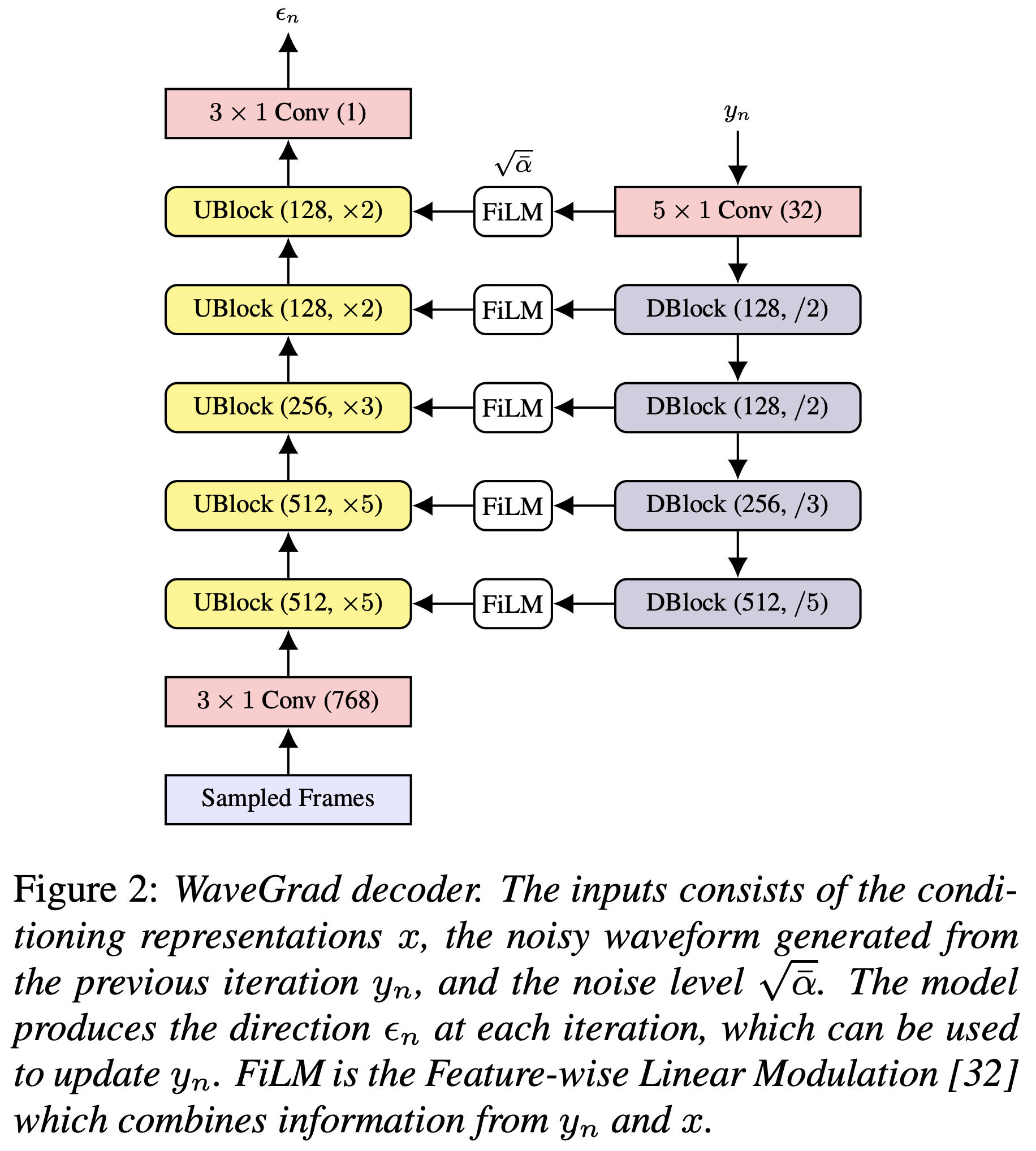
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Você precisa baixar os modelos pré -tenhados e colocá -los em output/ckpt/LJSpeech/ .
Para TTS de alto-falante inglês, execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Os enunciados gerados serão colocados em output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step RESTORE_STEP --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Para sintetizar todos os enunciados em preprocessed_data/LJSpeech/val.txt
A taxa de fala dos enunciados sintetizados pode ser controlada especificando as taxas de duração desejadas. Por exemplo, pode -se aumentar a taxa de fala em 20 % em
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8
Os conjuntos de dados suportados são
Primeiro, corra
python3 prepare_align.py config/LJSpeech/preprocess.yaml
para alguns preparativos.
Conforme descrito no artigo, o alinhador forçado de Montreal (MFA) é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas. Os alinhamentos para os conjuntos de dados LJSpeech são fornecidos aqui (graças ao FastSpeech2 do Ming024). Você precisa descompactar os arquivos em preprocessed_data/LJSpeech/TextGrid/ .
Depois disso, execute o script de pré -processamento por
python3 preprocess.py config/LJSpeech/preprocess.yaml
Como alternativa, você pode alinhar o corpus sozinho. Baixe o pacote oficial da MFA e execute
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
ou
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
para alinhar o corpus e depois executar o script de pré -processamento.
python3 preprocess.py config/LJSpeech/preprocess.yaml
Treine seu modelo com
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
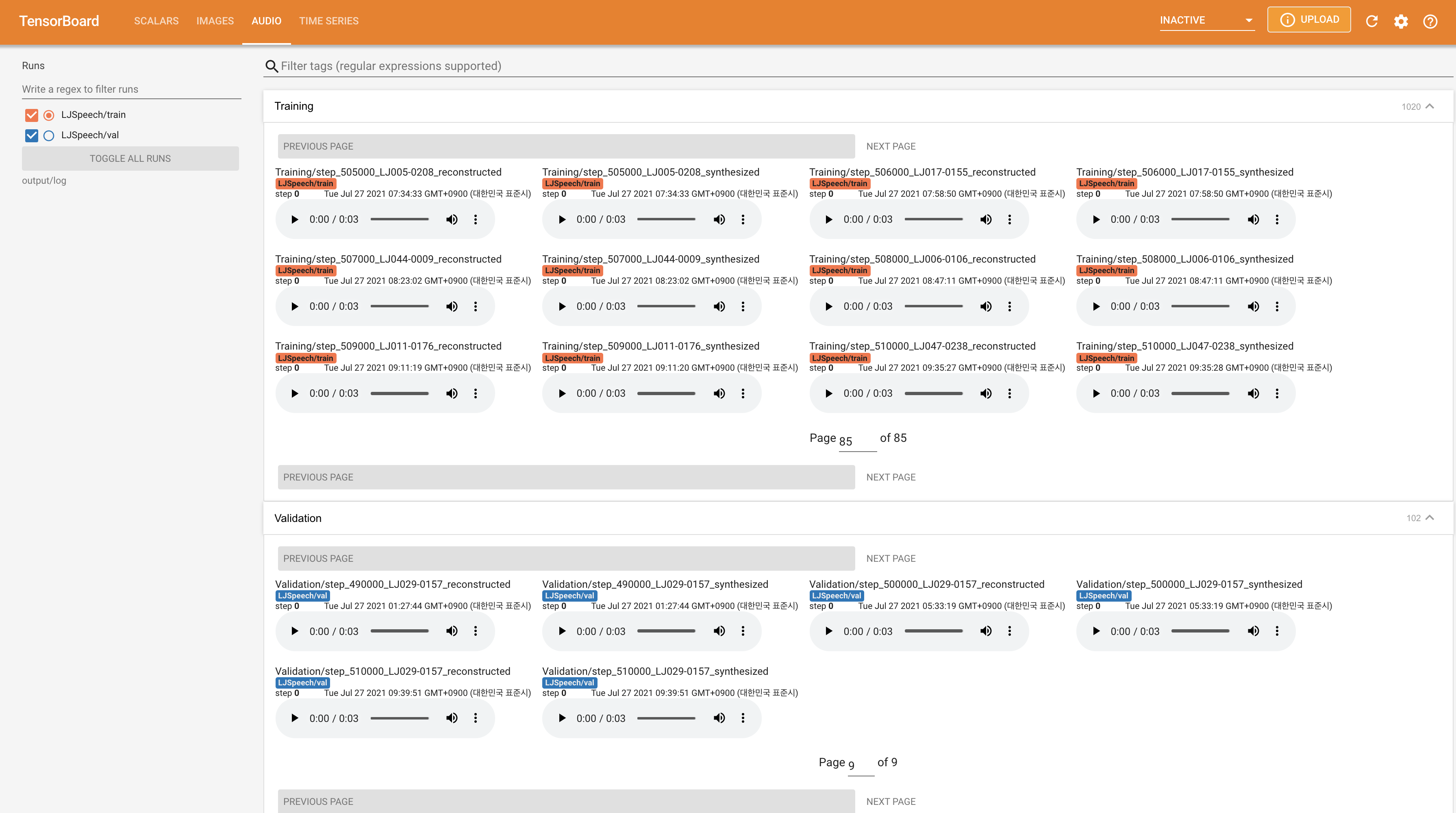
Usar
tensorboard --logdir output/log/LJSpeech
Para servir o Tensorboard em sua localhost. As curvas de perda, os espectrogramas MEL sintetizados e os áudios são mostrados.
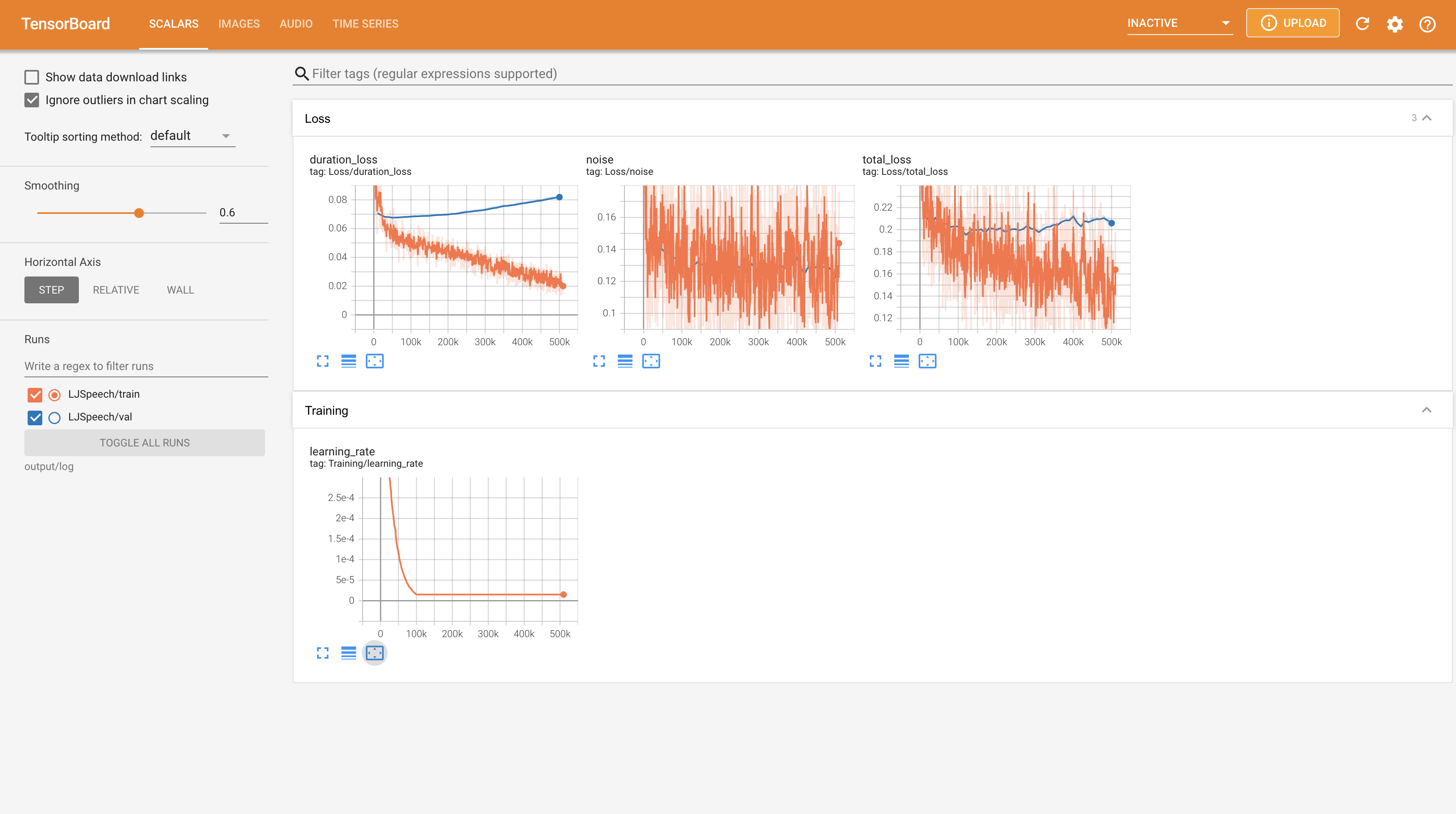
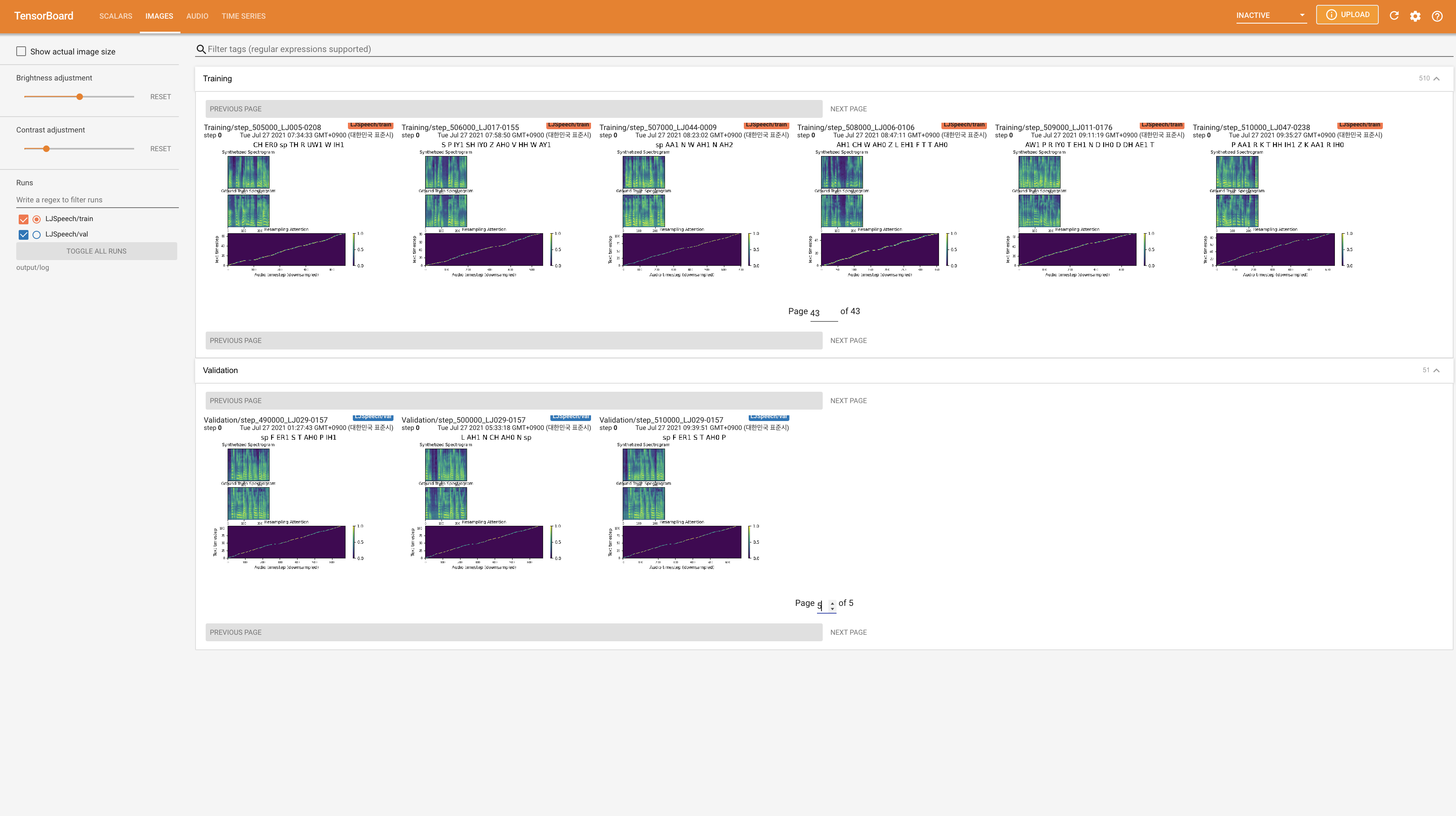
22050Hz em vez de 24KHz e siga as configurações gerais de LJSpeech.nn.LSTM em vez disso. @misc{lee2021wavegrad2,
author = {Lee, Keon},
title = {WaveGrad2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/WaveGrad2}}
}


