WaveGrad2
v1.0.0
Pytorch-Implementierung von Google Brain's Wavegrad 2: Iterative Verfeinerung für die Synthese von Text-to-Speech-Synthese.
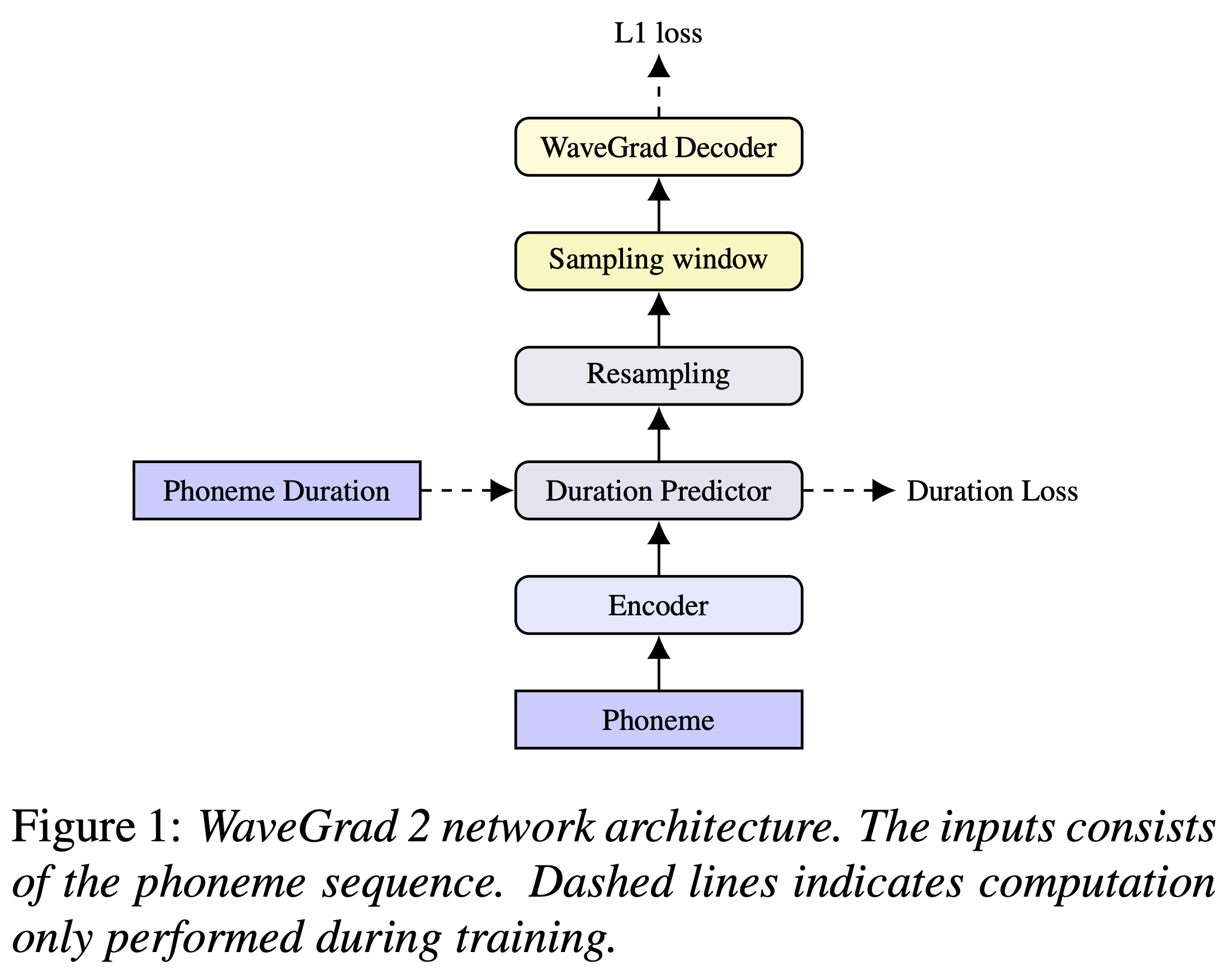
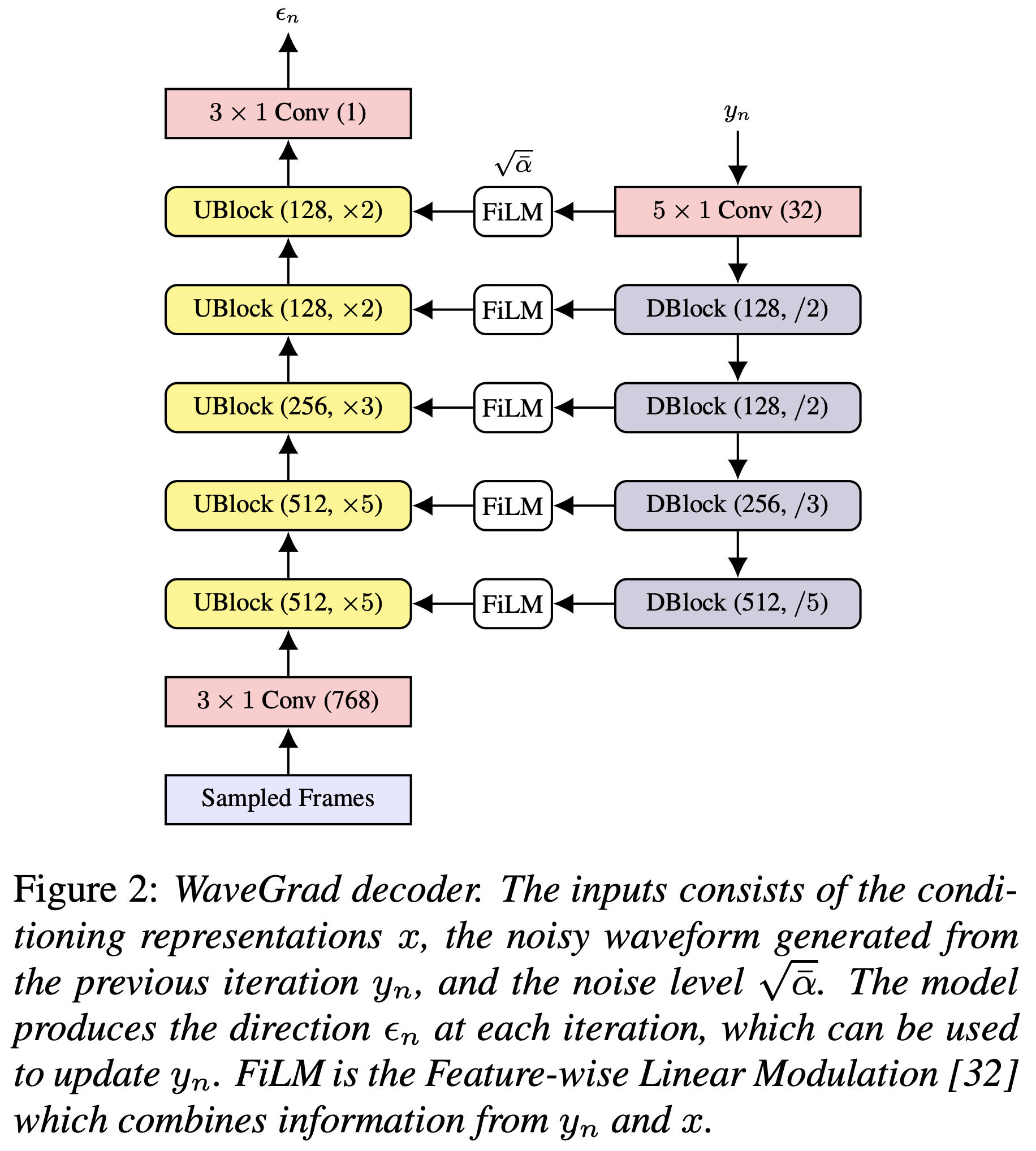
Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Sie müssen die vorbereiteten Modelle herunterladen und in output/ckpt/LJSpeech/ einsetzen.
Für englische TTS mit Single-Lautsprechern laufen Sie
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Die erzeugten Äußerungen werden in output/result/ .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step RESTORE_STEP --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
So synthetisieren Sie alle Äußerungen in preprocessed_data/LJSpeech/val.txt
Die Sprechrate der synthetisierten Äußerungen kann durch Angabe der gewünschten Dauerverhältnisse gesteuert werden. Zum Beispiel kann man die Sprechrate um 20 % erhöhen
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8
Die unterstützten Datensätze sind
Zunächst rennen
python3 prepare_align.py config/LJSpeech/preprocess.yaml
Für einige Vorbereitungen.
Wie in der Arbeit beschrieben, wird Montreal erzwungen Aligner (MFA) verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen zu erhalten. Ausrichtungen für die LJSpeech -Datensätze werden hier bereitgestellt (dank der Fastspeech2 von Ming024). Sie müssen die Dateien in preprocessed_data/LJSpeech/TextGrid/ entpacken.
Führen Sie danach das Vorverarbeitungskript durch
python3 preprocess.py config/LJSpeech/preprocess.yaml
Alternativ können Sie den Korpus selbst ausrichten. Laden Sie das offizielle MFA -Paket herunter und führen Sie aus
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
oder
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
Um den Korpus auszurichten und dann das Vorverarbeitungsskript auszuführen.
python3 preprocess.py config/LJSpeech/preprocess.yaml
Trainieren Sie Ihr Modell mit
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Verwenden
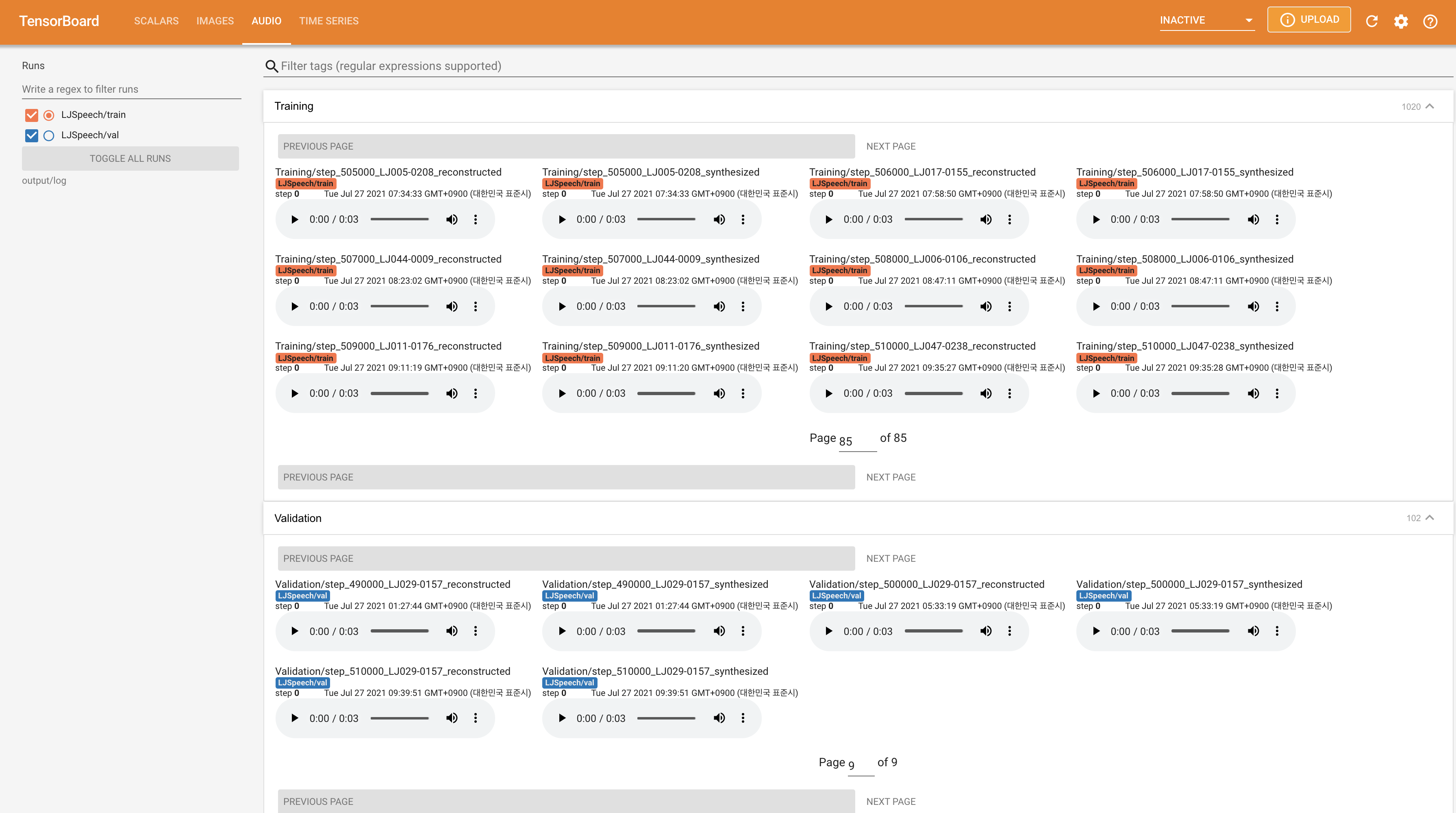
tensorboard --logdir output/log/LJSpeech
Tensorboard auf Ihrem örtlichen Haus servieren. Die Verlustkurven, synthetisierte Melspektrogramme und Audios werden gezeigt.
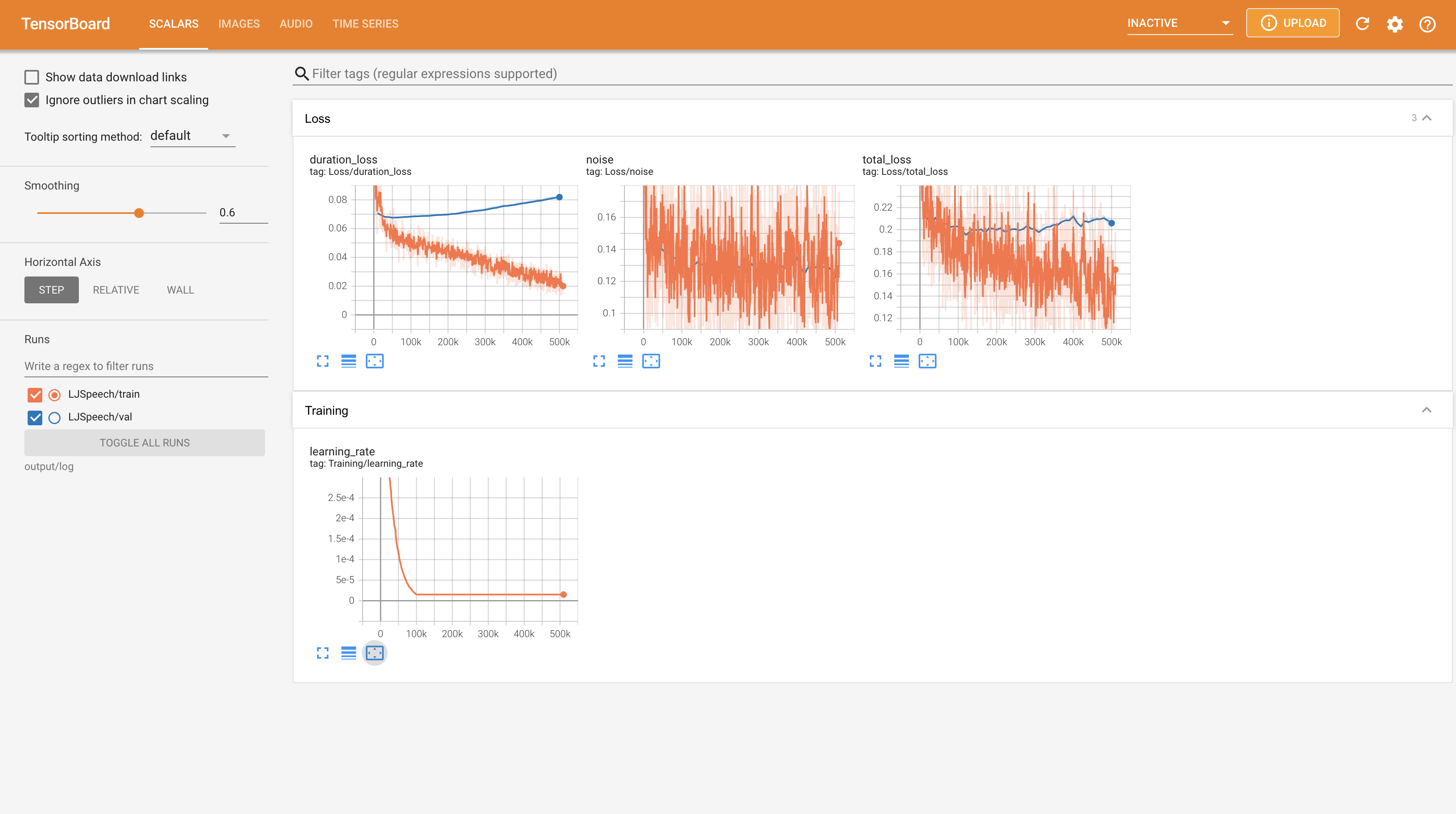
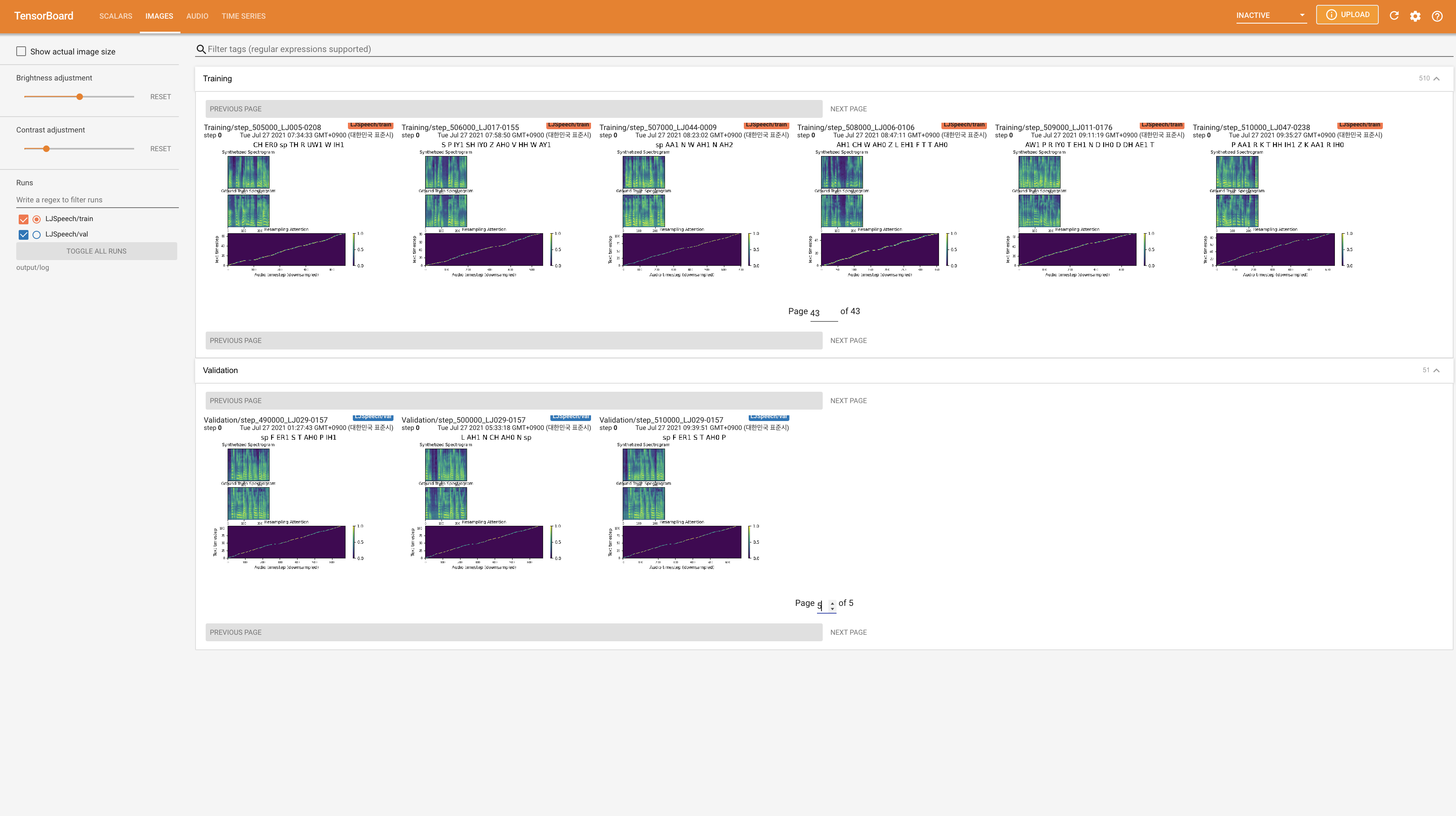
22050Hz anstelle von 24KHz und folgen Sie allgemeine LJSpeech -Konfigurationen.nn.LSTM . @misc{lee2021wavegrad2,
author = {Lee, Keon},
title = {WaveGrad2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/WaveGrad2}}
}


