torch points3d
v 1.3.0
นี่คือกรอบการทำงานสำหรับการใช้แบบจำลองการเรียนรู้เชิงลึกทั่วไปสำหรับงานการวิเคราะห์คลาวด์แบบจุดกับเกณฑ์มาตรฐานคลาสสิก มันอาศัย Pytorch Geometric และ Facebook Hydra เป็นอย่างมาก
เฟรมเวิร์กช่วยให้โมเดลแบบลีนและซับซ้อนสามารถสร้างได้ด้วยความพยายามขั้นต่ำและการทำซ้ำที่ยอดเยี่ยม นอกจากนี้ยังให้ API ระดับสูงเพื่อให้เป็นประชาธิปไตยในการเรียนรู้อย่างลึกซึ้งเกี่ยวกับ PointClouds ดูกระดาษของเราที่ 3DV สำหรับภาพรวมของความสามารถในการทำงานและมาตรฐานของเครือข่ายที่ล้ำสมัย
สำหรับการตั้งค่าที่ราบรื่นยิ่งขึ้นขอแนะนำให้ใช้ Docker วิธีการนี้ช่วยให้มั่นใจได้ถึงความเข้ากันได้และลดกระบวนการติดตั้งโดยเฉพาะอย่างยิ่งเมื่อทำงานกับ CUDA และ Pytorch รุ่นเฉพาะ คุณสามารถดึงอิมเมจนักเทียบท่าที่เหมาะสมดังนี้:
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-develหลังจากตั้งค่าสภาพแวดล้อม (ไม่ว่าจะเป็นไปได้หรือผ่าน Docker) ให้ติดตั้งแพ็คเกจ Python ที่ต้องการโดยใช้ PIP:
pip install torch-points3d├─ benchmark # Output from various benchmark runs
├─ conf # All configurations for training nad evaluation leave there
├─ notebooks # A collection of notebooks that allow result exploration and network debugging
├─ docker # Docker image that can be used for inference or training
├─ docs # All the doc
├─ eval.py # Eval script
├─ find_neighbour_dist.py # Script to find optimal #neighbours within neighbour search operations
├─ forward_scripts # Script that runs a forward pass on possibly non annotated data
├─ outputs # All outputs from your runs sorted by date
├─ scripts # Some scripts to help manage the project
├─ torch_points3d
├─ core # Core components
├─ datasets # All code related to datasets
├─ metrics # All metrics and trackers
├─ models # All models
├─ modules # Basic modules that can be used in a modular way
├─ utils # Various utils
└─ visualization # Visualization
├─ test
└─ train.py # Main script to launch a trainingในฐานะที่เป็นปรัชญาทั่วไปเราได้แบ่งชุดข้อมูลและโมเดลตามงาน ตัวอย่างเช่นชุดข้อมูลมีห้าโฟลเดอร์ย่อย:
ที่แต่ละโฟลเดอร์มีชุดข้อมูลที่เกี่ยวข้องกับแต่ละงาน
โปรดดูเอกสารของเราสำหรับการเข้าถึงบางรุ่นโดยตรงจาก API และดูสมุดบันทึกตัวอย่างของเราสำหรับ KPCONV และ RSCONV สำหรับรายละเอียดเพิ่มเติม
งาน | ตัวอย่าง |
|---|---|
การจำแนกประเภท / การแบ่งส่วน |  |
การแบ่งส่วน |  |
การตรวจจับวัตถุ | 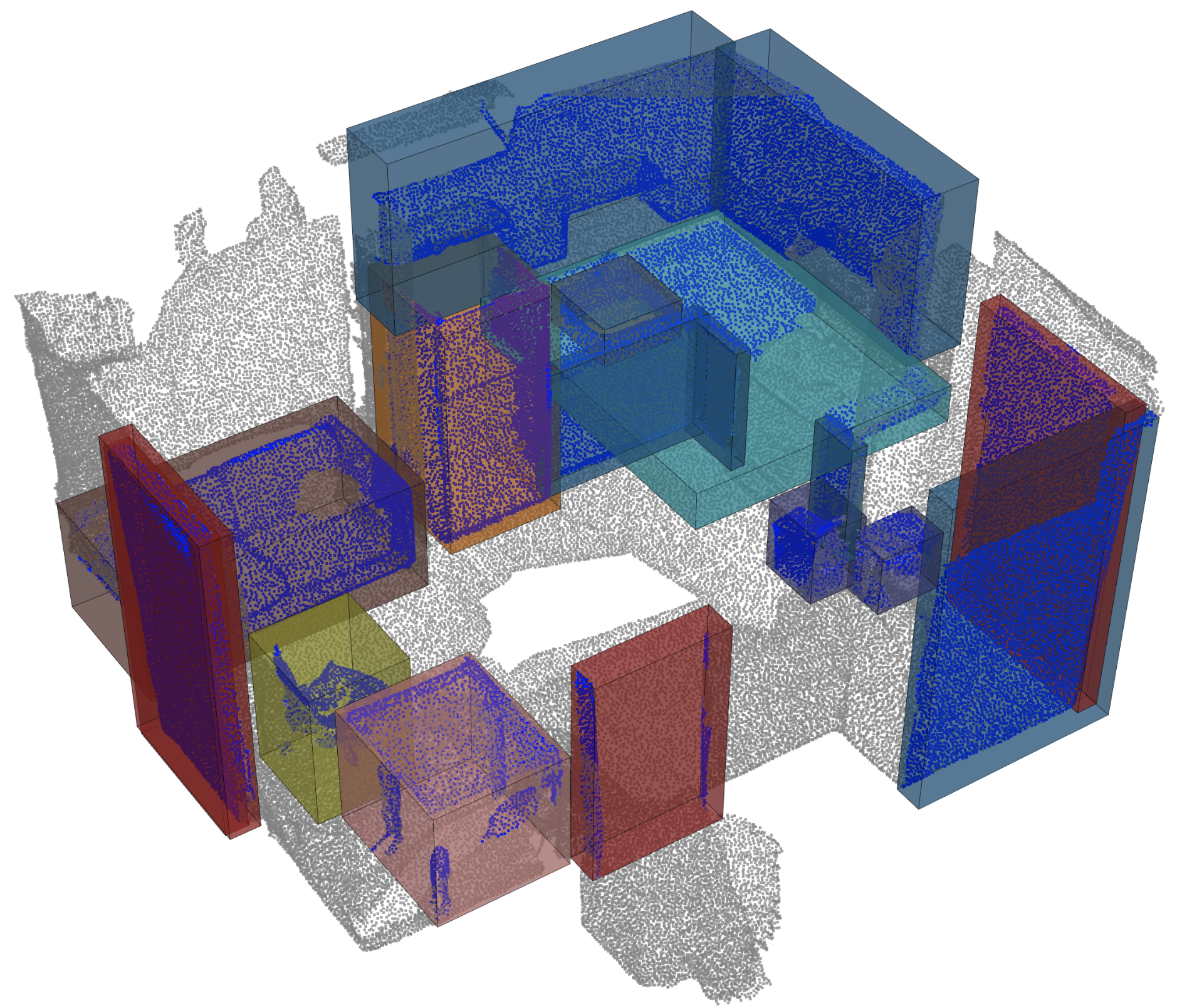 |
การแบ่งส่วน panoptic |  |
การลงทะเบียน |  |
Scannet จาก Angela Dai และคณะ : Scannet: การสร้างฉาก 3 มิติที่มีคำอธิบายประกอบ 3 มิติ
S3DIS จาก Iro Armeni และคณะ : ข้อมูลร่วมกัน 2D-3D-Semantic สำหรับการทำความเข้าใจฉากในร่ม
* S3DIS 1x1
* S3DIS Room
* S3DIS Fused - Sphere | Cylinder
* S3DIS Fused - Sphere | Cylinder
3dmatch จาก Andy Zeng และคณะ : 3DMATCH: การเรียนรู้คำอธิบายทางเรขาคณิตในท้องถิ่นจากการสร้าง RGB-D
มาตรฐาน Iralab จาก Simone Fontana และคณะ : เกณฑ์มาตรฐานสำหรับอัลกอริทึมการลงทะเบียน Point Clouds ซึ่งประกอบด้วยข้อมูลจาก:
Kitti odometry พร้อมท่าทางที่ได้รับการแก้ไข (ขอบคุณ @HumanPose1) จาก A. Geiger et al : เราพร้อมสำหรับการขับขี่แบบอิสระหรือไม่? ชุดเกณฑ์มาตรฐาน Kitti Vision
ขณะนี้เราสนับสนุนเครื่องยนต์ Minkowski> v0.5 และ Torchsparse> = v1.4.0 เป็นแบ็กเอนด์สำหรับการโน้มน้าวใจกระจัดกระจาย แพ็คเกจเหล่านั้นจะต้องติดตั้งอย่างอิสระจาก Torch Points3d โปรดทำตามคำแนะนำการติดตั้งและบันทึกการแก้ไขปัญหาในที่เก็บที่เกี่ยวข้อง ในขณะนี้ MinkowskiEngine ดูที่นี่ (ขอบคุณ Chris Choy) แสดงให้เห็นถึงการฝึกอบรมที่เร็วขึ้น โปรดทราบว่า torchsparse ยังอยู่ในช่วงเบต้าและไม่สนับสนุนการฝึกอบรม CPU เท่านั้น
เมื่อคุณมีการตั้งค่าหนึ่งในสองเฟรมเวิร์กสัดส่วนแบบเบาบางที่คุณสามารถเริ่มใช้ได้คือระดับสูงเพื่อกำหนดกระดูกสันหลังของ UNET หรือเพียงแค่ตัวเข้ารหัส:
from torch_points3d . applications . sparseconv3d import SparseConv3d
model = SparseConv3d ( "unet" , input_nc = 3 , output_nc = 5 , num_layers = 4 , backend = "torchsparse" ) # minkowski by default นอกจากนี้คุณยังสามารถรวบรวมเครือข่ายของคุณเองโดยใช้โมดูลที่ให้ไว้ใน torch_points3d/modules/SparseConv3d/nn ตัวอย่างเช่นหากคุณต้องการใช้แบ็กเอนด์ torchsparse คุณสามารถทำสิ่งต่อไปนี้:
import torch_points3d . modules . SparseConv3d as sp3d
sp3d . nn . set_backend ( "torchsparse" )
conv = sp3d . nn . Conv3d ( 10 , 10 )
bn = sp3d . nn . BatchNorm ( 10 ) ความแม่นยำแบบผสมช่วยให้หน่วยความจำลดลงใน GPU และเวลาการฝึกอบรมที่เร็วขึ้นเล็กน้อยโดยการดำเนินการแบบเบาบางการรวมและการไล่ระดับสี OPs ใน float16 ปัจจุบันการฝึกอบรมแบบผสมผสานได้รับการสนับสนุนสำหรับการฝึกอบรม CUDA บนเครือข่าย SparseConv3d ด้วยแบ็กเอนด์ Torchsparse ในการเปิดใช้งานความแม่นยำแบบผสมตรวจสอบให้แน่ใจว่าคุณมี Torchsparse เวอร์ชันล่าสุดพร้อม pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git จากนั้นตั้งค่า training.enable_mixed=True ในไฟล์การกำหนดค่าการฝึกอบรมของคุณ หากเป็นไปตามเงื่อนไขทั้งหมดเมื่อคุณเริ่มการฝึกอบรมคุณจะเห็นรายการบันทึกที่ระบุ:
[torch_points3d.models.base_model][INFO] - Model will use mixed precision
อย่างไรก็ตามหากคุณพยายามใช้การฝึกอบรมแบบผสมผสานกับแบ็กเอนด์ที่ไม่ได้รับการสนับสนุนคุณจะเห็น:
[torch_points3d.models.base_model][WARNING] - Mixed precision is not supported on this model, using default precision...
PretrainedRegistry ช่วยให้ทุกคนสามารถเพิ่มโมเดลที่ผ่านการฝึกอบรมมาก่อนและ re-create ด้วยรหัสเพียง 2 บรรทัดสำหรับ finetunning หรือวัตถุประสงค์ production
[You] เปิดตัวการฝึกอบรมแบบจำลองของคุณด้วยการเปิดใช้งาน WANDB ( wandb.log=True )[TorchPoints3d] เมื่อการฝึกอบรมเสร็จสิ้น TorchPoints3d จะอัปโหลดรูปแบบที่ผ่านการฝึกอบรมของคุณภายในจุดตรวจสอบที่กำหนดเองของเราไปยัง Wandb ของคุณ[You] ภายในคลาส PretainedRegistry เพิ่ม key-value pair ภายในโมเดล MODELS key ควรอธิบายโมเดลชุดข้อมูลและการฝึกอบรมพารามิเตอร์ไฮเปอร์พารามิเตอร์ (อาจเป็นโมเดลที่ดีที่สุด) value ควรเป็น url ที่อ้างอิงไฟล์ .pt บน Wandb ของคุณ ตัวอย่าง: คีย์: pointnet2_largemsg-s3dis-1 pointnet2_largemsg.pt ค่า URL: https://api.wandb.ai/files/loicland/benchmark-torch-points-3d-s3dis/1e1p0csk/pointnet2_largemsg.pt คีย์ desribes a pointnet2 largemsg trained on s3dis fold 1
[Anyone] โดยใช้คลาส PretainedRegistry และโดยการจัดหา key น้ำหนักโมเดลที่เกี่ยวข้องจะถูก downloaded และรุ่นที่ผ่านการฝึกอบรมมาก่อนจะ ready to use กับการแปลง [ In ]:
from torch_points3d . applications . pretrained_api import PretainedRegistry
model = PretainedRegistry . from_pretrained ( "pointnet2_largemsg-s3dis-1" )
print ( model . wandb )
print ( model . print_transforms ())
[ Out ]:
== == == == == == == == == == == == == == == == == == == == == == == == == = WANDB URLS == == == == == == == == == == == == == == == == == == == == == == == == == == ==
WEIGHT_URL : https : // api . wandb . ai / files / loicland / benchmark - torch - points - 3 d - s3dis / 1e1 p0csk / pointnet2_largemsg . pt
LOG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / logs
CHART_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk
OVERVIEW_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / overview
HYDRA_CONFIG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / hydra - config . yaml
OVERRIDES_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / overrides . yaml
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
pre_transform = None
test_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
train_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
RandomNoise ( sigma = 0.001 , clip = 0.05 ),
RandomRotate (( - 180 , 180 ), axis = 2 ),
RandomScaleAnisotropic ([ 0.8 , 1.2 ]),
RandomAxesSymmetry ( x = True , y = False , z = False ),
DropFeature ( proba = 0.2 , feature = 'rgb' ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
val_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
inference_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
pre_collate_transform = Compose ([
PointCloudFusion (),
SaveOriginalPosId ,
GridSampling3D ( grid_size = 0.04 , quantize_coords = False , mode = mean ),
])เราใช้บทกวีในการจัดการแพ็คเกจของเรา เพื่อเริ่มต้นใช้งานโคลนที่เก็บนี้และเรียกใช้คำสั่งต่อไปนี้จากรูทของ repo
poetry install --no-root
สิ่งนี้จะติดตั้งการพึ่งพาที่จำเป็นทั้งหมดในสภาพแวดล้อมเสมือนจริงใหม่
เปิดใช้งานสภาพแวดล้อม
poetry shellคุณสามารถตรวจสอบว่าการติดตั้งสำเร็จโดยการทำงาน
python -m unittest -v สำหรับการสนับสนุน pycuda (จำเป็นสำหรับงานลงทะเบียนเท่านั้น):
pip install pycudapoetry run python train.py task=segmentation models=segmentation/pointnet2 model_name=pointnet2_charlesssg data=segmentation/shapenet-fixedและคุณควรเห็นอะไรแบบนั้น
การกำหนดค่าสำหรับ PointNet ++ เป็นตัวอย่างที่ดีของวิธีการกำหนดโมเดลและมีดังนี้:
# PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (https://arxiv.org/abs/1706.02413)
# Credit Charles R. Qi: https://github.com/charlesq34/pointnet2/blob/master/models/pointnet2_part_seg_msg_one_hot.py
pointnet2_onehot :
architecture : pointnet2.PointNet2_D
conv_type : " DENSE "
use_category : True
down_conv :
module_name : PointNetMSGDown
npoint : [1024, 256, 64, 16]
radii : [[0.05, 0.1], [0.1, 0.2], [0.2, 0.4], [0.4, 0.8]]
nsamples : [[16, 32], [16, 32], [16, 32], [16, 32]]
down_conv_nn :
[
[[FEAT, 16, 16, 32], [FEAT, 32, 32, 64]],
[[32 + 64, 64, 64, 128], [32 + 64, 64, 96, 128]],
[[128 + 128, 128, 196, 256], [128 + 128, 128, 196, 256]],
[[256 + 256, 256, 256, 512], [256 + 256, 256, 384, 512]],
]
up_conv :
module_name : DenseFPModule
up_conv_nn :
[
[512 + 512 + 256 + 256, 512, 512],
[512 + 128 + 128, 512, 512],
[512 + 64 + 32, 256, 256],
[256 + FEAT, 128, 128],
]
skip : True
mlp_cls :
nn : [128, 128]
dropout : 0.5 เราจัดเตรียมสคริปต์สำหรับการเรียกใช้รูปแบบที่ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับข้อมูลที่กำหนดเองซึ่งอาจไม่ได้รับการอธิบายประกอบ คุณจะพบตัวอย่างนี้สำหรับงานการแบ่งส่วนส่วนบน Shapenet เช่นเดียวกับส่วนที่เหลือของ codebase การปรับแต่งส่วนใหญ่เกิดขึ้นผ่านไฟล์ config และตัวอย่างที่ให้ไว้สามารถขยายไปยังชุดข้อมูลอื่น ๆ คุณสามารถสร้างของคุณเองได้อย่างง่ายดาย กลับไปที่งานการแบ่งส่วนชิ้นส่วนบอกว่าคุณมีโฟลเดอร์ที่เต็มไปด้วยเมฆจุดที่คุณรู้ว่าเป็นเครื่องบินและคุณมีจุดตรวจของรุ่นที่ผ่านการฝึกอบรมเกี่ยวกับเครื่องบินและคลาสอื่น ๆ เพียงแค่แก้ไข config.yaml และ shapenet.yaml
python forward_scripts/forward.py ผลลัพธ์ของการวิ่งไปข้างหน้าจะถูกวางไว้ใน output_folder ที่ระบุและคุณสามารถใช้โน้ตบุ๊กที่ให้ไว้เพื่อสำรวจผลลัพธ์ ด้านล่างเป็นตัวอย่างของผลลัพธ์ของการใช้แบบจำลองที่ได้รับการฝึกฝนบนฝาครอบเท่านั้นเพื่อค้นหาชิ้นส่วนของเครื่องบินและหมวก
ในที่สุดสำหรับผู้ที่สนใจในการปรับใช้แบบจำลองของพวกเขากับสภาพแวดล้อมการผลิตเราให้บริการ DockerFile รวมถึงสคริปต์การสร้าง สมมติว่าคุณได้ฝึกอบรมเครือข่ายสำหรับการแบ่งส่วนความหมายที่ให้น้ำหนัก <outputfolder/weights.pt> คำสั่งต่อไปนี้จะสร้างภาพนักเทียบท่าให้คุณ:
cd docker
./build.sh outputfolder/weights.pt จากนั้นคุณสามารถใช้เพื่อเรียกใช้ผ่านไปข้างหน้าบนคลาวด์จุดทั้งหมดใน input_path และสร้างผลลัพธ์ใน output_path
docker run -v /test_data:/in -v /test_data/out:/out pointnet2_charlesssg:latest python3 forward_scripts/forward.py dataset=shapenet data.forward_category=Cap input_path= " /in " output_path= " /out " ตัวเลือก -v จะติดตั้งไดเรกทอรีท้องถิ่นไปยังระบบไฟล์ของคอนเทนเนอร์ ตัวอย่างเช่นในบรรทัดคำสั่งด้านบน /test_data/out จะถูกติดตั้งที่ตำแหน่ง /out ด้วยเหตุนี้ไฟล์ทั้งหมดที่เขียนเข้า /out จะมีอยู่ในโฟลเดอร์ /test_data/out บนเครื่องของคุณ
เราแนะนำให้ใช้ snakeviz และ cProfile
ใช้ cprofile เพื่อโปรไฟล์รหัสของคุณ
poetry run python -m cProfile -o {your_name}.prof train.py ... debugging.profiling=True
และแสดงภาพผลลัพธ์โดยใช้ Snakeviz
snakeviz {your_name}.prof
นอกจากนี้ยังเป็นไปได้ที่จะใช้ torch.utils.bottleneck
python -m torch.utils.bottleneck /path/to/source/script.py [args]
ตรวจสอบให้แน่ใจว่าอย่างน้อย pytorch 1.8.0 ได้รับการติดตั้งและตรวจสอบว่า cuda/bin และ cuda/include อยู่ใน $PATH ของคุณและ $CPATH ตามลำดับเช่น:
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
$ echo $PATH
>>> /usr/local/cuda/bin:...
$ echo $CPATH
>>> /usr/local/cuda/include:...
เมื่อเราอัปเดตเวอร์ชันของ pytorch ที่ใช้แพ็คเกจที่รวบรวมจะต้องติดตั้งใหม่มิฉะนั้นคุณจะพบข้อผิดพลาดที่มีลักษณะเช่นนี้:
... scatter_cpu.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN3c1012CUDATensorIdEv
สิ่งนี้สามารถเกิดขึ้นได้สำหรับห้องสมุดต่อไปนี้:
วิธีที่ง่ายในการแก้ไขปัญหานี้คือการเรียกใช้คำสั่งต่อไปนี้ด้วยการเปิดใช้งาน Env เสมือน:
pip uninstall torch-scatter torch-sparse torch-cluster torch-points-kernels -y
rm -rf ~/.cache/pip
poetry install
สิ่งนี้สามารถเกิดขึ้นได้เมื่อพยายามเรียกใช้รหัสใน GPU ที่แตกต่างจากที่ใช้ในการรวบรวมไลบรารี torch-points-kernels ถอนการติดตั้ง torch-points-kernels , แคชล้างและติดตั้งใหม่หลังจากตั้งค่าตัวแปรสภาพแวดล้อม TORCH_CUDA_ARCH_LIST ตัวอย่างเช่นสำหรับการรวบรวมด้วย Tesla T4 (Turing 7.5) และเรียกใช้รหัสในการใช้งาน Tesla V100 (Volta 7.0):
export TORCH_CUDA_ARCH_LIST="7.0;7.5"
ดูแผนภูมิที่มีประโยชน์นี้สำหรับความเข้ากันได้ของสถาปัตยกรรมมากขึ้น
RIASES OSError: [WinError 6] The handle is invalid / wandb: ERROR W&B process failed to launch ตัว WANDB ในขณะนี้บน Windows (ดูปัญหานี้) วิธีแก้ปัญหาคือการใช้อาร์กิวเมนต์บรรทัดคำสั่ง wandb.log=false
เราให้บริการ Pyvista และพาเนลที่ใช้โน้ตบุ๊กที่ช่วยให้คุณสำรวจการทดลองที่ผ่านมาของคุณด้วยสายตา เมื่อใช้ Jupyter Lab คุณจะต้องติดตั้งส่วนขยาย:
jupyter labextension install @pyviz/jupyterlab_pyviz
รันผ่านโน้ตบุ๊กและคุณควรเห็นแผงควบคุมเริ่มต้นที่มีลักษณะดังต่อไปนี้:
ยินดีต้อนรับ! สิ่งเดียวที่ถามคือคุณยึดติดกับสไตล์และเพิ่มการทดสอบในขณะที่คุณเพิ่มคุณสมบัติเพิ่มเติม!
สำหรับการจัดแต่งทรงผมคุณสามารถใช้ตะขอล่วงหน้าเพื่อช่วยคุณ:
pre-commit install
ลำดับของการตรวจสอบจะเรียกใช้สำหรับคุณและคุณอาจต้องเพิ่มไฟล์คงที่อีกครั้งในไฟล์ที่ถูกเก็บไว้
เมื่อพูดถึง DocStrings เราใช้ DocStrings สไตล์ NumPy สำหรับผู้ที่ใช้รหัส Visual Studio มีส่วนขยายที่ยอดเยี่ยมที่สามารถช่วยได้ ติดตั้งและตั้งค่ารูปแบบเป็น numpy และคุณควรจะไปได้ดี!
สุดท้ายหากคุณต้องการแชทโดยตรงกับเราอย่าลังเลที่จะเข้าร่วม Slack ของเราเพียงแค่ยิงอีเมลถึงเราแล้วเราจะเพิ่มคุณ
หากคุณพบว่างานของเรามีประโยชน์อย่าลังเลที่จะอ้างถึง:
@inproceedings{
tp3d,
title={Torch-Points3D: A Modular Multi-Task Frameworkfor Reproducible Deep Learning on 3D Point Clouds},
author={Chaton, Thomas and Chaulet Nicolas and Horache, Sofiane and Landrieu, Loic},
booktitle={2020 International Conference on 3D Vision (3DV)},
year={2020},
organization={IEEE},
url = {url{https://github.com/nicolas-chaulet/torch-points3d}}
}
และโปรดรวมการอ้างอิงถึงโมเดลหรือชุดข้อมูลที่คุณใช้ในการทดลองของคุณ!


