torch points3d
v 1.3.0
이것은 고전적인 벤치 마크에 대한 포인트 클라우드 분석 작업을위한 일반적인 딥 러닝 모델을 실행하기위한 프레임 워크입니다. 그것은 Pytorch 기하학 및 Facebook Hydra에 크게 의존합니다.
이 프레임 워크를 통해 최소한의 노력과 큰 재현성으로 마른적이고 아직 복잡한 모델을 구축 할 수 있습니다. 또한 Pointclouds에서 딥 러닝을 민주화하기 위해 높은 수준의 API를 제공합니다. 최첨단 네트워크의 프레임 워크 용량 및 벤치 마크에 대한 개요는 3DV의 논문을 참조하십시오.
보다 원활한 설정을 위해 Docker를 사용하는 것이 좋습니다. 이 접근법은 특히 특정 버전의 CUDA 및 Pytorch로 작업 할 때 호환성을 보장하고 설치 프로세스를 완화시킵니다. 다음과 같이 적절한 Docker 이미지를 가져올 수 있습니다.
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-devel환경을 설정 한 후 (기본적으로 또는 Docker를 통해) PIP를 사용하여 필요한 Python 패키지를 설치하십시오.
pip install torch-points3d├─ benchmark # Output from various benchmark runs
├─ conf # All configurations for training nad evaluation leave there
├─ notebooks # A collection of notebooks that allow result exploration and network debugging
├─ docker # Docker image that can be used for inference or training
├─ docs # All the doc
├─ eval.py # Eval script
├─ find_neighbour_dist.py # Script to find optimal #neighbours within neighbour search operations
├─ forward_scripts # Script that runs a forward pass on possibly non annotated data
├─ outputs # All outputs from your runs sorted by date
├─ scripts # Some scripts to help manage the project
├─ torch_points3d
├─ core # Core components
├─ datasets # All code related to datasets
├─ metrics # All metrics and trackers
├─ models # All models
├─ modules # Basic modules that can be used in a modular way
├─ utils # Various utils
└─ visualization # Visualization
├─ test
└─ train.py # Main script to launch a training일반적인 철학으로서 우리는 작업별로 데이터 세트와 모델을 분할했습니다. 예를 들어, 데이터 세트에는 5 개의 하위 폴더가 있습니다.
각 폴더에는 각 작업과 관련된 데이터 세트가 포함되어 있습니다.
API에서 직접 해당 모델에 액세스하려면 문서를 참조하고 자세한 내용은 KPCONV 및 RSCONV의 예제 노트를 참조하십시오.
작업 | 예 |
|---|---|
분류 / 부품 세분화 |  |
분할 |  |
물체 감지 | 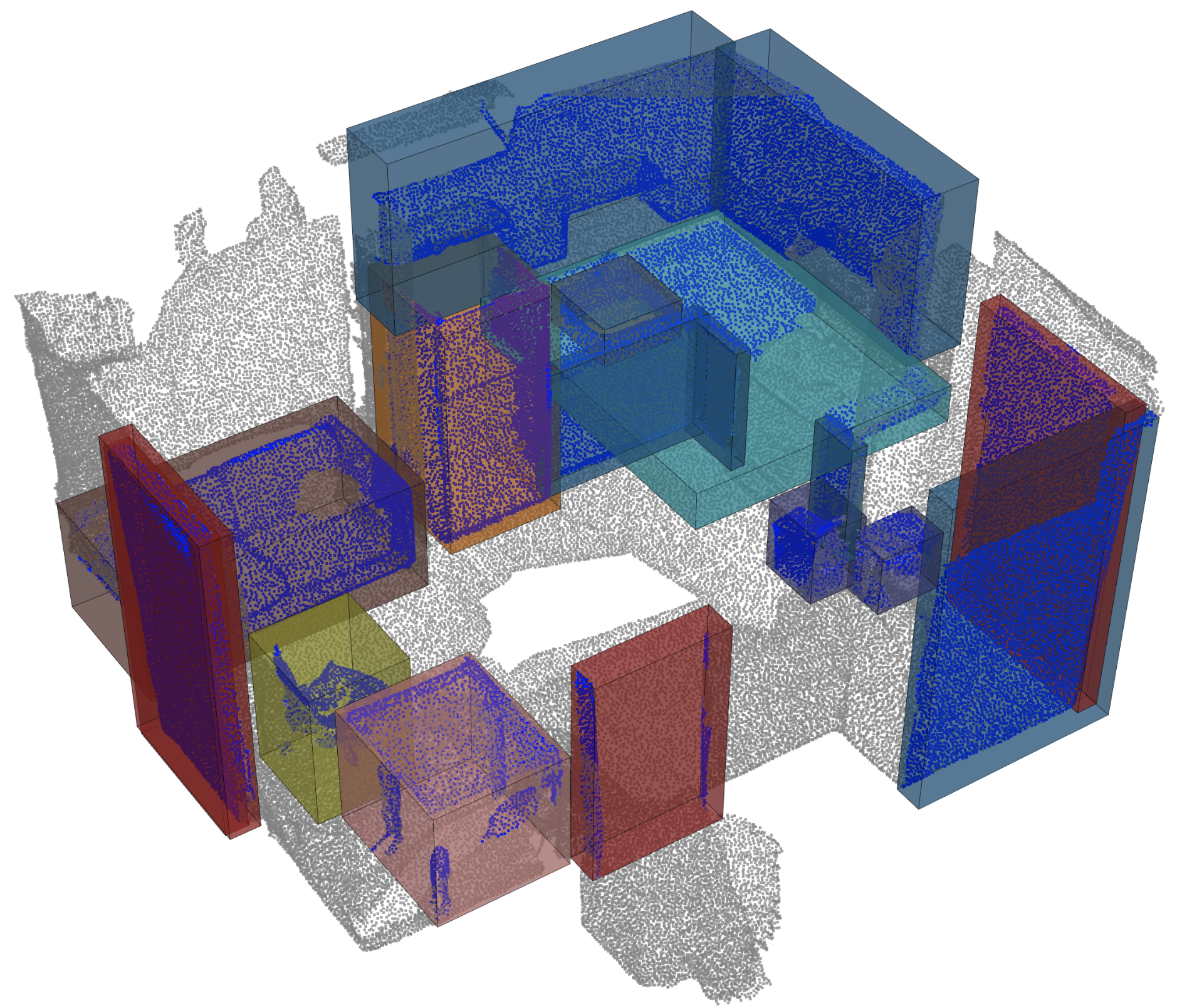 |
Panoptic 세분화 |  |
등록 |  |
Angela Dai et al. : Scannet : 실내 장면의 풍부한 3D 재구성
Iro Armeni et al. 의 S3DIS. : 실내 장면 이해를위한 Joint 2D-3D-Semantic 데이터
* S3DIS 1x1
* S3DIS Room
* S3DIS Fused - Sphere | Cylinder
* S3DIS Fused - Sphere | Cylinder
Andy Zeng et al . : 3DMATCH : RGB-D 재구성으로부터 로컬 기하학적 설명자 학습
Simone Fontana et al. 의 Iralab 벤치 마크. : Point Clouds 등록 알고리즘의 벤치 마크.
A. Geiger 등 의 교정 포즈 ( @Humanpose1 덕분)가있는 Kitti Odometry : 자율 주행 준비가 되셨습니까? Kitti Vision 벤치 마크 스위트
우리는 현재 Sparse 컨볼 루션의 백엔드로 Minkowski 엔진> V0.5 및 Torchsparse> = V1.4.0을 지원합니다. 이러한 패키지는 Torch Points3d와 독립적으로 설치해야합니다. 각 저장소의 설치 지침 및 문제 해결 메모를 따르십시오. 현재 MinkowskiEngine 참조하십시오 (Chris Choy에게 감사합니다)는 더 빠른 훈련을 보여줍니다. torchsparse 여전히 베타 버전에 있으며 CPU 전용 교육을 지원하지 않습니다.
이 두 개의 스파 스 컨볼 루션 프레임 워크 중 하나를 설정하면 사용을 시작할 수있는 수준이 높을 수 있습니다.
from torch_points3d . applications . sparseconv3d import SparseConv3d
model = SparseConv3d ( "unet" , input_nc = 3 , output_nc = 5 , num_layers = 4 , backend = "torchsparse" ) # minkowski by default 또한 torch_points3d/modules/SparseConv3d/nn 에 제공된 모듈을 사용하여 자체 네트워크를 조립할 수도 있습니다. 예를 들어 torchsparse 백엔드를 사용하려면 다음을 수행 할 수 있습니다.
import torch_points3d . modules . SparseConv3d as sp3d
sp3d . nn . set_backend ( "torchsparse" )
conv = sp3d . nn . Conv3d ( 10 , 10 )
bn = sp3d . nn . BatchNorm ( 10 ) 혼합 정밀도는 float16 에서 드문 컨볼 루션, 풀링 및 그라디언트 OP를 수행하여 GPU에서 메모리를 낮추고 약간 빠른 훈련 시간을 허용합니다. 혼합 정밀 교육은 현재 Torchsparse 백엔드를 사용한 SparseConv3d 네트워크에서 CUDA 교육을 위해 지원됩니다. 혼합 정밀도를 활성화하려면 pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git 과 함께 최신 버전의 Torchsparse가 있는지 확인하십시오. 그런 다음 교육 구성 파일에서 training.enable_mixed=True 설정하십시오. 모든 조건이 충족되면 훈련을 시작할 때 로그 항목이 표시됩니다.
[torch_points3d.models.base_model][INFO] - Model will use mixed precision
그러나 지원되지 않는 백엔드와 함께 혼합 정밀 훈련을 사용하려고하면 다음을 볼 수 있습니다.
[torch_points3d.models.base_model][WARNING] - Mixed precision is not supported on this model, using default precision...
PretrainedRegistry Registry를 사용하면 누구나 자신의 미리 훈련 된 모델을 추가하고 finetunning 또는 production 목적으로 2 줄의 코드로 re-create .
[You] Wandb Accizated ( wandb.log=True )로 모델 교육을 시작합니다.[TorchPoints3d] 훈련이 완료되면 TorchPoints3d 사용자 정의 체크 포인트 내에 훈련 된 모델을 Wandb에 업로드합니다.[You] PretainedRegistry 클래스 내에서 속성 MODELS 내에 key-value pair 추가하십시오. key 모델, 데이터 세트 및 교육 하이퍼 파라미터 (아마도 가장 좋은 모델)를 설명해야합니다. value WANDB에서 .pt 파일을 참조하는 url 이어야합니다. 예 : 키 : pointnet2_largemsg-s3dis-1 및 URL 값 : https://api.wandb.ai/files/loicland/benchmark-torch-points-3d-s3dis/1e1p0csk/pointnet2_largemsg.pt for the pointnet2_largemsg.pt 파일. 이 키는 pointnet2 largemsg trained on s3dis fold 1 desribes합니다.
[Anyone] PretainedRegistry 클래스를 사용하고 key 제공함으로써 관련 모델 가중치가 downloaded 되고 미리 훈련 된 모델은 변환과 함께 ready to use 있습니다. [ In ]:
from torch_points3d . applications . pretrained_api import PretainedRegistry
model = PretainedRegistry . from_pretrained ( "pointnet2_largemsg-s3dis-1" )
print ( model . wandb )
print ( model . print_transforms ())
[ Out ]:
== == == == == == == == == == == == == == == == == == == == == == == == == = WANDB URLS == == == == == == == == == == == == == == == == == == == == == == == == == == ==
WEIGHT_URL : https : // api . wandb . ai / files / loicland / benchmark - torch - points - 3 d - s3dis / 1e1 p0csk / pointnet2_largemsg . pt
LOG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / logs
CHART_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk
OVERVIEW_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / overview
HYDRA_CONFIG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / hydra - config . yaml
OVERRIDES_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / overrides . yaml
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
pre_transform = None
test_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
train_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
RandomNoise ( sigma = 0.001 , clip = 0.05 ),
RandomRotate (( - 180 , 180 ), axis = 2 ),
RandomScaleAnisotropic ([ 0.8 , 1.2 ]),
RandomAxesSymmetry ( x = True , y = False , z = False ),
DropFeature ( proba = 0.2 , feature = 'rgb' ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
val_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
inference_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
pre_collate_transform = Compose ([
PointCloudFusion (),
SaveOriginalPosId ,
GridSampling3D ( grid_size = 0.04 , quantize_coords = False , mode = mean ),
])우리는 패키지를 관리하기 위해시를 사용합니다. 시작하려면이 저장소를 복제하고 리포지토리의 루트에서 다음 명령을 실행하십시오.
poetry install --no-root
새로운 가상 환경에 필요한 모든 종속성을 설치합니다.
환경을 활성화하십시오
poetry shell실행하여 설치가 성공했는지 확인할 수 있습니다.
python -m unittest -v pycuda 지원의 경우 (등록 작업에만 필요) :
pip install pycudapoetry run python train.py task=segmentation models=segmentation/pointnet2 model_name=pointnet2_charlesssg data=segmentation/shapenet-fixed그리고 당신은 그런 것을보아야합니다
PointNet ++에 대한 구성은 모델을 정의하는 방법의 좋은 예이며 다음과 같습니다.
# PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (https://arxiv.org/abs/1706.02413)
# Credit Charles R. Qi: https://github.com/charlesq34/pointnet2/blob/master/models/pointnet2_part_seg_msg_one_hot.py
pointnet2_onehot :
architecture : pointnet2.PointNet2_D
conv_type : " DENSE "
use_category : True
down_conv :
module_name : PointNetMSGDown
npoint : [1024, 256, 64, 16]
radii : [[0.05, 0.1], [0.1, 0.2], [0.2, 0.4], [0.4, 0.8]]
nsamples : [[16, 32], [16, 32], [16, 32], [16, 32]]
down_conv_nn :
[
[[FEAT, 16, 16, 32], [FEAT, 32, 32, 64]],
[[32 + 64, 64, 64, 128], [32 + 64, 64, 96, 128]],
[[128 + 128, 128, 196, 256], [128 + 128, 128, 196, 256]],
[[256 + 256, 256, 256, 512], [256 + 256, 256, 384, 512]],
]
up_conv :
module_name : DenseFPModule
up_conv_nn :
[
[512 + 512 + 256 + 256, 512, 512],
[512 + 128 + 128, 512, 512],
[512 + 64 + 32, 256, 256],
[256 + FEAT, 128, 128],
]
skip : True
mlp_cls :
nn : [128, 128]
dropout : 0.5 우리는 주석이 달리지 않을 수있는 사용자 정의 데이터에 대해 주어진 사전 훈련 된 모델을 실행하기위한 스크립트를 제공합니다. Shapenet의 부품 세분화 작업에 대한 예를 찾을 수 있습니다. 나머지 코드베이스와 마찬가지로 대부분의 사용자 정의는 구성 파일을 통해 발생하며 제공된 예제는 다른 데이터 세트로 확장 될 수 있습니다. 거기에서 쉽게 직접 만들 수 있습니다. 부품 세분화 작업으로 돌아가서 비행기임을 알고있는 포인트 구름으로 가득 찬 폴더가 있으며 비행기 및 잠재적으로 다른 클래스에 대한 모델의 검사 점이 있으며 config.yaml 및 shapenet.yaml을 간단히 편집하고 다음 명령을 실행하십시오.
python forward_scripts/forward.py 순방향 실행 결과는 지정된 output_folder 에 배치되며 제공된 노트북을 사용하여 결과를 탐색 할 수 있습니다. 아래는 비행기 및 캡의 일부를 찾기 위해 캡에 훈련 된 모델을 사용한 결과의 예입니다.
마지막으로, 모델을 프로덕션 환경에 배치하는 데 관심이있는 사람들의 경우, 우리는 Dockerfile과 빌드 스크립트를 제공합니다. <outputfolder/weights.pt> 를 제공하는 시맨틱 세분화 네트워크를 훈련했다고 가정 해 봅시다.
cd docker
./build.sh outputfolder/weights.pt 그런 다음 input_path 의 모든 포인트 클라우드에서 전방 패스를 실행하고 output_path 에서 결과를 생성 할 수 있습니다.
docker run -v /test_data:/in -v /test_data/out:/out pointnet2_charlesssg:latest python3 forward_scripts/forward.py dataset=shapenet data.forward_category=Cap input_path= " /in " output_path= " /out " -v 옵션은 로컬 디렉토리를 컨테이너 파일 시스템에 장착합니다. 예를 들어 위의 명령 줄에서 /test_data/out 위치 /out 에 장착됩니다. 결과적으로, 인수 /out 으로 작성된 모든 파일은 컴퓨터의 폴더 /test_data/out 에서 사용할 수 있습니다.
우리는 snakeviz 와 cProfile 사용하도록 조언합니다
Cprofile을 사용하여 코드를 프로필하십시오
poetry run python -m cProfile -o {your_name}.prof train.py ... debugging.profiling=True
SnakeViz를 사용하여 결과를 시각화합니다.
snakeviz {your_name}.prof
torch.utils.bottleneck 사용할 수도 있습니다
python -m torch.utils.bottleneck /path/to/source/script.py [args]
최소한 Pytorch 1.8.0이 설치되어 있는지 확인하고 cuda/bin 및 cuda/include 각각 $PATH 와 $CPATH 에 있는지 확인하십시오.
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
$ echo $PATH
>>> /usr/local/cuda/bin:...
$ echo $CPATH
>>> /usr/local/cuda/include:...
사용되는 Pytorch 버전을 업데이트 할 때 컴파일 된 패키지를 다시 설치해야합니다. 그렇지 않으면 다음과 같은 오류가 발생합니다.
... scatter_cpu.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN3c1012CUDATensorIdEv
다음 라이브러리에서 발생할 수 있습니다.
이 문제를 해결하는 쉬운 방법은 가상 Env가 활성화 된 다음 명령을 실행하는 것입니다.
pip uninstall torch-scatter torch-sparse torch-cluster torch-points-kernels -y
rm -rf ~/.cache/pip
poetry install
이것은 torch-points-kernels 라이브러리를 컴파일하는 데 사용되는 것과 다른 GPU에서 코드를 실행하려고 할 때 발생할 수 있습니다. TORCH_CUDA_ARCH_LIST 환경 변수를 설정 한 후 torch-points-kernels , clear cache 및 다시 설치를 제거하십시오. 예를 들어, Tesla T4 (Turing 7.5)로 컴파일하고 Tesla V100 (Volta 7.0)에서 코드를 실행하기 위해 :
export TORCH_CUDA_ARCH_LIST="7.0;7.5"
더 많은 아키텍처 호환성은이 유용한 차트를 참조하십시오.
OSERROR wandb.log=false 높이기 OSError: [WinError 6] The handle is invalid wandb: ERROR W&B process failed to launch
우리는 과거 실험을 시각적으로 탐색 할 수있는 노트북 기반의 Pyvista 및 패널을 제공합니다. Jupyter Lab을 사용하는 경우 확장자를 설치해야합니다.
jupyter labextension install @pyviz/jupyterlab_pyviz
노트북을 통해 실행하면 다음과 같은 것처럼 보이는 대시 보드가 표시됩니다.
기부금을 환영합니다! 유일한 묻는 것은 스타일링을 고수하고 더 많은 기능을 추가 할 때 테스트를 추가한다는 것입니다!
스타일링을 위해서는 사전 커밋 후크를 사용하여 도움을 줄 수 있습니다.
pre-commit install
일련의 수표가 실행되며 고정 파일을 보관 된 파일에 다시 추가해야 할 수도 있습니다.
Docstrings와 관련하여 우리는 Numpy Style Docstrings를 사용합니다. Visual Studio Code를 사용하는 사람들에게는 도움이 될 수있는 훌륭한 확장이 있습니다. 그것을 설치하고 형식을 Numpy로 설정하면 가면 좋을 것입니다!
Finaly, 당신이 우리와 직접 채팅하고 싶다면 자유롭게 슬랙에 가입하십시오. 이메일을 보내 주시면 추가하겠습니다.
우리의 일이 유용하다고 생각되면 주저하지 말고 그것을 인용하십시오.
@inproceedings{
tp3d,
title={Torch-Points3D: A Modular Multi-Task Frameworkfor Reproducible Deep Learning on 3D Point Clouds},
author={Chaton, Thomas and Chaulet Nicolas and Horache, Sofiane and Landrieu, Loic},
booktitle={2020 International Conference on 3D Vision (3DV)},
year={2020},
organization={IEEE},
url = {url{https://github.com/nicolas-chaulet/torch-points3d}}
}
또한 실험에서 사용한 모델 또는 데이터 세트에 대한 인용도 포함하십시오!


