torch points3d
v 1.3.0
Il s'agit d'un cadre pour exécuter des modèles d'apprentissage en profondeur communs pour les tâches d'analyse des nuages de points contre la référence classique. Il repose fortement sur Pytorch Geométrique et Facebook Hydra.
Le cadre permet de construire un modèle maigre et pourtant complexe avec un minimum d'effort et une grande reproductibilité. Il fournit également une API de haut niveau pour démocratiser l'apprentissage en profondeur sur les points de point. Voir notre article sur 3DV pour un aperçu des capacités du cadre et des références des réseaux de pointe.
Pour une configuration plus transparente, il est recommandé d'utiliser Docker. Cette approche garantit la compatibilité et facilite le processus d'installation, en particulier lorsque vous travaillez avec des versions spécifiques de Cuda et Pytorch. Vous pouvez extraire l'image Docker appropriée comme suit:
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-develAprès avoir configuré l'environnement (nativement ou via Docker), installez le package Python requis à l'aide de PIP:
pip install torch-points3d├─ benchmark # Output from various benchmark runs
├─ conf # All configurations for training nad evaluation leave there
├─ notebooks # A collection of notebooks that allow result exploration and network debugging
├─ docker # Docker image that can be used for inference or training
├─ docs # All the doc
├─ eval.py # Eval script
├─ find_neighbour_dist.py # Script to find optimal #neighbours within neighbour search operations
├─ forward_scripts # Script that runs a forward pass on possibly non annotated data
├─ outputs # All outputs from your runs sorted by date
├─ scripts # Some scripts to help manage the project
├─ torch_points3d
├─ core # Core components
├─ datasets # All code related to datasets
├─ metrics # All metrics and trackers
├─ models # All models
├─ modules # Basic modules that can be used in a modular way
├─ utils # Various utils
└─ visualization # Visualization
├─ test
└─ train.py # Main script to launch a trainingEn tant que philosophie générale, nous avons divisé des ensembles de données et des modèles par tâche. Par exemple, les ensembles de données ont cinq sous-dossiers:
où chaque dossier contient l'ensemble de données lié à chaque tâche.
Veuillez vous référer à notre documentation pour accéder à certains de ces modèles directement à partir de l'API et consultez nos exemples de carnets pour KPCONV et RSCONV pour plus de détails.
Tâches | Exemples |
|---|---|
Classification / segmentation des pièces |  |
Segmentation |  |
Détection d'objet | 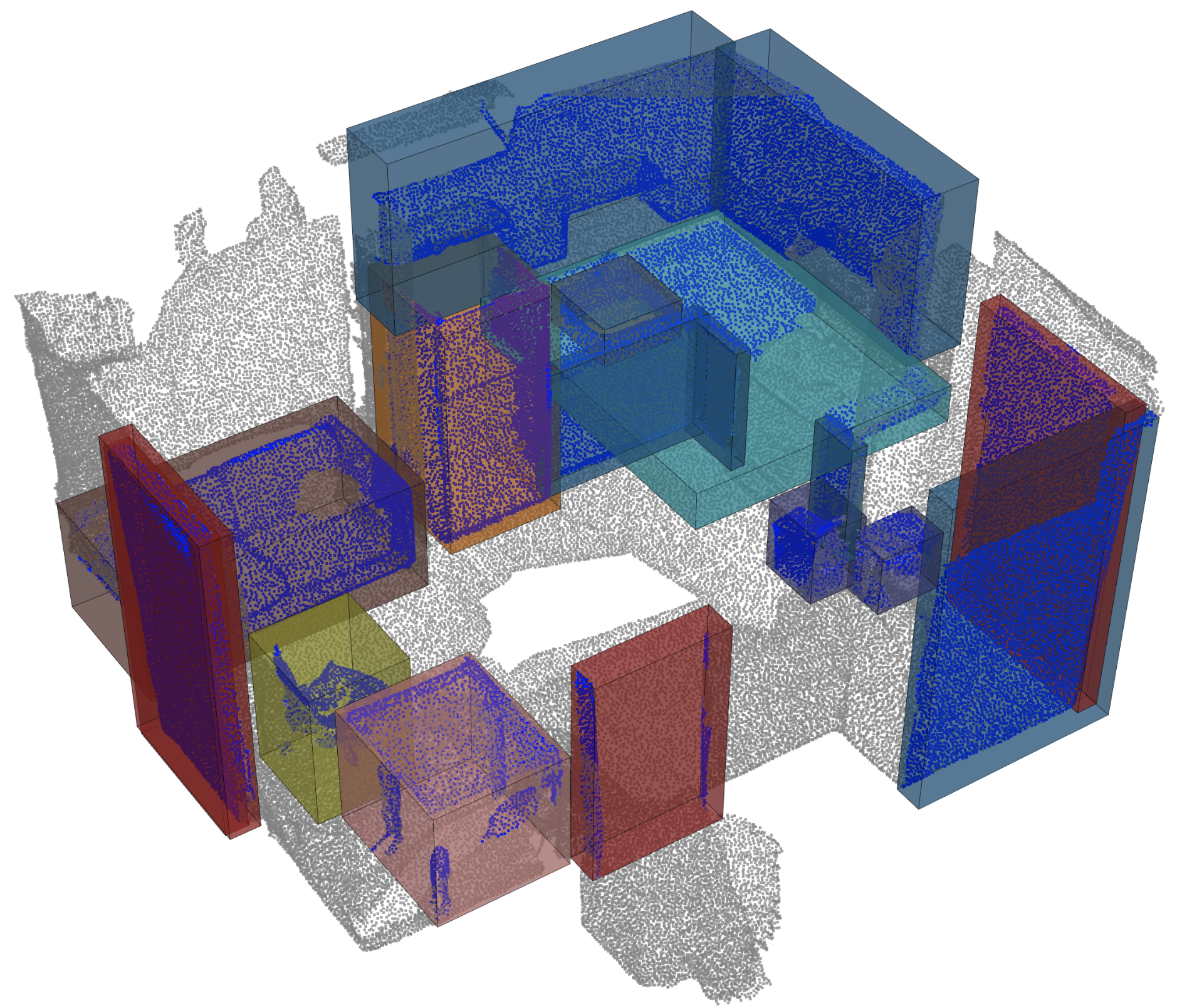 |
Segmentation panoptique |  |
Inscription |  |
Scannet d'Angela Dai et al. : Scanne: reconstructions 3D richement annotées des scènes intérieures
S3DIS d'Iro Armeni et al. : Données conjointes 2D-3D-Sémantique pour la compréhension de la scène intérieure
* S3DIS 1x1
* S3DIS Room
* S3DIS Fused - Sphere | Cylinder
* S3DIS Fused - Sphere | Cylinder
3dmatch d'Andy Zeng et al. : 3DMatch: Apprendre des descripteurs géométriques locaux des reconstructions RVB-D
La référence Iralab de Simone Fontana et al. : Une référence pour les algorithmes d'enregistrement des nuages ponctuels, qui est composé de données de:
L'odométrie Kitti avec des poses corrigées (grâce à @ HumanPose1) d'A. Geiger et al : sommes-nous prêts pour la conduite autonome? La suite de référence Kitti Vision
Nous prenons actuellement en charge le moteur Minkowski> V0.5 et Torchsparse> = v1.4.0 comme backends pour les convolutions clairsemées. Ces packages doivent être installés indépendamment de Torch Points3D, veuillez suivre les instructions d'installation et le dépannage des notes sur les référentiels respectifs. Pour le moment, MinkowskiEngine Voir ici (merci Chris Choy) démontre une formation plus rapide. Veuillez noter que torchsparse est toujours en version bêta et ne prend pas en charge la formation CPU uniquement.
Une fois que vous avez configuré l'un de ces deux cadre de convolution clairsemée, vous pouvez commencer à utiliser est un niveau élevé pour définir une épine dorsale de l'UNON ou simplement un encodeur:
from torch_points3d . applications . sparseconv3d import SparseConv3d
model = SparseConv3d ( "unet" , input_nc = 3 , output_nc = 5 , num_layers = 4 , backend = "torchsparse" ) # minkowski by default Vous pouvez également assembler vos propres réseaux en utilisant les modules fournis dans torch_points3d/modules/SparseConv3d/nn . Par exemple, si vous souhaitez utiliser le backend torchsparse vous pouvez effectuer ce qui suit:
import torch_points3d . modules . SparseConv3d as sp3d
sp3d . nn . set_backend ( "torchsparse" )
conv = sp3d . nn . Conv3d ( 10 , 10 )
bn = sp3d . nn . BatchNorm ( 10 ) La précision mixte permet une mémoire plus faible sur le GPU et des temps d'entraînement légèrement plus rapides en effectuant la convolution clairsemée, la mise en commun et les opérations de gradient dans float16 . La formation de précision mixte est actuellement soutenue pour la formation CUDA sur les réseaux SparseConv3d avec le backend Torchsparse. Pour activer la précision mixte, assurez-vous que vous disposez de la dernière version de Torchsparse avec pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git . Ensuite, définissez training.enable_mixed=True dans vos fichiers de configuration de formation. Si toutes les conditions sont remplies, lorsque vous commencez à vous entraîner, vous verrez une entrée de journal indiquant:
[torch_points3d.models.base_model][INFO] - Model will use mixed precision
Si, cependant, vous essayez d'utiliser une formation de précision mixte avec un backend non pris en charge, vous verrez:
[torch_points3d.models.base_model][WARNING] - Mixed precision is not supported on this model, using default precision...
Le PretrainedRegistry permet à quiconque d'ajouter ses propres modèles pré-formés et de les re-create avec seulement 2 lignes de code à des fins finetunning de production .
[You] lancez votre formation de modèle avec Wandb activé ( wandb.log=True )[TorchPoints3d] Une fois la formation terminée, TorchPoints3d téléchargera votre modèle formé dans notre point de contrôle personnalisé à votre WANDB.[You] Dans la classe PretainedRegistry , ajoutez une key-value pair dans ses MODELS d'attribut. La key doit être décrite votre modèle, votre ensemble de données et vos hyper-paramètres de formation (peut-être le meilleur modèle), la value devrait être l' url faisant référence au fichier .pt sur votre WANDB. Exemple: clé: pointnet2_largemsg-s3dis-1 et URL Valeur: https://api.wandb.ai/files/loicland/benchmark-torch-points-3d-s3dis/1e1p0csk/pointnet2_largemsg.pt pour le fichier pointnet2_largemsg.pt . La clé décrit un pointnet2 largemsg trained on s3dis fold 1 .
[Anyone] en utilisant la classe PretainedRegistry et en fournissant la key , les poids des modèles associés seront downloaded et le modèle pré-formé sera ready to use avec ses transformations. [ In ]:
from torch_points3d . applications . pretrained_api import PretainedRegistry
model = PretainedRegistry . from_pretrained ( "pointnet2_largemsg-s3dis-1" )
print ( model . wandb )
print ( model . print_transforms ())
[ Out ]:
== == == == == == == == == == == == == == == == == == == == == == == == == = WANDB URLS == == == == == == == == == == == == == == == == == == == == == == == == == == ==
WEIGHT_URL : https : // api . wandb . ai / files / loicland / benchmark - torch - points - 3 d - s3dis / 1e1 p0csk / pointnet2_largemsg . pt
LOG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / logs
CHART_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk
OVERVIEW_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / overview
HYDRA_CONFIG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / hydra - config . yaml
OVERRIDES_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / overrides . yaml
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
pre_transform = None
test_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
train_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
RandomNoise ( sigma = 0.001 , clip = 0.05 ),
RandomRotate (( - 180 , 180 ), axis = 2 ),
RandomScaleAnisotropic ([ 0.8 , 1.2 ]),
RandomAxesSymmetry ( x = True , y = False , z = False ),
DropFeature ( proba = 0.2 , feature = 'rgb' ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
val_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
inference_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
pre_collate_transform = Compose ([
PointCloudFusion (),
SaveOriginalPosId ,
GridSampling3D ( grid_size = 0.04 , quantize_coords = False , mode = mean ),
])Nous utilisons de la poésie pour gérer nos packages. Afin de commencer, clonez ces référentiels et exécutez la commande suivante à partir de la racine du repo
poetry install --no-root
Cela installera toutes les dépendances requises dans un nouvel environnement virtuel.
Activer l'environnement
poetry shellVous pouvez vérifier que l'installation a réussi en exécutant
python -m unittest -v Pour le soutien pycuda (nécessaire uniquement pour les tâches d'enregistrement):
pip install pycudapoetry run python train.py task=segmentation models=segmentation/pointnet2 model_name=pointnet2_charlesssg data=segmentation/shapenet-fixedEt tu devrais voir quelque chose comme ça
La configuration de PointNet ++ est un bon exemple de la façon de définir un modèle et est le suivant:
# PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (https://arxiv.org/abs/1706.02413)
# Credit Charles R. Qi: https://github.com/charlesq34/pointnet2/blob/master/models/pointnet2_part_seg_msg_one_hot.py
pointnet2_onehot :
architecture : pointnet2.PointNet2_D
conv_type : " DENSE "
use_category : True
down_conv :
module_name : PointNetMSGDown
npoint : [1024, 256, 64, 16]
radii : [[0.05, 0.1], [0.1, 0.2], [0.2, 0.4], [0.4, 0.8]]
nsamples : [[16, 32], [16, 32], [16, 32], [16, 32]]
down_conv_nn :
[
[[FEAT, 16, 16, 32], [FEAT, 32, 32, 64]],
[[32 + 64, 64, 64, 128], [32 + 64, 64, 96, 128]],
[[128 + 128, 128, 196, 256], [128 + 128, 128, 196, 256]],
[[256 + 256, 256, 256, 512], [256 + 256, 256, 384, 512]],
]
up_conv :
module_name : DenseFPModule
up_conv_nn :
[
[512 + 512 + 256 + 256, 512, 512],
[512 + 128 + 128, 512, 512],
[512 + 64 + 32, 256, 256],
[256 + FEAT, 128, 128],
]
skip : True
mlp_cls :
nn : [128, 128]
dropout : 0.5 Nous fournissons un script pour exécuter un modèle pré-formé donné sur des données personnalisées qui peuvent ne pas être annotées. Vous en trouverez un exemple pour la tâche de segmentation des pièces sur ShapeNet. Tout comme pour le reste de la base de code, la plupart de la personnalisation se produit via des fichiers de configuration et l'exemple fourni peut être étendu à d'autres ensembles de données. Vous pouvez également facilement créer le vôtre à partir de là. Pour en revenir à la tâche de segmentation des pièces, disons que vous avez un dossier plein de nuages ponctuels que vous savez être des avions, et que vous avez le point de contrôle d'un modèle formé sur les avions et potentiellement d'autres classes, modifiez simplement la configyre.yaml et shapmenet.yaml et exécutez la commande suivante:
python forward_scripts/forward.py Le résultat de l'exécution vers l'avant sera placé dans la output_folder spécifiée_folder et vous pouvez utiliser le cahier fourni pour explorer les résultats. Vous trouverez ci-dessous un exemple de l'issue de l'utilisation d'un modèle formé sur des plafonds uniquement pour trouver les parties des avions et des bouchons.
Enfin, pour les personnes intéressées à déployer leurs modèles dans des environnements de production, nous fournissons un dockerfile ainsi qu'un script de construction. Dites que vous avez formé un réseau de segmentation sémantique qui a donné le poids <outputfolder/weights.pt> , la commande suivante créera une image Docker pour vous:
cd docker
./build.sh outputfolder/weights.pt Vous pouvez ensuite l'utiliser pour exécuter une passe en avant sur tous les nuages de points dans input_path et générer les résultats dans output_path
docker run -v /test_data:/in -v /test_data/out:/out pointnet2_charlesssg:latest python3 forward_scripts/forward.py dataset=shapenet data.forward_category=Cap input_path= " /in " output_path= " /out " L'option -v monte un répertoire local dans le système de fichiers du conteneur. Par exemple dans la ligne de commande ci-dessus, /test_data/out sera monté à l'emplacement /out . En conséquence, tous les fichiers écrits /out seront disponibles dans le dossier /test_data/out sur votre machine.
Nous conseillons d'utiliser snakeviz et cProfile
Utilisez CPROFILE pour profil votre code
poetry run python -m cProfile -o {your_name}.prof train.py ... debugging.profiling=True
Et visualiser les résultats à l'aide de Snakeviz.
snakeviz {your_name}.prof
Il est également possible d'utiliser torch.utils.bottleneck
python -m torch.utils.bottleneck /path/to/source/script.py [args]
Assurez-vous qu'au moins Pytorch 1.8.0 est installé et vérifiez que cuda/bin et cuda/include sont respectivement dans votre $PATH et $CPATH , par exemple:
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
$ echo $PATH
>>> /usr/local/cuda/bin:...
$ echo $CPATH
>>> /usr/local/cuda/include:...
Lorsque nous mettons à jour la version de Pytorch utilisée, les packages compilés doivent être réinstallés, sinon vous comptez une erreur qui ressemble à ceci:
... scatter_cpu.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN3c1012CUDATensorIdEv
Cela peut arriver pour les bibliothèques suivantes:
Un moyen facile de résoudre ce problème consiste à exécuter la commande suivante avec le virtual Env activé:
pip uninstall torch-scatter torch-sparse torch-cluster torch-points-kernels -y
rm -rf ~/.cache/pip
poetry install
Cela peut se produire lorsque vous essayez d'exécuter le code sur un GPU différent de celui utilisé pour compiler la bibliothèque torch-points-kernels . Désinstaller torch-points-kernels , effacer le cache et réinstaller après la définition de la variable d'environnement TORCH_CUDA_ARCH_LIST . Par exemple, pour compiler avec un Tesla T4 (Turing 7.5) et exécuter le code sur une utilisation Tesla V100 (Volta 7.0):
export TORCH_CUDA_ARCH_LIST="7.0;7.5"
Voir ce graphique utile pour plus de compatibilité en architecture.
Rassement OSError: [WinError 6] The handle is invalid / wandb: ERROR W&B process failed to launch Wandb est actuellement rompu sur Windows (voir ce problème), une solution de contournement est d'utiliser l'argument de la ligne de commande wandb.log=false
Nous fournissons un Pyvista et un panneau basés sur un cahier qui vous permet d'explorer vos expériences passées visuellement. Lorsque vous utilisez Jupyter Lab, vous devrez installer une extension:
jupyter labextension install @pyviz/jupyterlab_pyviz
Exécutez le cahier et vous devriez voir un tableau de bord démarré qui ressemble à ce qui suit:
Les contributions sont les bienvenues! Les seuls à demander, c'est que vous vous en tenez au style et que vous ajoutez des tests lorsque vous ajoutez plus de fonctionnalités!
Pour le style, vous pouvez utiliser des crochets de pré-engagement pour vous aider:
pre-commit install
Une séquence de chèques sera exécutée pour vous et vous devrez peut-être ajouter à nouveau les fichiers fixes aux fichiers cachés.
En ce qui concerne les docstrings, nous utilisons les docstrings de style Numpy, pour ceux qui utilisent le code Visual Studio, il y a une excellente extension qui peut vous aider. Installez-le et définissez le format sur Numpy et vous devriez être prêt à partir!
Finaly, si vous voulez avoir une conversation directe avec nous, n'hésitez pas à rejoindre notre Slack, il suffit de nous tirer un e-mail et nous vous ajouterons.
Si vous trouvez notre travail utile, n'hésitez pas à le citer:
@inproceedings{
tp3d,
title={Torch-Points3D: A Modular Multi-Task Frameworkfor Reproducible Deep Learning on 3D Point Clouds},
author={Chaton, Thomas and Chaulet Nicolas and Horache, Sofiane and Landrieu, Loic},
booktitle={2020 International Conference on 3D Vision (3DV)},
year={2020},
organization={IEEE},
url = {url{https://github.com/nicolas-chaulet/torch-points3d}}
}
Et veuillez également inclure une citation aux modèles ou aux ensembles de données que vous avez utilisés dans vos expériences!


