torch points3d
v 1.3.0
Ini adalah kerangka kerja untuk menjalankan model pembelajaran mendalam umum untuk tugas analisis cloud point terhadap benchmark klasik. Sangat bergantung pada Pytorch Geometric dan Facebook Hydra.
Kerangka kerja ini memungkinkan model ramping namun kompleks untuk dibangun dengan upaya minimum dan reproduktifitas yang hebat. Ini juga memberikan API tingkat tinggi untuk mendemokratisasi pembelajaran mendalam pada pointclouds. Lihat makalah kami di 3DV untuk ikhtisar kapasitas kerangka kerja dan tolok ukur jaringan canggih.
Untuk pengaturan yang lebih mulus, disarankan untuk menggunakan Docker. Pendekatan ini memastikan kompatibilitas dan memudahkan proses pemasangan, terutama ketika bekerja dengan versi spesifik CUDA dan Pytorch. Anda dapat menarik gambar Docker yang sesuai sebagai berikut:
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-develSetelah menyiapkan lingkungan (baik secara asli atau melalui Docker), pasang paket Python yang diperlukan menggunakan PIP:
pip install torch-points3d├─ benchmark # Output from various benchmark runs
├─ conf # All configurations for training nad evaluation leave there
├─ notebooks # A collection of notebooks that allow result exploration and network debugging
├─ docker # Docker image that can be used for inference or training
├─ docs # All the doc
├─ eval.py # Eval script
├─ find_neighbour_dist.py # Script to find optimal #neighbours within neighbour search operations
├─ forward_scripts # Script that runs a forward pass on possibly non annotated data
├─ outputs # All outputs from your runs sorted by date
├─ scripts # Some scripts to help manage the project
├─ torch_points3d
├─ core # Core components
├─ datasets # All code related to datasets
├─ metrics # All metrics and trackers
├─ models # All models
├─ modules # Basic modules that can be used in a modular way
├─ utils # Various utils
└─ visualization # Visualization
├─ test
└─ train.py # Main script to launch a trainingSebagai filosofi umum, kami memiliki dataset dan model yang terpecah berdasarkan tugas. Misalnya, dataset memiliki lima subfolder:
di mana setiap folder berisi dataset yang terkait dengan setiap tugas.
Silakan merujuk ke dokumentasi kami untuk mengakses beberapa model tersebut secara langsung dari API dan lihat contoh notebook kami untuk KPCONV dan RSCONV untuk detail lebih lanjut.
Tugas | Contoh |
|---|---|
Segmentasi Klasifikasi / Bagian |  |
Segmentasi |  |
Deteksi Objek | 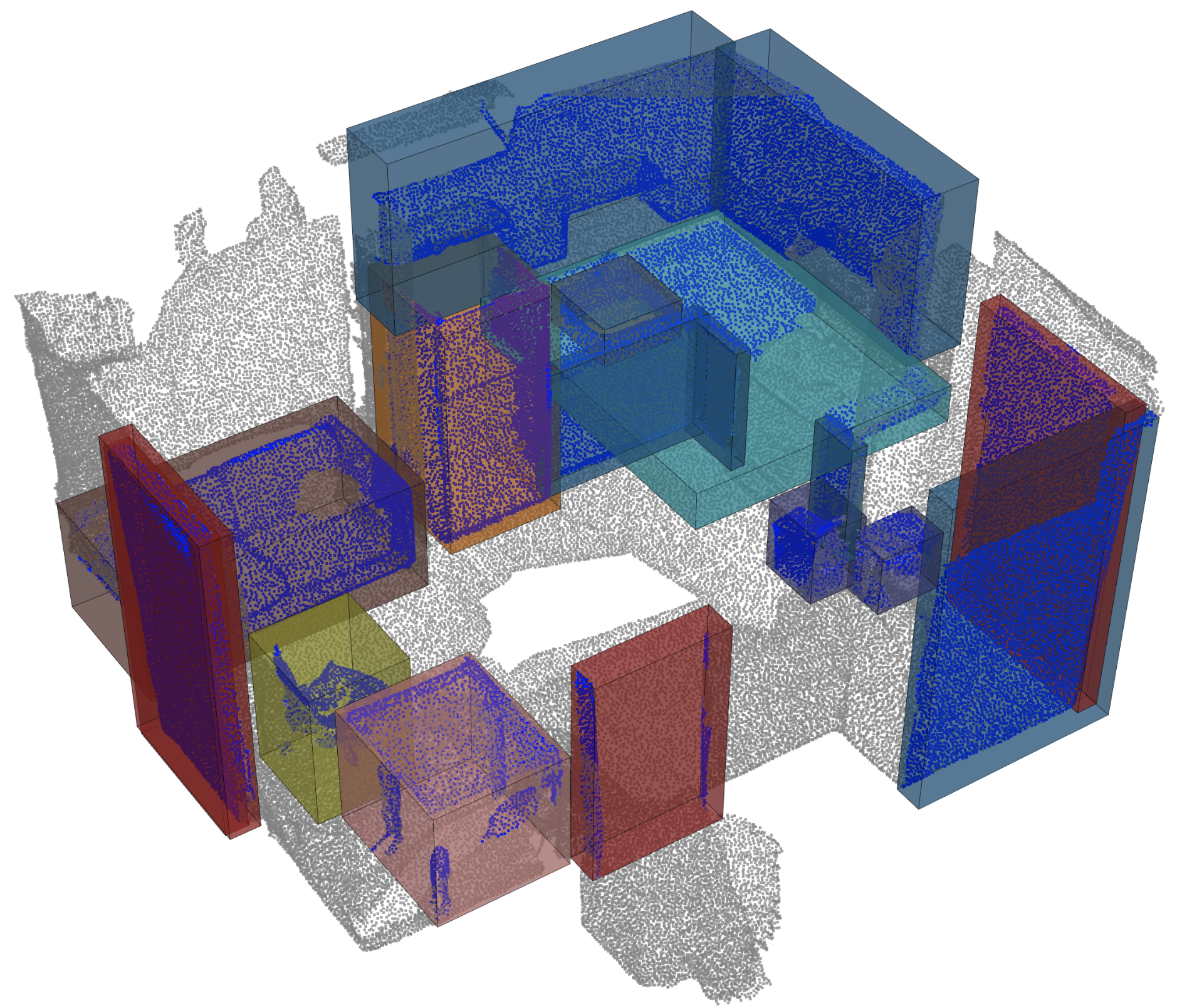 |
Segmentasi panoptik |  |
Pendaftaran |  |
Scannet dari Angela Dai et al. : Scannet: Rekonstruksi 3D yang dianotasi dengan kaya akan adegan dalam ruangan
S3DIS dari Iro Armeni et al. : Data bersama 2D-3D-Semantik untuk pemahaman adegan dalam ruangan
* S3DIS 1x1
* S3DIS Room
* S3DIS Fused - Sphere | Cylinder
* S3DIS Fused - Sphere | Cylinder
3DMatch dari Andy Zeng et al. : 3DMATCH: Belajar deskriptor geometris lokal dari rekonstruksi RGB-D
Benchmark Iralab dari Simone Fontana et al. : Benchmark untuk algoritma pendaftaran awan titik, yang terdiri dari data dari:
Kitti Odometry dengan Pose Terkoreksi (terima kasih kepada @Humanpose1) dari A. Geiger et al : Apakah kita siap untuk mengemudi secara otonom? Suite Benchmark Visi Kitti
Kami saat ini mendukung mesin Minkowski> V0.5 dan Torchsparse> = v1.4.0 sebagai backend untuk konvolusi yang jarang. Paket -paket itu perlu diinstal secara independen dari Torch Points3D, silakan ikuti instruksi instalasi dan pemecahan masalah pada repositori masing -masing. Saat ini MinkowskiEngine lihat di sini (terima kasih Chris Choy) menunjukkan pelatihan yang lebih cepat. Perlu diketahui bahwa torchsparse masih dalam beta dan tidak mendukung pelatihan CPU saja.
Setelah Anda mengatur salah satu dari dua kerangka kerja konvolusi yang jarang yang dapat Anda gunakan adalah level tinggi untuk mendefinisikan tulang punggung yang tidak ada atau sekadar encoder:
from torch_points3d . applications . sparseconv3d import SparseConv3d
model = SparseConv3d ( "unet" , input_nc = 3 , output_nc = 5 , num_layers = 4 , backend = "torchsparse" ) # minkowski by default Anda juga dapat merakit jaringan Anda sendiri dengan menggunakan modul yang disediakan di torch_points3d/modules/SparseConv3d/nn . Misalnya jika Anda ingin menggunakan backend torchsparse Anda dapat melakukan hal berikut:
import torch_points3d . modules . SparseConv3d as sp3d
sp3d . nn . set_backend ( "torchsparse" )
conv = sp3d . nn . Conv3d ( 10 , 10 )
bn = sp3d . nn . BatchNorm ( 10 ) Presisi campuran memungkinkan untuk memori yang lebih rendah pada GPU dan waktu pelatihan yang sedikit lebih cepat dengan melakukan konvolusi, pengumpulan, dan gradien yang jarang di float16 . Pelatihan presisi campuran saat ini didukung untuk pelatihan CUDA tentang jaringan SparseConv3d dengan backend Torchsparse. Untuk mengaktifkan presisi campuran, pastikan Anda memiliki versi terbaru dari Torchsparse dengan pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git . Kemudian, atur training.enable_mixed=True di file konfigurasi pelatihan Anda. Jika semua kondisi terpenuhi, saat Anda mulai berlatih, Anda akan melihat entri log yang menyatakan:
[torch_points3d.models.base_model][INFO] - Model will use mixed precision
Namun, jika Anda mencoba menggunakan pelatihan presisi campuran dengan backend yang tidak didukung, Anda akan melihat:
[torch_points3d.models.base_model][WARNING] - Mixed precision is not supported on this model, using default precision...
DREGISTRY PretrainedRegistry memungkinkan siapa pun untuk menambahkan model pra-terlatih mereka sendiri dan re-create dengan hanya 2 baris kode untuk tujuan finetunning atau production .
[You] Luncurkan Pelatihan Model Anda dengan Wandb Activated ( wandb.log=True )[TorchPoints3d] Setelah pelatihan selesai, TorchPoints3d akan mengunggah model terlatih Anda di dalam pos pemeriksaan khusus kami ke Wandb Anda.[You] dalam kelas PretainedRegistry , tambahkan key-value pair dalam MODELS atributnya. key harus menjelaskan model, dataset, dan pelatihan hyper-parameter Anda (mungkin model terbaik), value harus menjadi url yang merujuk file .pt pada wandb Anda. Contoh: Kunci: pointnet2_largemsg-s3dis-1 dan nilai url: https://api.wandb.ai/files/loicland/benchmark-torch-points-3d-s3dis/1e1p0csk/pointnet2_largemsg.pt untuk pointnet2_largemsg.pt untuk pointnet2_largem.largemsg.largemsg.largem.largem.largem.largem.largem.largem.largem.largem.largem.larg. Kunci desribes pointnet2 largemsg trained on s3dis fold 1 .
[Anyone] dengan menggunakan kelas PretainedRegistry dan dengan memberikan key , bobot model terkait akan downloaded dan model pra-terlatih akan ready to use dengan transformasi. [ In ]:
from torch_points3d . applications . pretrained_api import PretainedRegistry
model = PretainedRegistry . from_pretrained ( "pointnet2_largemsg-s3dis-1" )
print ( model . wandb )
print ( model . print_transforms ())
[ Out ]:
== == == == == == == == == == == == == == == == == == == == == == == == == = WANDB URLS == == == == == == == == == == == == == == == == == == == == == == == == == == ==
WEIGHT_URL : https : // api . wandb . ai / files / loicland / benchmark - torch - points - 3 d - s3dis / 1e1 p0csk / pointnet2_largemsg . pt
LOG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / logs
CHART_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk
OVERVIEW_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / overview
HYDRA_CONFIG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / hydra - config . yaml
OVERRIDES_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / overrides . yaml
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
pre_transform = None
test_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
train_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
RandomNoise ( sigma = 0.001 , clip = 0.05 ),
RandomRotate (( - 180 , 180 ), axis = 2 ),
RandomScaleAnisotropic ([ 0.8 , 1.2 ]),
RandomAxesSymmetry ( x = True , y = False , z = False ),
DropFeature ( proba = 0.2 , feature = 'rgb' ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
val_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
inference_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
pre_collate_transform = Compose ([
PointCloudFusion (),
SaveOriginalPosId ,
GridSampling3D ( grid_size = 0.04 , quantize_coords = False , mode = mean ),
])Kami menggunakan puisi untuk mengelola paket kami. Untuk memulai, klon repositori ini dan jalankan perintah berikut dari akar repo
poetry install --no-root
Ini akan menginstal semua dependensi yang diperlukan di lingkungan virtual baru.
Aktifkan lingkungan
poetry shellAnda dapat memeriksa bahwa instalasi telah berhasil dengan berjalan
python -m unittest -v Untuk dukungan pycuda (hanya diperlukan untuk tugas pendaftaran):
pip install pycudapoetry run python train.py task=segmentation models=segmentation/pointnet2 model_name=pointnet2_charlesssg data=segmentation/shapenet-fixedDan Anda harus melihat sesuatu seperti itu
Konfigurasi untuk PointNet ++ adalah contoh yang baik tentang cara mendefinisikan model dan sebagai berikut:
# PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (https://arxiv.org/abs/1706.02413)
# Credit Charles R. Qi: https://github.com/charlesq34/pointnet2/blob/master/models/pointnet2_part_seg_msg_one_hot.py
pointnet2_onehot :
architecture : pointnet2.PointNet2_D
conv_type : " DENSE "
use_category : True
down_conv :
module_name : PointNetMSGDown
npoint : [1024, 256, 64, 16]
radii : [[0.05, 0.1], [0.1, 0.2], [0.2, 0.4], [0.4, 0.8]]
nsamples : [[16, 32], [16, 32], [16, 32], [16, 32]]
down_conv_nn :
[
[[FEAT, 16, 16, 32], [FEAT, 32, 32, 64]],
[[32 + 64, 64, 64, 128], [32 + 64, 64, 96, 128]],
[[128 + 128, 128, 196, 256], [128 + 128, 128, 196, 256]],
[[256 + 256, 256, 256, 512], [256 + 256, 256, 384, 512]],
]
up_conv :
module_name : DenseFPModule
up_conv_nn :
[
[512 + 512 + 256 + 256, 512, 512],
[512 + 128 + 128, 512, 512],
[512 + 64 + 32, 256, 256],
[256 + FEAT, 128, 128],
]
skip : True
mlp_cls :
nn : [128, 128]
dropout : 0.5 Kami menyediakan skrip untuk menjalankan model pra -terlatih yang diberikan pada data khusus yang mungkin tidak dijelaskan. Anda akan menemukan contoh ini untuk tugas segmentasi bagian di Shapenet. Sama seperti untuk basis kode lainnya sebagian besar kustomisasi terjadi melalui file konfigurasi dan contoh yang disediakan dapat diperluas ke set data lainnya. Anda juga dapat dengan mudah membuat sendiri dari sana. Kembali ke tugas segmentasi bagian, katakanlah Anda memiliki folder yang penuh dengan awan titik yang Anda tahu adalah pesawat terbang, dan Anda memiliki pos pemeriksaan model yang dilatih di pesawat terbang dan berpotensi kelas lain, cukup edit config.yaml dan capenet.yaml dan jalankan perintah berikut:
python forward_scripts/forward.py Hasil dari forward run akan ditempatkan di output_folder yang ditentukan dan Anda dapat menggunakan notebook yang disediakan untuk mengeksplorasi hasilnya. Di bawah ini adalah contoh hasil menggunakan model yang dilatih pada tutup hanya untuk menemukan bagian -bagian pesawat terbang dan tutup.
Akhirnya, untuk orang -orang yang tertarik untuk menggunakan model mereka ke lingkungan produksi, kami menyediakan DockerFile serta skrip build. Katakanlah Anda telah melatih jaringan untuk segmentasi semantik yang memberikan bobot <outputfolder/weights.pt> , perintah berikut akan membangun gambar Docker untuk Anda:
cd docker
./build.sh outputfolder/weights.pt Anda kemudian dapat menggunakannya untuk menjalankan umpan ke depan pada semua awan titik di input_path dan menghasilkan hasil di output_path
docker run -v /test_data:/in -v /test_data/out:/out pointnet2_charlesssg:latest python3 forward_scripts/forward.py dataset=shapenet data.forward_category=Cap input_path= " /in " output_path= " /out " Opsi -v memasang direktori lokal ke sistem file wadah. Misalnya dalam baris perintah di atas, /test_data/out akan dipasang di lokasi /out . Sebagai akibatnya, semua file yang ditulis masuk /out akan tersedia di folder /test_data/out di mesin Anda.
Kami saran untuk menggunakan snakeviz dan cProfile
Gunakan CProfile untuk membuat profil kode Anda
poetry run python -m cProfile -o {your_name}.prof train.py ... debugging.profiling=True
Dan memvisualisasikan hasil menggunakan snakeviz.
snakeviz {your_name}.prof
Dimungkinkan juga untuk menggunakan torch.utils.bottleneck
python -m torch.utils.bottleneck /path/to/source/script.py [args]
Pastikan bahwa setidaknya Pytorch 1.8.0 diinstal dan verifikasi bahwa cuda/bin dan cuda/include ada di $PATH Anda dan $CPATH masing -masing, misalnya:
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
$ echo $PATH
>>> /usr/local/cuda/bin:...
$ echo $CPATH
>>> /usr/local/cuda/include:...
Saat kami memperbarui versi Pytorch yang digunakan, paket yang dikompilasi perlu diinstal ulang, jika tidak, Anda akan mengalami kesalahan yang terlihat seperti ini:
... scatter_cpu.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN3c1012CUDATensorIdEv
Ini bisa terjadi untuk perpustakaan berikut:
Cara mudah untuk memperbaikinya adalah dengan menjalankan perintah berikut dengan env virtual diaktifkan:
pip uninstall torch-scatter torch-sparse torch-cluster torch-points-kernels -y
rm -rf ~/.cache/pip
poetry install
Ini dapat terjadi ketika mencoba menjalankan kode pada GPU yang berbeda dari yang digunakan untuk mengkompilasi pustaka torch-points-kernels . Hapus instalan torch-points-kernels , Clear Cache, dan instal ulang setelah mengatur variabel lingkungan TORCH_CUDA_ARCH_LIST . Misalnya, untuk menyusun dengan Tesla T4 (Turing 7.5) dan menjalankan kode pada Tesla V100 (Volta 7.0) Gunakan:
export TORCH_CUDA_ARCH_LIST="7.0;7.5"
Lihat grafik yang berguna ini untuk kompatibilitas arsitektur yang lebih banyak.
Meningkatkan OSError: [WinError 6] The handle is invalid / wandb: ERROR W&B process failed to launch Wandb saat ini rusak di windows (lihat masalah ini), solusi adalah menggunakan argumen baris perintah wandb.log=false
Kami menyediakan pyvista dan panel berbasis notebook yang memungkinkan Anda menjelajahi eksperimen masa lalu Anda secara visual. Saat menggunakan Jupyter Lab, Anda harus menginstal ekstensi:
jupyter labextension install @pyviz/jupyterlab_pyviz
Jalankan melalui notebook dan Anda akan melihat dashboard mulai yang terlihat seperti berikut:
Kontribusi dipersilakan! Satu -satunya meminta adalah Anda tetap berpegang pada gaya dan Anda menambahkan tes saat Anda menambahkan lebih banyak fitur!
Untuk gaya Anda dapat menggunakan kait pra-komit untuk membantu Anda:
pre-commit install
Urutan cek akan dijalankan untuk Anda dan Anda mungkin harus menambahkan file tetap lagi ke file yang disimpan.
Ketika datang ke Docstrings kami menggunakan Docstrings Gaya Numpy, bagi mereka yang menggunakan kode Visual Studio, ada ekstensi hebat yang dapat membantu dengan itu. Instal dan atur format ke Numpy dan Anda harus baik untuk pergi!
Terakhir, jika Anda ingin mengobrol langsung dengan kami, jangan ragu untuk bergabung dengan Slack kami, cukup buang email kepada kami dan kami akan menambahkan Anda.
Jika Anda menganggap pekerjaan kami bermanfaat, jangan ragu untuk mengutipnya:
@inproceedings{
tp3d,
title={Torch-Points3D: A Modular Multi-Task Frameworkfor Reproducible Deep Learning on 3D Point Clouds},
author={Chaton, Thomas and Chaulet Nicolas and Horache, Sofiane and Landrieu, Loic},
booktitle={2020 International Conference on 3D Vision (3DV)},
year={2020},
organization={IEEE},
url = {url{https://github.com/nicolas-chaulet/torch-points3d}}
}
Dan tolong juga sertakan kutipan untuk model atau set data yang telah Anda gunakan dalam percobaan Anda!


