torch points3d
v 1.3.0
Это основа для выполнения общих моделей глубокого обучения для задач анализа облаков точечных облаков против классического эталона. Это в значительной степени полагается на геометрическую и Facebook Hydra.
Структура позволяет построить худой, но все же сложную модель с минимальными усилиями и большой воспроизводимостью. Это также обеспечивает API высокого уровня для демократизации глубокого обучения на точечных областях. Смотрите нашу статью на 3DV для обзора структурных возможностей и критериев современных сетей.
Для более беспроблемной настройки рекомендуется использовать Docker. Этот подход обеспечивает совместимость и облегчает процесс установки, особенно при работе с конкретными версиями CUDA и Pytorch. Вы можете вытащить соответствующее изображение Docker следующим образом:
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-develПосле настройки среды (изначально или через Docker) установите необходимый пакет Python, используя PIP:
pip install torch-points3d├─ benchmark # Output from various benchmark runs
├─ conf # All configurations for training nad evaluation leave there
├─ notebooks # A collection of notebooks that allow result exploration and network debugging
├─ docker # Docker image that can be used for inference or training
├─ docs # All the doc
├─ eval.py # Eval script
├─ find_neighbour_dist.py # Script to find optimal #neighbours within neighbour search operations
├─ forward_scripts # Script that runs a forward pass on possibly non annotated data
├─ outputs # All outputs from your runs sorted by date
├─ scripts # Some scripts to help manage the project
├─ torch_points3d
├─ core # Core components
├─ datasets # All code related to datasets
├─ metrics # All metrics and trackers
├─ models # All models
├─ modules # Basic modules that can be used in a modular way
├─ utils # Various utils
└─ visualization # Visualization
├─ test
└─ train.py # Main script to launch a trainingВ качестве общей философии мы разделили наборы данных и модели по заданию. Например, наборы данных имеют пять подпадок:
где каждая папка содержит набор данных, связанный с каждой задачей.
Пожалуйста, обратитесь к нашей документации для доступа к некоторым из этих моделей непосредственно из API, и см. В нашем примере записных книг для KPConv и RSConv для получения более подробной информации.
Задачи | Примеры |
|---|---|
Классификация / сегментация части |  |
Сегментация |  |
Обнаружение объекта | 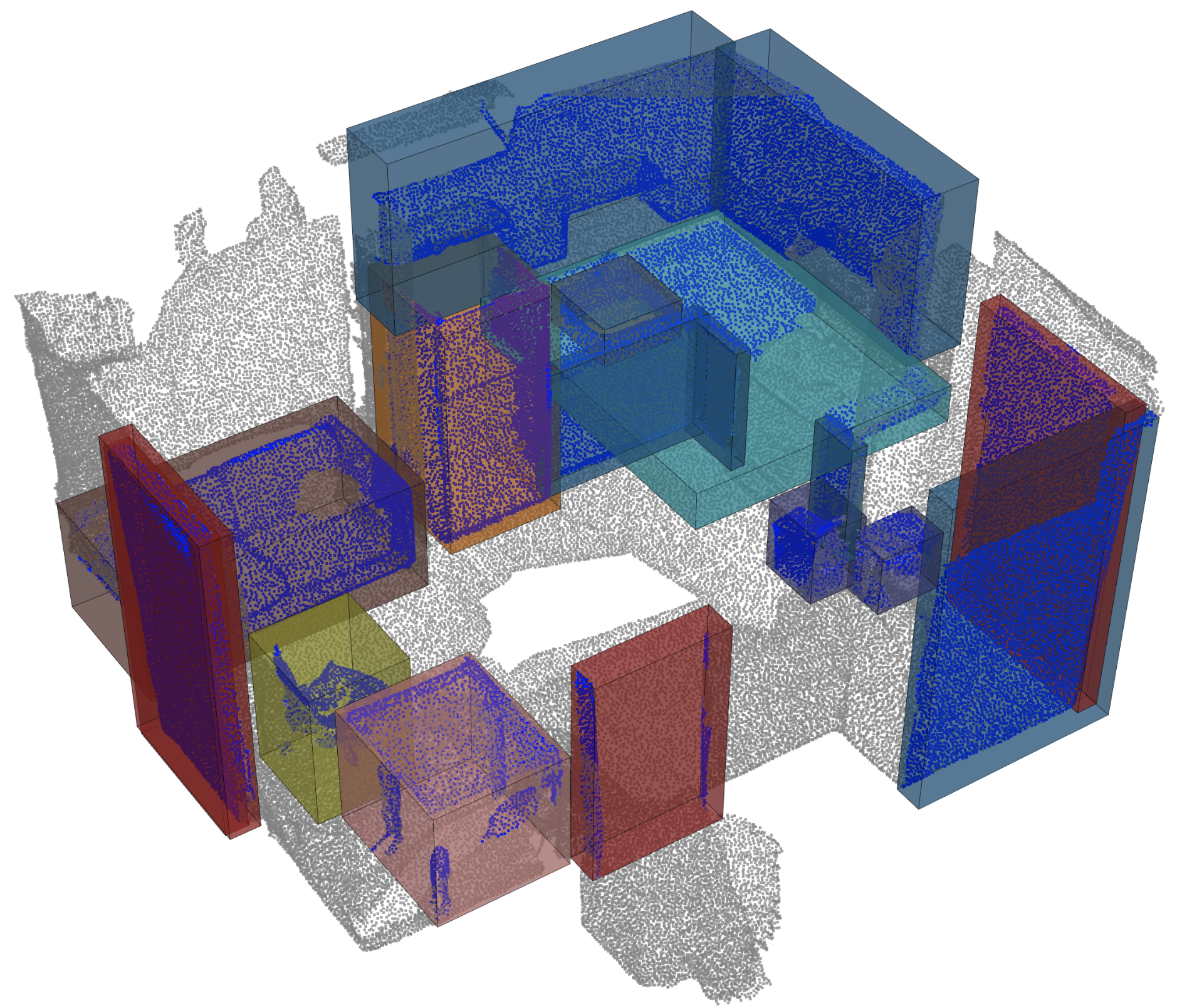 |
Паноптическая сегментация |  |
Регистрация |  |
Сканат от Анжелы Дай и соавт. : Scannet: богато аннотированные 3D-реконструкции внутренних сцен
S3DI от Iro Armeni et al. : Совместные 2D-3D-Семантические данные для понимания сцены в помещении
* S3DIS 1x1
* S3DIS Room
* S3DIS Fused - Sphere | Cylinder
* S3DIS Fused - Sphere | Cylinder
3dmatch от Andy Zeng et al. : 3dmatch: изучение местных геометрических дескрипторов из реконструкций RGB-D
Iralab Clackmark от Simone Fontana et al. : Стандарт для алгоритмов регистрации точечных облаков, который состоит из данных из:
Китти одометрия с исправленными позами (благодаря @humanpose1) от A. geiger et al . Готовы ли мы к автономному вождению? Citti Vision Benchmark Suite
В настоящее время мы поддерживаем двигатель Minkowski> v0.5 и TorchSparse> = v1.4.0 в качестве бэкэндов для разреженных свертков. Эти пакеты должны быть установлены независимо от Torch Points3D, пожалуйста, следуйте инструкциям по установке и устранению неполадок в соответствующих репозиториях. На данный момент MinkowskiEngine см. Здесь (спасибо, Крис Чой) демонстрирует более быстрое обучение. Имейте в виду, что torchsparse все еще находится в бета -версии и не поддерживает только обучение процессоров.
После того, как вы настроите одну из этих двух разреженных структурных рамках, которые вы можете начать использовать, - это высокий уровень, чтобы определить магистраль UNET или просто кодировщик:
from torch_points3d . applications . sparseconv3d import SparseConv3d
model = SparseConv3d ( "unet" , input_nc = 3 , output_nc = 5 , num_layers = 4 , backend = "torchsparse" ) # minkowski by default Вы также можете собрать свои собственные сети, используя модули, представленные в torch_points3d/modules/SparseConv3d/nn . Например, если вы хотите использовать бэкэнд torchsparse вы можете сделать следующее:
import torch_points3d . modules . SparseConv3d as sp3d
sp3d . nn . set_backend ( "torchsparse" )
conv = sp3d . nn . Conv3d ( 10 , 10 )
bn = sp3d . nn . BatchNorm ( 10 ) Смешанная точность позволяет снизить память на графическом процессоре и немного более быстрое время обучения, выполняя редкую свертку, объединение и градиент в float16 . Смешанная точная обучение в настоящее время поддерживается для обучения CUDA в сети SparseConv3d с бэкэнд TorchSparse. Чтобы включить смешанную точность, убедитесь, что у вас есть последняя версия TorchSparse с pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git . Затем установите training.enable_mixed=True в файлах конфигурации обучения. Если все условия будут выполнены, когда вы начнете обучение, вы увидите запись журнала, в которой говорится:
[torch_points3d.models.base_model][INFO] - Model will use mixed precision
Однако, если вы попытаетесь использовать смешанную точную тренировку с неподдерживаемым бэкэдом, вы увидите:
[torch_points3d.models.base_model][WARNING] - Mixed precision is not supported on this model, using default precision...
PretrainedRegistry позволяет кому-либо добавлять свои собственные предварительно обученные модели и re-create их только 2 строки кода для finetunning или production целей.
[You] запустите обучение модели с активированным Wandb ( wandb.log=True )[TorchPoints3d] После завершения обучения TorchPoints3d загрузит вашу обученную модель в нашу пользовательскую контрольную точку в ваш WANDB.[You] В классе PretainedRegistry добавьте key-value pair в MODELS атрибутов. key следует описать вашу модель, наборы данных и обучение гиперпараметров (возможно, лучшая модель), value должно быть url ссылаясь на файл .pt на ваш Wandb. Пример: ключ: pointnet2_largemsg-s3dis-1 и значение URL: https://api.wandb.ai/files/loicland/benchmark-torch-points-3d-s3dis/1e1p0csk/pointnet2_largemsg.pt для файла pointnet2_largemsg.pt . Ключ дает личени pointnet2 largemsg trained on s3dis fold 1 .
[Anyone] , используя класс PretainedRegistry и предоставляя key , будут downloaded связанные веса модели, а предварительно обученная модель будет ready to use с ее преобразованием. [ In ]:
from torch_points3d . applications . pretrained_api import PretainedRegistry
model = PretainedRegistry . from_pretrained ( "pointnet2_largemsg-s3dis-1" )
print ( model . wandb )
print ( model . print_transforms ())
[ Out ]:
== == == == == == == == == == == == == == == == == == == == == == == == == = WANDB URLS == == == == == == == == == == == == == == == == == == == == == == == == == == ==
WEIGHT_URL : https : // api . wandb . ai / files / loicland / benchmark - torch - points - 3 d - s3dis / 1e1 p0csk / pointnet2_largemsg . pt
LOG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / logs
CHART_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk
OVERVIEW_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / overview
HYDRA_CONFIG_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / hydra - config . yaml
OVERRIDES_URL : https : // app . wandb . ai / loicland / benchmark - torch - points - 3 d - s3dis / runs / 1e1 p0csk / files / overrides . yaml
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
pre_transform = None
test_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
train_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
RandomNoise ( sigma = 0.001 , clip = 0.05 ),
RandomRotate (( - 180 , 180 ), axis = 2 ),
RandomScaleAnisotropic ([ 0.8 , 1.2 ]),
RandomAxesSymmetry ( x = True , y = False , z = False ),
DropFeature ( proba = 0.2 , feature = 'rgb' ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
val_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
inference_transform = Compose ([
FixedPoints ( 20000 , replace = True ),
XYZFeature ( axis = [ 'z' ]),
AddFeatsByKeys ( rgb = True , pos_z = True ),
Center (),
ScalePos ( scale = 0.5 ),
])
pre_collate_transform = Compose ([
PointCloudFusion (),
SaveOriginalPosId ,
GridSampling3D ( grid_size = 0.04 , quantize_coords = False , mode = mean ),
])Мы используем поэзию для управления нашими пакетами. Чтобы начать, клонировать эти репозитории и запустите следующую команду из корня репо.
poetry install --no-root
Это установит все необходимые зависимости в новой виртуальной среде.
Активировать окружающую среду
poetry shellВы можете проверить, что установка была успешной, работая
python -m unittest -v Для поддержки pycuda (необходимо только для регистрационных задач):
pip install pycudapoetry run python train.py task=segmentation models=segmentation/pointnet2 model_name=pointnet2_charlesssg data=segmentation/shapenet-fixedИ вы должны увидеть что -то подобное
Конфигурация для PointNet ++ является хорошим примером того, как определить модель и следующим:
# PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (https://arxiv.org/abs/1706.02413)
# Credit Charles R. Qi: https://github.com/charlesq34/pointnet2/blob/master/models/pointnet2_part_seg_msg_one_hot.py
pointnet2_onehot :
architecture : pointnet2.PointNet2_D
conv_type : " DENSE "
use_category : True
down_conv :
module_name : PointNetMSGDown
npoint : [1024, 256, 64, 16]
radii : [[0.05, 0.1], [0.1, 0.2], [0.2, 0.4], [0.4, 0.8]]
nsamples : [[16, 32], [16, 32], [16, 32], [16, 32]]
down_conv_nn :
[
[[FEAT, 16, 16, 32], [FEAT, 32, 32, 64]],
[[32 + 64, 64, 64, 128], [32 + 64, 64, 96, 128]],
[[128 + 128, 128, 196, 256], [128 + 128, 128, 196, 256]],
[[256 + 256, 256, 256, 512], [256 + 256, 256, 384, 512]],
]
up_conv :
module_name : DenseFPModule
up_conv_nn :
[
[512 + 512 + 256 + 256, 512, 512],
[512 + 128 + 128, 512, 512],
[512 + 64 + 32, 256, 256],
[256 + FEAT, 128, 128],
]
skip : True
mlp_cls :
nn : [128, 128]
dropout : 0.5 Мы предоставляем сценарий для запуска данной предварительно обученной модели на пользовательских данных, которые не могут быть аннотированы. Вы найдете пример этого для задачи сегментации деталей на Shapenet. Как и для остальной части кодовой базы, большая часть настройки происходит через файлы конфигурации, и предоставленный пример может быть расширен на другие наборы данных. Вы также можете легко создать свой собственный оттуда. Возвращаясь к задаче сегментации деталей, скажем, у вас есть папка, полная точечных облаков, которые, как вы знаете, являются самолетами, и у вас есть контрольная точка модели, обученной самолетам и, возможно, другими классами, просто отредактируйте Config.yaml и ShapeNet.yaml и запустите следующую команду:
python forward_scripts/forward.py Результат прямого прогона будет помещен в указанный output_folder , и вы можете использовать ноутбук, предоставленную для изучения результатов. Ниже приведен пример результата использования модели, подготовленной на Caps, только для поиска частей самолетов и шапок.
Наконец, для людей, заинтересованных в развертывании своих моделей в производственных средах, мы предоставляем DockerFile, а также сценарий сборки. Скажем, вы обучили сеть для семантической сегментации, которая дала вес <outputfolder/weights.pt> , следующая команда создаст для вас изображение Docker:
cd docker
./build.sh outputfolder/weights.pt Затем вы можете использовать его для запуска прямого прохода на облака All Point во input_path и генерировать результаты в output_path
docker run -v /test_data:/in -v /test_data/out:/out pointnet2_charlesssg:latest python3 forward_scripts/forward.py dataset=shapenet data.forward_category=Cap input_path= " /in " output_path= " /out " Параметр -v скрепляет локальный каталог с файловой системой контейнера. Например, в командной строке выше, /test_data/out будет установлен в местоположении /out . Как следствие, все файлы, записанные в /out будут доступны в папке /test_data/out на вашей машине.
Мы советуем использовать snakeviz и cProfile
Используйте Cprofile для профиля вашего кода
poetry run python -m cProfile -o {your_name}.prof train.py ... debugging.profiling=True
И визуализировать результаты, используя Snakeviz.
snakeviz {your_name}.prof
Также можно использовать torch.utils.bottleneck
python -m torch.utils.bottleneck /path/to/source/script.py [args]
Убедитесь, что по крайней мере Pytorch 1.8.0 установлен, и убедитесь, что cuda/bin и cuda/include находятся в вашем $PATH и $CPATH соответственно, например:
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
$ echo $PATH
>>> /usr/local/cuda/bin:...
$ echo $CPATH
>>> /usr/local/cuda/include:...
Когда мы обновляем версию Pytorch, которая используется, скомпилированные пакеты должны быть переустановлены, в противном случае вы столкнетесь с ошибкой, которая выглядит так:
... scatter_cpu.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN3c1012CUDATensorIdEv
Это может произойти для следующих библиотек:
Легкий способ исправить это - запустить следующую команду с активированной Virtual Env:
pip uninstall torch-scatter torch-sparse torch-cluster torch-points-kernels -y
rm -rf ~/.cache/pip
poetry install
Это может произойти при попытке запустить код на другом графическом процессоре, чем тот, который использовался для компиляции библиотеки torch-points-kernels . Установите torch-points-kernels , очистите кэш и переустановите после установки переменной среды TORCH_CUDA_ARCH_LIST . Например, для составления с помощью Tesla T4 (Turing 7.5) и запуска кода на Tesla V100 (Volta 7.0) Использование:
export TORCH_CUDA_ARCH_LIST="7.0;7.5"
Посмотрите на эту полезную диаграмму для большей совместимости архитектуры.
Повышение OSError: [WinError 6] The handle is invalid / wandb: ERROR W&B process failed to launch Wandb в настоящее время разбивается в Windows (см. Этот вопрос), обходной путь - это использование аргумента командной строки wandb.log=false
Мы предоставляем Pyvista и панель на основе ноутбуков, которая позволяет визуально исследовать ваши прошлые эксперименты. При использовании Jupyter Lab вам придется установить расширение:
jupyter labextension install @pyviz/jupyterlab_pyviz
Запустите ноутбук, и вы должны увидеть начало приборной панели, которая выглядит как следующее:
Взносы приветствуются! Единственное, что спрашивает, что вы придерживаетесь стиля и что добавляете тесты, добавляя больше функций!
Для стиля вы можете использовать крючки с предварительной коммитацией, чтобы помочь вам:
pre-commit install
Для вас будет запускаться последовательность чеков, и вам, возможно, придется снова добавить фиксированные файлы в спрятанные файлы.
Когда дело доходит до DocStrings, мы используем Docstrings в стиле Numpy для тех, кто использует код Visual Studio, существует большое расширение, которое может помочь с этим. Установите его и установите формат на Numpy, и вам будет хорошо идти!
Последнее, если вы хотите, чтобы с нами поболтали, не стесняйтесь присоединиться к нашему Slack, просто отправьте нам электронное письмо, и мы добавим вас.
Если вы найдете нашу работу полезной, не стесняйтесь цитировать ее:
@inproceedings{
tp3d,
title={Torch-Points3D: A Modular Multi-Task Frameworkfor Reproducible Deep Learning on 3D Point Clouds},
author={Chaton, Thomas and Chaulet Nicolas and Horache, Sofiane and Landrieu, Loic},
booktitle={2020 International Conference on 3D Vision (3DV)},
year={2020},
organization={IEEE},
url = {url{https://github.com/nicolas-chaulet/torch-points3d}}
}
И, пожалуйста, также включите цитату в модели или наборы данных, которые вы использовали в своих экспериментах!


