คู่มือ NL2SQL
จากที่เก็บนี้คุณสามารถดูความก้าวหน้าล่าสุดใน NL2SQL คู่มือเล่มนี้สอดคล้องกับรายงานการสำรวจของเรา: การสำรวจ NL2SQL กับแบบจำลองภาษาขนาดใหญ่: เราอยู่ที่ไหนและเราจะไปที่ไหน นอกจากนี้เรายังมีสไลด์การสอนเพื่อสรุปประเด็นสำคัญของการสำรวจนี้ จากแนวโน้มในการพัฒนาแบบจำลองภาษาเราได้สร้างไดอะแกรมแม่น้ำของวิธี NL2SQL เพื่อติดตามวิวัฒนาการของสนาม NL2SQL
หากคุณเป็นสามเณรไม่ต้องกังวล - เราได้เตรียมคำแนะนำที่เป็นประโยชน์สำหรับคุณครอบคลุมวัสดุพื้นฐานที่หลากหลายที่นี่ เราสรุปแอปพลิเคชันที่เกี่ยวข้อง NL2SQL

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}- NL2SQL บทนำ
การแปลแบบสอบถามภาษาธรรมชาติของผู้ใช้ (NL) เป็นแบบสอบถาม SQL สามารถลดอุปสรรคในการเข้าถึงฐานข้อมูลเชิงสัมพันธ์และสนับสนุนแอพพลิเคชั่นเชิงพาณิชย์ที่หลากหลาย ประสิทธิภาพของ NL2SQL ได้รับการปรับปรุงอย่างมากด้วยการเกิดขึ้นของแบบจำลองภาษา (LMS) ในบริบทนี้มันเป็นสิ่งสำคัญในการประเมินตำแหน่งปัจจุบันของเรากำหนดโซลูชัน NL2SQL ที่ควรนำมาใช้สำหรับสถานการณ์เฉพาะโดยผู้ปฏิบัติงานและระบุหัวข้อการวิจัยที่นักวิจัยควรสำรวจต่อไป
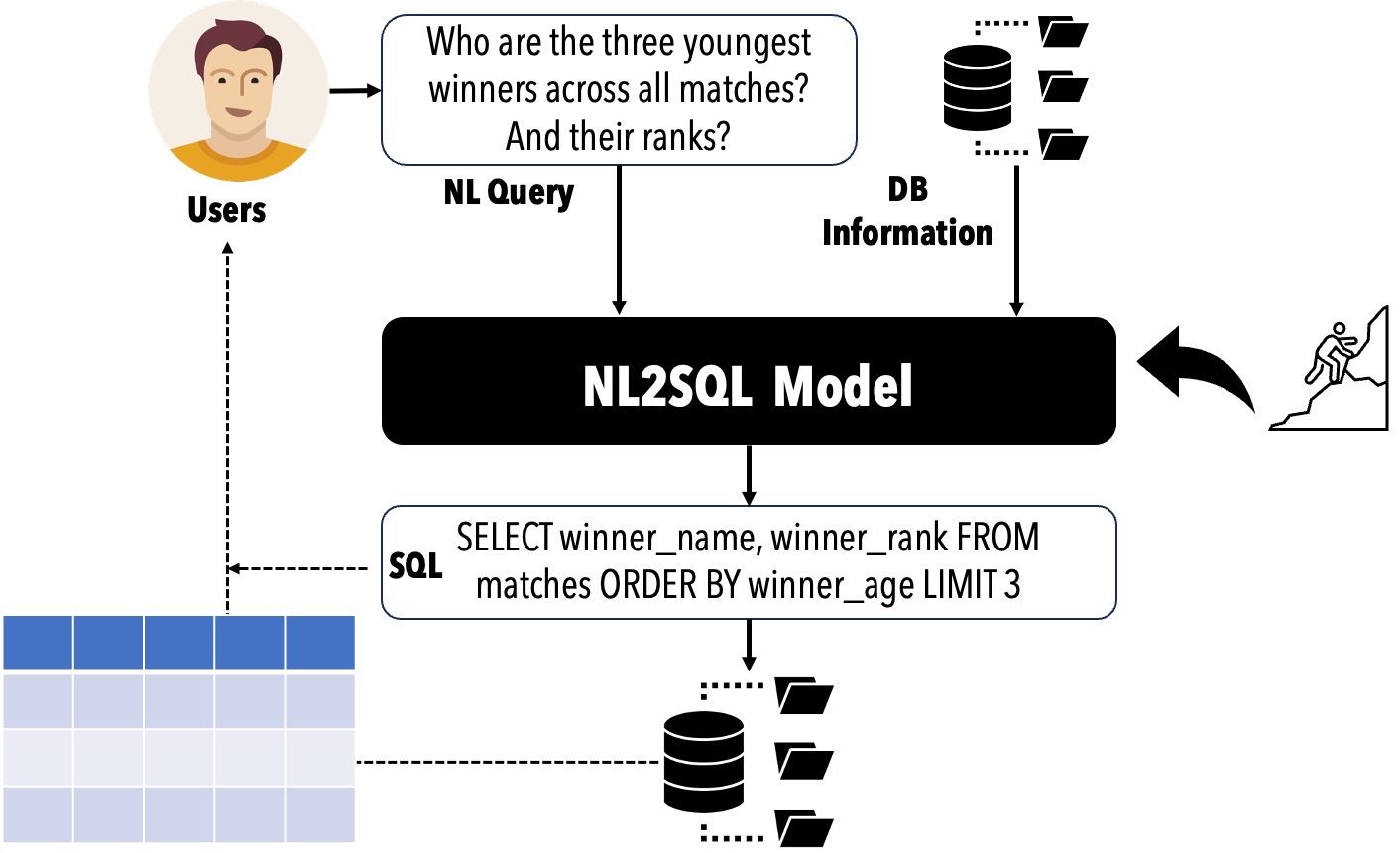
- วงจรชีวิต NL2SQL

แบบจำลอง: เทคนิคการแปล NL2SQL ที่จัดการไม่เพียง แต่ความคลุมเครือของ NL และการระบุภายใต้การระบุ แต่ยังแมป NL อย่างถูกต้องด้วยสคีมาฐานข้อมูลและอินสแตนซ์;
ข้อมูล: จากการรวบรวมข้อมูลการฝึกอบรมการสังเคราะห์ข้อมูลเนื่องจากความขาดแคลนข้อมูลการฝึกอบรมไปจนถึงมาตรฐาน NL2SQL;
การประเมินผล: การประเมินวิธี NL2SQL จากหลายมุมโดยใช้ตัวชี้วัดที่แตกต่างกันและความละเอียด
การวิเคราะห์ข้อผิดพลาด: การวิเคราะห์ข้อผิดพลาด NL2SQL เพื่อค้นหาสาเหตุที่แท้จริงและชี้นำโมเดล NL2SQL เพื่อพัฒนา
- เราอยู่ที่ไหน
เราจัดหมวดหมู่ความท้าทายของ NL2SQL เป็นห้าระดับแต่ละระดับที่อยู่ตามอุปสรรคเฉพาะ สามระดับแรกครอบคลุมความท้าทายที่ได้รับหรือกำลังได้รับการแก้ไขในขณะนี้สะท้อนให้เห็นถึงการพัฒนาที่ก้าวหน้าของ NL2SQL ระดับที่สี่แสดงถึงความท้าทายที่เราตั้งเป้าหมายที่จะจัดการในเวที LLMS ในขณะที่ระดับที่ห้าแสดงวิสัยทัศน์ของเราสำหรับระบบ NL2SQL ในอีกห้าปีข้างหน้า
เราอธิบายวิวัฒนาการของโซลูชัน NL2SQL จากมุมมองของแบบจำลองภาษาโดยแบ่งออกเป็นสี่ขั้นตอน สำหรับแต่ละขั้นตอนของ NL2SQL เราวิเคราะห์การเปลี่ยนแปลงของผู้ใช้เป้าหมายและขอบเขตที่ความท้าทายได้รับการแก้ไข

- วิธี NL2SQL ที่ใช้โมดูล
เราสรุปโมดูลสำคัญของโซลูชัน NL2SQL โดยใช้แบบจำลองภาษา
- การประมวลผลล่วงหน้า ทำหน้าที่เป็นการปรับปรุงอินพุตของโมเดลในกระบวนการแยกวิเคราะห์ NL2SQL คุณสามารถรับรายละเอียดเพิ่มเติมได้จากบทนี้: การประมวลผลล่วงหน้า
- วิธีการแปล NL2SQL เป็นแกนหลักของโซลูชัน NL2SQL ซึ่งรับผิดชอบในการแปลงการสืบค้นภาษาธรรมชาติอินพุตเป็นแบบสอบถาม SQL คุณสามารถรับรายละเอียดเพิ่มเติมได้จากบทนี้: วิธีการแปล NL2SQL
- การโพสต์การประมวลผล เป็นขั้นตอนสำคัญในการปรับแต่งการสืบค้น SQL ที่สร้างขึ้นเพื่อให้แน่ใจว่าพวกเขาปฏิบัติตามความคาดหวังของผู้ใช้อย่างแม่นยำยิ่งขึ้น คุณสามารถรับรายละเอียดเพิ่มเติมจากบทนี้: โพสต์การประมวลผล

NL2SQL การสำรวจและการสอน
- การสำรวจ NL2SQL ด้วยแบบจำลองภาษาขนาดใหญ่: เราอยู่ที่ไหนและเราจะไปที่ไหน?
- อินเทอร์เฟซฐานข้อมูลรุ่นต่อไป: การสำรวจของข้อความถึง SQL ที่ใช้ LLM
- รูปแบบภาษาขนาดใหญ่ปรับปรุงการสร้างข้อความถึง SQL: การสำรวจ
- จากภาษาธรรมชาติถึง SQL: ตรวจสอบระบบข้อความถึง SQL ที่ใช้ LLM
- การสำรวจเกี่ยวกับการใช้แบบจำลองภาษาขนาดใหญ่สำหรับงานข้อความถึง SQL
- อินเทอร์เฟซภาษาธรรมชาติสำหรับการสืบค้นข้อมูลแบบตาราง: การสำรวจ: การสำรวจ
- อินเทอร์เฟซภาษาธรรมชาติสำหรับฐานข้อมูลที่มีการเรียนรู้อย่างลึกซึ้ง
- การสำรวจวิธีการเรียนรู้อย่างลึกซึ้งสำหรับข้อความถึง SQL
- ความก้าวหน้าล่าสุดในข้อความถึง SQL: การสำรวจสิ่งที่เรามีและสิ่งที่เราคาดหวัง
- การดำน้ำลึกลงไปในแนวทางการเรียนรู้อย่างลึกซึ้งสำหรับระบบข้อความถึง SQL
- สถานะของศิลปะและความท้าทายที่เปิดกว้างในการเชื่อมต่อภาษาธรรมชาติกับข้อมูล
- ภาษาธรรมชาติถึง SQL: วันนี้เราอยู่ที่ไหน?
- รายการกระดาษ NL2SQL
- รุ่งอรุณของภาษาธรรมชาติถึง SQL: เราพร้อมหรือยัง?
- Text-to-SQL ได้รับพลังจากแบบจำลองภาษาขนาดใหญ่: การประเมินเกณฑ์มาตรฐาน
- แบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนและแบบจำลองภาษาขนาดใหญ่สำหรับการสร้าง NL2SQL แบบศูนย์
- การสร้างคำอธิบายสั้น ๆ ของฐานข้อมูล schemata สำหรับการแจ้งเตือนต้นทุนแบบจำลองภาษาขนาดใหญ่
- ScienceBenchmark: เกณฑ์มาตรฐานในโลกแห่งความเป็นจริงที่ซับซ้อนสำหรับการประเมินภาษาธรรมชาติกับระบบ SQL
- รหัส: ไปสู่การสร้างแบบจำลองภาษาโอเพนซอร์ซสำหรับข้อความถึง SQL
- FINSQL: กรอบข้อความ LLMS-agnostic-agnostic LLMS สำหรับการวิเคราะห์ทางการเงิน
- สีม่วง: การสร้างแบบจำลองภาษาขนาดใหญ่เป็นนักเขียน SQL ที่ดีขึ้น
- Metasql: กรอบการสร้างอันดับสำหรับภาษาธรรมชาติเพื่อการแปล SQL
- อาร์เชอร์: ชุดข้อมูลข้อความที่มีป้ายกำกับของมนุษย์กับ SQL ที่มีเลขคณิตการใช้เหตุผลและการใช้เหตุผลเชิงสมมุติฐาน
- การสังเคราะห์ข้อมูลข้อความถึง SQL จาก LLM ที่อ่อนแอและแข็งแกร่ง
- การทำความเข้าใจผลกระทบของเสียงรบกวนในข้อความถึง SQL: การตรวจสอบมาตรฐานของเบนช์นก
- ฉันต้องการความช่วยเหลือ! การประเมินความสามารถของ LLM ในการขอการสนับสนุนจากผู้ใช้: กรณีศึกษาเกี่ยวกับการสร้างข้อความถึง SQL
- PTD-SQL: การแบ่งพาร์ติชันและการเจาะเป้าหมายด้วย LLMS ในข้อความถึง SQL
- การปรับปรุงการเรียกคืนข้อความต่อ SQL ด้วยการจัดอันดับ AST และการตัดแต่งสคีมา
- ข้อความเป็นศูนย์กลางเป็นศูนย์กลางกับแบบจำลองภาษาขนาดใหญ่
- แมงมุม 2.0: การประเมินรูปแบบภาษาในเวิร์กโฟลว์ข้อความแบบข้อความสู่โลกแห่งความเป็นจริง
- โครงสร้างชี้นำแบบจำลองภาษาขนาดใหญ่สำหรับการสร้าง SQL
- RSL-SQL: การเชื่อมโยงสคีมาที่แข็งแกร่งในการสร้างข้อความกับ SQL
- TrustSQL: การเปรียบเทียบความน่าเชื่อถือของข้อความกับ SQL ด้วยการให้คะแนนตามโทษ
- SQL-GEN: การเชื่อมช่องว่างภาษาถิ่นสำหรับข้อความถึง SQL ผ่านข้อมูลสังเคราะห์และการรวมแบบจำลอง
- การต่อสายดินภาษาธรรมชาติเพื่อการแปล SQL ด้วยการอธิบายตนเองตามข้อมูล
- Chase-SQL: การใช้เหตุผลหลายเส้นทางและการเลือกผู้สมัครที่ได้รับการปรับให้เหมาะสมที่สุดในข้อความถึง SQL
- เพื่อเพิ่มประสิทธิภาพการสร้าง SQL ผ่านการกำหนดเส้นทาง LLM
- XIYAN-SQL: เฟรมเวิร์ก Ensemble Multi-Generator สำหรับข้อความถึง SQL
- E-SQL: การเชื่อมโยงสคีมาโดยตรงผ่านการเพิ่มคำถามในข้อความถึง SQL
- DB-GPT: การเพิ่มขีดความสามารถในการโต้ตอบฐานข้อมูลกับโมเดลภาษาขนาดใหญ่ส่วนตัว
- การตายของสคีมาเชื่อมโยง? Text-to-SQL ในยุคของแบบจำลองภาษาที่มีเหตุผล
- DBCOPILOT: ปรับขนาดภาษาธรรมชาติแบบสอบถามไปยังฐานข้อมูลขนาดใหญ่
- หมากรุก: การควบคุมบริบทสำหรับการสังเคราะห์ SQL ที่มีประสิทธิภาพ
- PET-SQL: การปรับแต่งสองรอบที่เพิ่มขึ้นอย่างรวดเร็วของข้อความถึง SQL ด้วยความสอดคล้องข้าม
- COE-SQL: การเรียนรู้ในบริบทสำหรับหลายครั้งข้อความถึง SQL ด้วยห่วงโซ่ของรุ่น
- Ambrosia: เกณฑ์มาตรฐานสำหรับการแยกวิเคราะห์คำถามที่คลุมเครือลงในแบบสอบถามฐานข้อมูล
- การแปลแบบ text-sql แบบ sql ไม่กี่ภาพโดยใช้โครงสร้างและการเรียนรู้ที่รวดเร็ว
- CATSQL: สู่ภาษาธรรมชาติในโลกแห่งความเป็นจริงสำหรับแอปพลิเคชัน SQL
- DIN-SQL: ย่อยสลายการเรียนรู้ในบริบทของข้อความถึง SQL ด้วยการแก้ไขตนเอง
- ความกำกวมของข้อมูลย้อนกลับไป: เอกสารปรับปรุงข้อความเป็นข้อความของ GPT เป็นอย่างไร
- ACT-SQL: การเรียนรู้ในบริบทสำหรับข้อความถึง SQL ด้วยโซ่ที่สร้างโดยอัตโนมัติ
- การสาธิตการคัดเลือกสำหรับข้อความข้ามโดเมนเป็น SQL
- ResdSQL: การเชื่อมโยงสคีมาและการแยกการแยกโครงโครงร่างสำหรับข้อความถึง SQL
- graphix-T5: การผสมหม้อแปลงที่ผ่านการฝึกอบรมมาก่อนกับเลเยอร์ที่รับรู้กราฟสำหรับการแยกวิเคราะห์แบบข้อความถึง SQL
- การปรับปรุงการวางนัยทั่วไปในการแยกวิเคราะห์ความหมายแบบข้อความตามรูปแบบภาษากับ SQL: สองเทคนิคตามขอบเขตความหมายแบบง่าย ๆ
- G 3 R: เฟรมเวิร์กสร้างกราฟ-นำทางและเรียดสำหรับการสร้างข้อความที่ซับซ้อนและข้ามโดเมน
- ความสำคัญของการสังเคราะห์ข้อมูลคุณภาพสูงสำหรับการแยกวิเคราะห์แบบข้อความถึง SQL
- รู้ว่าสิ่งที่ฉันไม่รู้: จัดการคำถามที่คลุมเครือและไม่รู้จักสำหรับข้อความถึง SQL
- C3: zero-shot text-to-sql พร้อม chatgpt
- MAC-SQL: กรอบการทำงานร่วมกันแบบหลายตัวแทนสำหรับข้อความถึง SQL
- SQLFORMER: การสร้างกราฟการสืบค้นแบบเร่งความเร็วอัตโนมัติลึกสำหรับการแปลแบบข้อความเป็น SQL
เกณฑ์มาตรฐาน NL2SQL
เราสร้างเส้นเวลาของการพัฒนามาตรฐานและทำเครื่องหมายเหตุการณ์สำคัญที่เกี่ยวข้อง คุณสามารถรับรายละเอียดเพิ่มเติมได้จากบทนี้: เกณฑ์มาตรฐาน

เราจะไปไหน?
- Sovle Open NL2SQL ปัญหา
- พัฒนาวิธี NL2SQL ที่ประหยัดต้นทุน
- ทำให้โซลูชัน NL2SQL น่าเชื่อถือ
- NL2SQL พร้อมแบบสอบถาม NL ที่ไม่ชัดเจนและไม่ระบุรายละเอียด
- การสังเคราะห์ข้อมูลการฝึกอบรมแบบปรับตัว
แคตตาล็อกสำหรับการสำรวจของเรา
คุณสามารถรับข้อมูลเพิ่มเติมจากส่วนย่อยของเรา เราแนะนำเอกสารตัวแทนเกี่ยวกับแนวคิดที่เกี่ยวข้อง:
- การประมวลผลล่วงหน้า
- วิธีการแปล NL2SQL
- การโพสต์
- เกณฑ์มาตรฐาน
- การประเมิน
- การวิเคราะห์ข้อผิดพลาด
- คู่มือปฏิบัติสำหรับมือใหม่
วิธีรับข้อมูล:
- เรารวบรวมคุณสมบัติมาตรฐาน NL2SQL และดาวน์โหลดลิงก์สำหรับคุณ คุณสามารถรับรายละเอียดเพิ่มเติมได้จากบทนี้: เกณฑ์มาตรฐาน
- รหัสการวิเคราะห์สำหรับมาตรฐานมีอยู่ในไดเรกทอรี
src/dataset_analysis รายงานการวิเคราะห์มาตรฐานสามารถพบได้ใน report/ ไดเรกทอรี
วิธีสร้างโมเดล NL2SQL ที่ใช้ LLM:
ลิงค์ที่เก็บ LITGPT
พื้นที่เก็บข้อมูลนี้ให้การเข้าถึงโมเดลภาษาขนาดใหญ่ที่มีประสิทธิภาพสูงกว่า 20 รุ่น (LLMs) พร้อมคู่มือที่ครอบคลุมสำหรับการเตรียมการปรับแต่งและปรับใช้ในระดับ มันถูกออกแบบมาให้เป็นมิตรกับการเริ่มต้นด้วยการใช้งานจากการตั้งค่าสแตรชและไม่มี abstractions ที่ซับซ้อน
Llama-Factory Repository Link Unified การปรับจูนอย่างมีประสิทธิภาพของ 100+ LLMS การรวมโมเดลต่าง ๆ เข้ากับทรัพยากรการฝึกอบรมที่ปรับขนาดได้อัลกอริทึมขั้นสูงเทคนิคการปฏิบัติและเครื่องมือตรวจสอบการทดลองที่ครอบคลุมการตั้งค่านี้ช่วยให้การอนุมานที่มีประสิทธิภาพและเร็วขึ้นผ่าน API และ UIs ที่เหมาะสม
การปรับแต่งและการเรียนรู้ในบริบทสำหรับลิงค์ที่เก็บเบนช์เบนด์เบนด์เบนด์เบนด์
การสอนสำหรับทั้งการปรับแต่งและการเรียนรู้ในบริบทนั้นจัดทำโดยเกณฑ์มาตรฐาน Bird-SQL
? วิธีการประเมินแบบจำลองของคุณ:
เรารวบรวมตัวชี้วัดการประเมิน NL2SQL สำหรับคุณ คุณสามารถรับรายละเอียดเพิ่มเติมได้จากบทนี้: การประเมินผล
ลิงค์ที่เก็บ NLSQL360
NL2SQL360 เป็นการทดสอบสำหรับการประเมินผลการแก้ปัญหา NL2SQL อย่างละเอียด Testbed ของเรารวมเกณฑ์มาตรฐาน NL2SQL ที่มีอยู่ซึ่งเป็นที่เก็บของโมเดล NL2SQL และตัวชี้วัดการประเมินผลต่าง ๆ ซึ่งมีวัตถุประสงค์เพื่อให้แพลตฟอร์มที่ใช้งานง่ายและเป็นมิตรกับผู้ใช้เพื่อเปิดใช้งานการประเมินประสิทธิภาพทั้งมาตรฐานและแบบกำหนดเอง
ลิงค์ที่เก็บทดสอบ Suite-SQL-EVAL
repo นี้มีตัวชี้วัดการประเมินชุดทดสอบสำหรับงาน 11 ข้อความต่อ SQL ตอนนี้มันเป็นตัวชี้วัดอย่างเป็นทางการของแมงมุม, Sparc และ Cosql และตอนนี้ยังมีให้บริการสำหรับนักวิชาการ, ATIS, ให้คำปรึกษา, ภูมิศาสตร์, IMDB, ร้านอาหาร, นักวิชาการและ Yelp (สร้างงานที่น่าทึ่งโดย Catherine และ Jonathan)
ลิงค์ที่เก็บของ Bird-SQL-official
ตอนนี้เป็นเครื่องมืออย่างเป็นทางการของ Bird-SQL มันเป็นเครื่องมือแรกที่เสนอ VES และให้ชุดทดสอบอย่างเป็นทางการ
️แผนงานและการตัดสินใจไหล
คุณสามารถได้รับแรงบันดาลใจจากแผนงานและการตัดสินใจ

แอปพลิเคชันที่เกี่ยวข้อง NL2SQL:
- ChAT2DB: เครื่องมือฐานข้อมูล AI-Driven และไคลเอนต์ SQL, ไคลเอนต์ GUI ที่ร้อนแรงที่สุด, สนับสนุน MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, Clickhouse และอื่น ๆ
- DB-GPT: AI Native Data App Development Framework พร้อม AWEL (Agentic Workflow Expression Language) และตัวแทน
- Postgres.new: In-browser postgres sandgres ด้วยความช่วยเหลือ AI


