Manual NL2SQL
Desde este repositorio, puede ver los últimos avances en NL2SQL. Este manual corresponde a nuestro documento de encuesta: una encuesta de NL2SQL con modelos de idiomas grandes: ¿A dónde estamos y a dónde vamos? También proporcionamos diapositivas tutoriales para resumir los puntos clave de esta encuesta. Basado en las tendencias en el desarrollo de modelos de lenguaje, hemos creado un diagrama fluvial de métodos NL2SQL para rastrear la evolución del campo NL2SQL.
Si es un novato, no se preocupe, hemos preparado una guía práctica para usted, cubriendo una amplia gama de materiales fundamentales aquí. Resumimos aplicaciones relacionadas con NL2SQL.

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}? Introducción NL2SQL
La traducción de las consultas de lenguaje natural de los usuarios (NL) en consultas SQL puede reducir significativamente las barreras para acceder a bases de datos relacionales y admitir varias aplicaciones comerciales. El rendimiento de NL2SQL se ha mejorado enormemente con la aparición de modelos de lenguaje (LMS). En este contexto, es crucial evaluar nuestra posición actual, determinar las soluciones NL2SQL que deberían adoptar escenarios específicos por profesionales e identificar los temas de investigación que los investigadores deberían explorar a continuación.
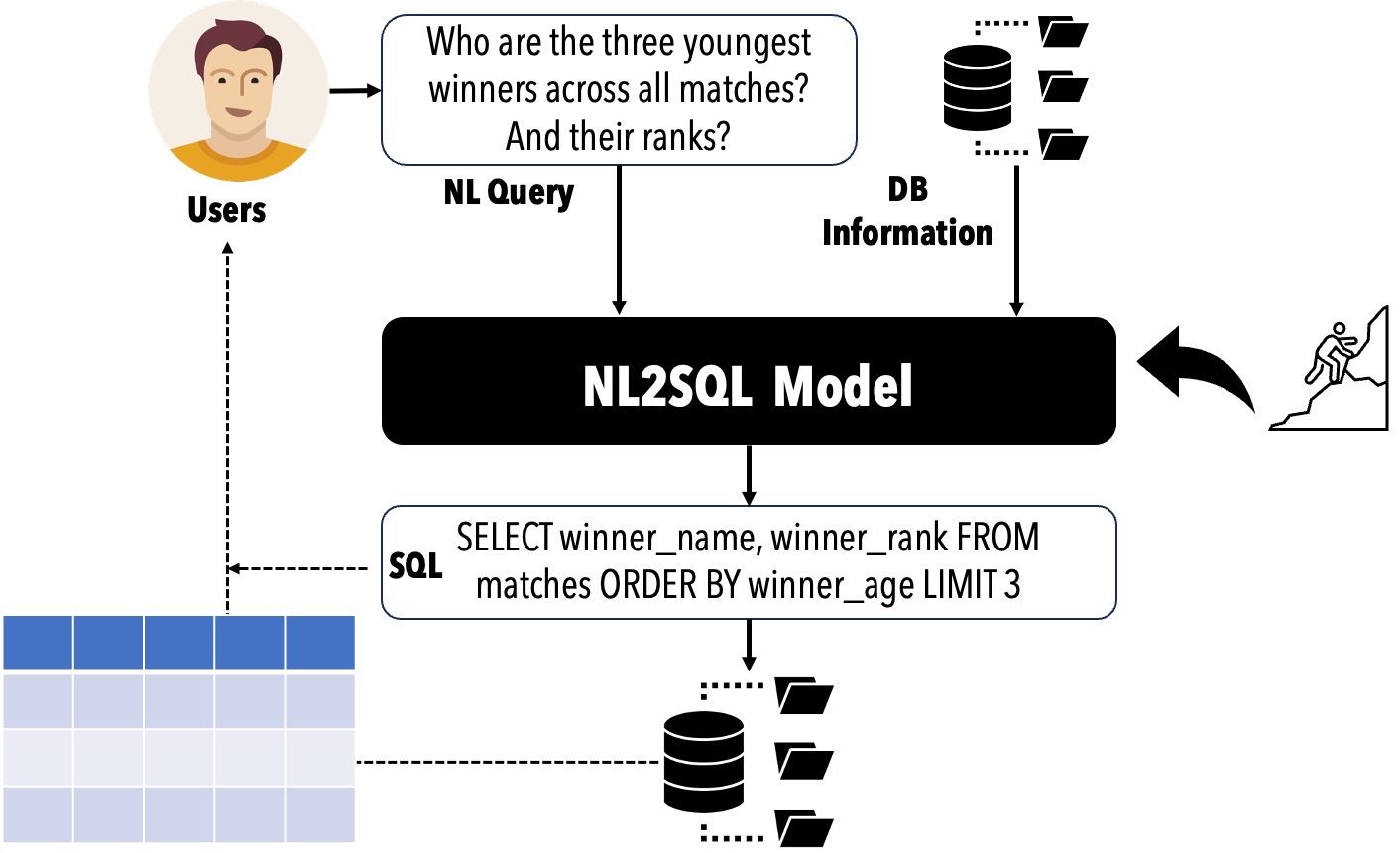
? Ciclo de vida nl2sql

Modelo: Técnicas de traducción de NL2SQL que abordan no solo la ambigüedad de NL y la bajo especificación, sino también mapear correctamente NL con el esquema de la base de datos e instancias;
Datos: desde la recopilación de datos de capacitación, síntesis de datos debido a la escasez de datos de capacitación, hasta los puntos de referencia NL2SQL;
Evaluación: evaluación de métodos NL2SQL desde múltiples ángulos utilizando diferentes métricas y granularidades;
Análisis de errores: analizar los errores de NL2SQL para encontrar la causa raíz y la guía de los modelos NL2SQL para evolucionar.
? ¿Dónde estamos?
Clasificamos los desafíos de NL2SQL en cinco niveles, cada uno abordando obstáculos específicos. Los primeros tres niveles cubren desafíos que se han abordado o se están abordando actualmente, lo que refleja el desarrollo progresivo de NL2SQL. El cuarto nivel representa los desafíos que nuestro objetivo es enfrentar en la etapa de LLMS, mientras que el quinto nivel describe nuestra visión para el sistema NL2SQL en los próximos cinco años.
Describimos la evolución de las soluciones NL2SQL desde la perspectiva de los modelos de idiomas, clasificándola en cuatro etapas. Para cada etapa de NL2SQL, analizamos los cambios en los usuarios objetivo y la medida en que se abordan los desafíos.

? Métodos NL2SQL basados en módulos
Resumimos los módulos clave de las soluciones NL2SQL utilizando el modelo de idioma.
- El preprocesamiento sirve como una mejora de las entradas del modelo en el proceso de análisis NL2SQL. Puede obtener más detalles de este capítulo: Preprocesamiento
- Los métodos de traducción de NL2SQL constituyen el núcleo de la solución NL2SQL, responsable de convertir las consultas de lenguaje natural de entrada en consultas SQL. Puede obtener más detalles de este capítulo: Métodos de traducción de NL2SQL
- El procesamiento posterior es un paso crucial para refinar las consultas SQL generadas, asegurando que cumplan con las expectativas de los usuarios con mayor precisión. Puede obtener más detalles de este capítulo: postprocesamiento

Encuesta y tutorial de NL2SQL
- Una encuesta de NL2SQL con modelos de idiomas grandes: ¿Dónde estamos y a dónde vamos?
- Interfaces de datos de próxima generación: una encuesta de texto a SQL basado en LLM.
- Modelo de lenguaje grande mejoró la generación de texto a SQL: una encuesta.
- Desde el lenguaje natural hasta SQL: revisión de los sistemas de texto a SQL basados en LLM.
- Una encuesta sobre el empleo de modelos de idiomas grandes para tareas de texto a SQL.
- Interfaces del lenguaje natural para consultas y visualización de datos tabulares: una encuesta.
- Interfaces del lenguaje natural para bases de datos con aprendizaje profundo.
- Una encuesta sobre enfoques de aprendizaje profundo para texto a SQL.
- Avances recientes en texto a SQL: una encuesta de lo que tenemos y lo que esperamos.
- Una inmersión profunda en los enfoques de aprendizaje profundo para los sistemas de texto a SQL.
- Estado del arte y desafíos abiertos en interfaces de lenguaje natural a los datos.
- Lenguaje natural a SQL: ¿Dónde estamos hoy?
? Lista de documentos NL2SQL
- El amanecer del lenguaje natural a SQL: ¿Estamos completamente listos?
- Texto a SQL capacitado por modelos de idiomas grandes: una evaluación de referencia.
- Interinece los modelos de lenguaje previamente capacitados y los modelos de lenguaje grandes para la generación NL2SQL de disparo cero.
- Generación de descripciones sucintas de esquemas de bases de datos para la solicitud rentable de modelos de idiomas grandes.
- ScienceBenchmark: un complejo punto de referencia del mundo real para evaluar el lenguaje natural a los sistemas SQL.
- Códigos: hacia la construcción de modelos de lenguaje de código abierto para texto a SQL.
- FINSQL: marco de texto a SQL basado en Model-Agnóstico LLMS para el análisis financiero.
- Púrpura: hacer de un modelo de lenguaje grande un mejor escritor SQL.
- MetaSQL: un marco generador de rango para el lenguaje natural a la traducción de SQL.
- Archer: un conjunto de datos de texto a SQL marcado por humanos con razonamiento aritmético, común e hipotético.
- Sintetizar datos de texto a SQL de LLM débiles y fuertes.
- Comprender los efectos del ruido en el texto a SQL: un examen del punto de referencia de bancos de pájaros.
- ¡Necesito ayuda! Evaluación de la capacidad de LLM para solicitar el soporte de los usuarios: un estudio de caso sobre la generación de texto a SQL.
- PTD-SQL: partición y perforación dirigida con LLM en texto a SQL.
- Mejora del texto a SQL de recuperación con AST con la clasificación y la poda de esquema.
- Texto a SQL centrado en datos con modelos de lenguaje grandes.
- Spider 2.0: Evaluación de modelos de lenguaje en flujos de trabajo de texto a SQL de empresas del mundo real.
- Estructura Modelo de lenguaje grande guiado para la generación SQL.
- RSL-SQL: esquema robusto que se vincula en la generación de texto a SQL.
- TrustSQL: Confiabilidad de texto a SQL de comparación con la puntuación basada en penalización.
- SQL-Gen: unir la brecha del dialecto para texto a SQL a través de datos sintéticos y fusión del modelo.
- Lenguaje natural de base a la traducción de SQL con autoexplicaciones basadas en datos.
- Chase-SQL: Razonamiento de múltiples rutas y preferencias de selección de candidatos optimizados en texto a SQL.
- Hacia la optimización de la generación SQL a través del enrutamiento LLM.
- Xiyan-SQL: un marco de conjunto multigenerador para Text-to-SQL.
- E-SQL: enlace de esquema directo a través del enriquecimiento de preguntas en texto a SQL.
- DB-GPT: Empoderar interacciones de base de datos con modelos privados de idiomas grandes.
- ¿La muerte de la vinculación del esquema? Texto a SQL en la era de los modelos de idiomas bien razonados.
- DBCopilot: escala de consulta de lenguaje natural a bases de datos masivas.
- Ajedrez: arnés contextual para una síntesis eficiente de SQL.
- PET-SQL: un refinamiento de dos rondas mejorado con aviso de texto a SQL con consistencia cruzada.
- COE-SQL: aprendizaje en contexto para texto de múltiples vueltas a SQL con la cadena de ediciones.
- Ambrosia: un punto de referencia para analizar preguntas ambiguas en consultas de bases de datos.
- Peque traducción de texto a SQL de pocos disparos utilizando la estructura y el aprendizaje indicado en el contenido.
- CATSQL: Hacia el lenguaje natural del mundo real a las aplicaciones SQL.
- DIN-SQL: aprendizaje en contexto descompuesto de texto a SQL con autocorrección.
- La ambigüedad de los datos ataca: cómo la documentación mejora el texto de GPT a SQL.
- ACT-SQL: aprendizaje en contexto para texto a SQL con cadena de pensamiento generada automáticamente.
- Demostraciones selectivas para texto de dominio cruzado a SQL.
- RESDSQL: enlace de esquema de desacoplamiento y análisis de esqueleto para texto a SQL.
- Graphix-T5: Mezcla de transformadores previamente capacitados con capas conscientes de gráficos para análisis de texto a SQL.
- Mejora de la generalización en el análisis semántico de texto a SQL basado en modelos de lenguaje: dos técnicas simples de límites semánticos basados en límites.
- G 3 R: Un marco generado y reranque guiado por gráficos para la generación de texto complejo y de dominio cruzado a SQL.
- Importancia de sintetizar datos de alta calidad para el análisis de texto a SQL.
- Sepa lo que no sé: manejo de preguntas ambiguas y desconocidas para texto a SQL.
- C3: Texto de tiro cero a SQL con chatgpt
- Mac-SQL: un marco colaborativo de múltiples agentes para texto a SQL.
- SQLFORMER: Generación de gráficos de consulta auto-regresiva profunda para la traducción de texto a SQL.
Punto de referencia NL2SQL
Creamos una línea de tiempo del desarrollo del punto de referencia y marcamos hitos relevantes. Puede obtener más detalles de este capítulo: Benchmark

¿A dónde vamos?
- Sovle Open NL2SQL Problema
- Desarrollar métodos NL2SQL rentables
- Hacer soluciones nl2sql confiables
- NL2SQL con consultas NL ambiguas y no especificadas
- Síntesis de datos de entrenamiento adaptativo
Catálogo para nuestra encuesta
Puede obtener más información de nuestra subsección. Introducimos documentos representativos sobre conceptos relacionados:
- Preprocesamiento
- Métodos de traducción de NL2SQL
- Postprocesamiento
- Punto de referencia
- Evaluación
- Análisis de errores
? Guía práctica para novatos
Cómo obtener datos:
- Recopilamos características de referencia NL2SQL y enlaces de descarga para usted. Puede obtener más detalles de este capítulo: Benchmark
- El código de análisis para puntos de referencia está disponible en el directorio
src/dataset_analysis . Los informes de análisis de referencia se pueden encontrar en el report/ directorio.
Cómo construir un modelo NL2SQL basado en LLM:
Enlace de repositorio de litgpt
Este repositorio ofrece acceso a más de 20 modelos de lenguaje grande (LLM) de alto rendimiento con guías integrales para pretrenesa, ajuste fino e implementación a escala. Está diseñado para ser amigable para principiantes con implementaciones desde el rasguño y sin abstracciones complejas.
LLAMA-FATORY LINK UNIFICADO UNIFICADO ANTINGUNO FINAL DE MÁS 100+ LLMS. Integrando varios modelos con recursos de capacitación escalables, algoritmos avanzados, trucos prácticos y herramientas integrales de monitoreo de experimentos, esta configuración permite una inferencia eficiente y más rápida a través de API y UI optimizadas.
Aprendizaje de ajuste y contexto para el enlace de repositorio de referencia Bird-SQL
El tutorial para el aprendizaje de ajuste fino y en contexto es proporcionado por el punto de referencia Bird-SQL.
? Cómo evaluar su modelo:
Recopilamos métricas de evaluación NL2SQL para usted. Puede obtener más detalles de este capítulo: Evaluación
Enlace de repositorio NLSQL360
NL2SQL360 es una cama de prueba para la evaluación de grano fino de las soluciones NL2SQL. Nuestro Testbed integra los puntos de referencia NL2SQL existentes, un repositorio de modelos NL2SQL y varias métricas de evaluación, que tiene como objetivo proporcionar una plataforma intuitiva y fácil de usar para habilitar evaluaciones de rendimiento estándar y personalizadas.
Enlace de repositorio de prueba-suite-sql-eval
Este repositorio contiene una métrica de evaluación de suite de prueba para 11 tareas de texto a SQL. Ahora es la métrica oficial de Spider, SPARC y COSQL, y ahora también está disponible para académicos, ATIS, asesoramiento, geografía, IMDB, restaurantes, académicos y Yelp (construyendo sobre el increíble trabajo de Catherine y Jonathan).
Enlace de repositorio oficial de Bird-SQL
Ahora es la herramienta oficial de Bird-SQL. Es la primera herramienta para proponer VES y dar una suite de prueba oficial.
? ️ Hoja de ruta y flujo de decisión
Puede inspirarte en la hoja de ruta y el flujo de decisión.

Aplicaciones relacionadas con NL2SQL:
- CHAT2DB: herramienta de base de datos dirigida por AI y cliente SQL, el cliente GUI más popular, admitiendo MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, Clickhouse y más.
- DB-GPT: Marco de desarrollo de aplicaciones de datos nativos de IA con AWEL (lenguaje de expresión de flujo de trabajo de agente) y agentes.
- Postgres.new: Postgres Sandbox en el navegador con asistencia de IA.


