NL2SQL Handbuch
Aus diesem Repository können Sie die neuesten Fortschritte in NL2SQL anzeigen. Dieses Handbuch entspricht unserem Umfragepapier: Eine Umfrage unter NL2SQL mit großartigen Modellen: Wo sind wir und wohin gehen wir?. Wir bieten auch Tutorial -Folien an, um die wichtigsten Punkte dieser Umfrage zusammenzufassen. Basierend auf den Trends in der Entwicklung von Sprachmodellen haben wir ein Flussdiagramm von NL2SQL -Methoden erstellt, um die Entwicklung des NL2SQL -Feldes zu verfolgen.
Wenn Sie ein Anfänger sind, machen Sie sich keine Sorgen - wir haben einen praktischen Leitfaden für Sie vorbereitet, der hier eine breite Palette von grundlegenden Materialien abdeckt. Wir haben nl2SQL -verwandte Anwendungen zusammengefasst.

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}? NL2SQL EINLEITUNG
Das Umsetzen von Natürlichen Sprachabfragen der Benutzer in SQL -Abfragen kann die Hindernisse für den Zugriff auf relationale Datenbanken erheblich reduzieren und verschiedene kommerzielle Anwendungen unterstützen. Die Leistung von NL2SQL wurde durch die Entstehung von Sprachmodellen (LMS) erheblich verbessert. In diesem Zusammenhang ist es entscheidend, unsere aktuelle Position zu bewerten, die NL2SQL -Lösungen zu bestimmen, die für bestimmte Szenarien von Praktikern übernommen werden sollten, und die Forschungsthemen zu identifizieren, die Forscher als nächstes untersuchen sollten.
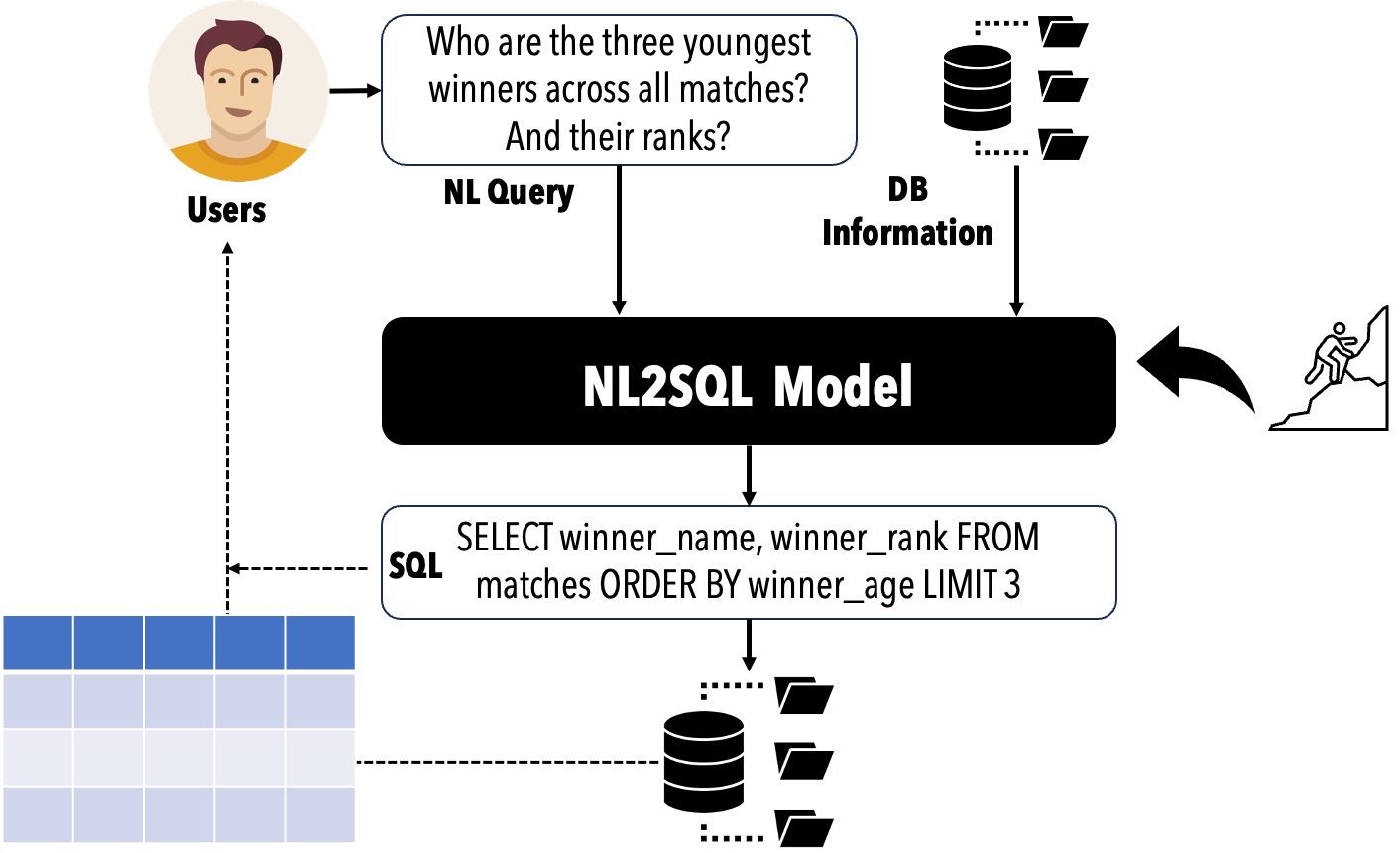
? NL2SQL -Lebenszyklus

Modell: NL2SQL-Übersetzungstechniken, die nicht nur NL-Mehrdeutigkeit und Unterabteilung angehen, sondern auch NL mit Datenbankschema und Instanzen ordnungsgemäß zuordnen;
Daten: Aus der Erfassung von Trainingsdaten, Datensynthese aufgrund der Trainingsdatenknappheit bis hin zu NL2SQL -Benchmarks;
Bewertung: Bewertung von NL2SQL -Methoden aus mehreren Blickwinkeln mit unterschiedlichen Metriken und Granularitäten;
Fehleranalyse: Analyse von NL2SQL -Fehlern, um die Root -Ursache zu finden und NL2SQL -Modelle zur Entwicklung zu führen.
? Wo sind wir?
Wir kategorisieren die Herausforderungen von NL2SQL in fünf Ebenen, die jeweils bestimmte Hürden befassen. Die ersten drei Ebenen decken Herausforderungen ab, die derzeit angegangen wurden oder werden, was die fortschreitende Entwicklung von NL2SQL widerspiegelt. Die vierte Ebene stellt die Herausforderungen dar, die wir in der LLMS -Stufe bewältigen möchten, während die fünfte Ebene unsere Vision für das NL2SQL -System in den nächsten fünf Jahren umreißt.
Wir beschreiben die Entwicklung von NL2SQL -Lösungen aus der Perspektive von Sprachmodellen und kategorisieren sie in vier Stufen. Für jede Stufe von NL2SQL analysieren wir die Änderungen der Zielbenutzer und das Ausmaß, in dem Herausforderungen angegangen werden.

? Modulbasierte NL2SQL-Methoden
Wir fassen die Schlüsselmodule von NL2SQL -Lösungen mithilfe des Sprachmodells zusammen.
- Die Vorverarbeitung dient als Verbesserung der Eingaben des Modells im NL2SQL-Parsing-Prozess. Aus diesem Kapitel können Sie weitere Details erhalten: Vorverarbeitung
- NL2SQL -Translationsmethoden bilden den Kern der NL2SQL -Lösung, die für die Konvertierung der natürlichen Sprachabfragen in Eingabe in SQL -Abfragen verantwortlich sind. Aus diesem Kapitel können Sie weitere Details erhalten: NL2SQL -Übersetzungsmethoden
- Nachbearbeitung ist ein entscheidender Schritt, um die generierten SQL-Abfragen zu verfeinern und sicherzustellen, dass sie die Erwartungen der Benutzer genauer erfüllen. Aus diesem Kapitel können Sie weitere Details erhalten: Nachbearbeitung

NL2SQL Survey & Tutorial
- Eine Umfrage unter NL2SQL mit großen Sprachmodellen: Wo sind wir und wohin gehen wir?
- Datenbank-Schnittstellen der nächsten Generation: Eine Übersicht über LLM-basierte Text-zu-SQL.
- Großsprachiges Modell verbesserte Text-zu-SQL-Generation: Eine Umfrage.
- Von der natürlichen Sprache zu SQL: Überprüfung von LLM-basierten Text-zu-SQL-Systemen.
- Eine Umfrage zum Einsatz großer Sprachmodelle für Text-zu-SQL-Aufgaben.
- Natürliche Sprachschnittstellen für tabellarische Datenabfragen und Visualisierung: Eine Umfrage.
- Natürliche Sprachschnittstellen für Datenbanken mit tiefem Lernen.
- Eine Umfrage zu Deep-Lern-Ansätzen für Text-to-SQL.
- Jüngste Fortschritte in Text-to-SQL: Eine Übersicht darüber, was wir haben und was wir erwarten.
- Ein tiefes Eintauchen in tiefe Lernansätze für Text-zu-SQL-Systeme.
- Stand der Technik und offene Herausforderungen in natürlichen Sprachschnittstellen zu Daten.
- Natürliche Sprache zu SQL: Wo sind wir heute?
? NL2SQL -Papierliste
- Die Morgendämmerung der natürlichen Sprache zu SQL: Sind wir voll bereit?
- Text-to-SQL-Ermordung durch große Sprachmodelle: Eine Benchmark-Bewertung.
- Verschachtelung vorgebildeter Sprachmodelle und große Sprachmodelle für Null-Shot-NL2SQL-Erzeugung.
- Erzeugen Sie prägnante Beschreibungen von Datenbankschemata für kostengünstige Aufforderung großer Sprachmodelle.
- ScienceBenchmark: Ein komplexer realer Benchmark für die Bewertung der natürlichen Sprache an SQL-Systemen.
- Codes: Um Open-Source-Sprachmodelle für Text-to-SQL zu erstellen.
- FINSQL: Modell-agnostische LLM-basierte Text-zu-SQL-Framework für die Finanzanalyse.
- Lila: Machen Sie ein großes Sprachmodell zu einem besseren SQL -Schriftsteller.
- Metasql: Ein generierter Rang-Rahmen für die natürliche Sprache zu SQL-Übersetzung.
- Archer: Ein menschlich markiertes Text-zu-SQL-Datensatz mit arithmetischen, gewohnten und hypothetischen Denken.
- Synthese von Text-to-SQL-Daten aus schwachen und starken LLMs.
- Verständnis der Auswirkungen von Rauschen in Text-to-SQL: Eine Untersuchung des Benchmarks von Vogelbenchien.
- Ich brauche Hilfe! Bewertung der Fähigkeit von LLM, die Unterstützung der Benutzer zu bitten: eine Fallstudie zur Erzeugung von Text-zu-SQL-Erzeugung.
- PTD-SQL: Partitionierung und gezielte Bohrung mit LLMs in Text-to-SQL.
- Verbesserung des agrieval-ausgerüsteten Text-zu-SQL mit AST-basiertem Ranking und Schema-Beschneiden.
- Datenorientiertes Text-zu-SQL mit großen Sprachmodellen.
- Spider 2.0: Bewertung von Sprachmodellen auf praktischen Workflows mit Unternehmens-Unternehmens-SQL.
- Strukturgeführtes Großsprachmodell für die SQL -Generation.
- RSL-SQL: Robustes Schema, das in der Text-zu-SQL-Generation verlinkt.
- TrustSQL: Benchmarking Text-to-SQL-Zuverlässigkeit mit Strafe.
- SQL-Gen: Überbrückung der Dialektlücke für Text zu SQL über synthetische Daten und Modellverführung.
- Erde natürliche Sprache zur SQL-Übersetzung mit datenbasierten Selbsteinklärungen.
- Chase-SQL: Multi-Pfad-Argumentation und Präferenzoptimierte Kandidatenauswahl in Text-zu-SQL.
- Zur Optimierung der SQL -Erzeugung über LLM -Routing.
- Xiyan-SQL: Ein Multi-Generator-Ensemble-Framework für Text-to-SQL.
- E-SQL: Direktes Schema, das über Fragenanreicherung in Text-to-SQL verlinkt wird.
- DB-GPT: Stärkung der Datenbankinteraktionen mit privaten großsprachigen Modellen.
- Der Tod des Schemasverbindens? Text-to-SQL im Zeitalter gut begründeter Sprachmodelle.
- Dbcopilot: Skalierung der natürlichen Sprachabfrage zu massiven Datenbanken.
- Schach: Kontextbezogene Nutzung für die effiziente SQL -Synthese.
- PET-SQL: Eine schnell verbesserte Zwei-Runden-Verfeinerung von Text-to-SQL mit Kreuzkonsistenz.
- COE-SQL: In-Context-Lernen für Multiturn-Text-zu-SQL-Ketten mit der Kette.
- Ambrosia: Ein Maßstab für die Parsen mehrdeutiger Fragen in Datenbankabfragen.
- Wenige Schuss-Text-zu-SQL-Übersetzung unter Verwendung von Struktur und Inhaltsaufforderung.
- CATSQL: In Richtung der natürlichen Sprache der realen Welt zu SQL -Anwendungen.
- Din-SQL: Zersetztes Lernen von Text-to-SQL mit Selbstkorrektur.
- Datenvermehrung Streiks zurück: Wie die Dokumentation den Text-zu-SQL-GPT verbessert.
- ACT-SQL: In-Context-Lernen für Text-zu-SQL mit automatisch generierter Kette des Gedankens.
- Selektive Demonstrationen für Cross-Domain-Text-zu-SQL.
- RESDSQL: Entkopplungsschema Verknüpfung und Skelett an Text-to-SQL-Analyse.
- Graphix-T5: Mischen Sie vorgebildete Transformatoren mit graphbewussten Ebenen für die Text-zu-SQL-Parsing.
- Verbesserung der Verallgemeinerung in sprachmodellbasierten Text-zu-SQL-Semantik-Parsen: zwei einfache semantische Grenztechniken.
- G 3 R: Ein graph-geführter Generat- und Lernrahmen für komplexe und Cross-Domain-Text-zu-SQL-Erzeugung.
- Bedeutung der Synthese hochwertiger Daten für die Analyse von Text zu SQL.
- Wissen Sie, was ich nicht weiß: Verwandte mehrdeutige und unbekannte Fragen für Text-zu-SQL.
- C3: Null-Shot-Text-zu-SQL mit ChatGPT
- MAC-SQL: Ein kollaboratives Multi-Agent-Framework für Text-to-SQL.
- SQLFORMER: Deep Auto-tergressive Abfraggrafikgenerierung für Text-zu-SQL-Übersetzung.
NL2SQL Benchmark
Wir erstellen eine Zeitleiste der Entwicklung des Benchmarks und markieren relevante Meilensteine. Aus diesem Kapitel können Sie weitere Details erhalten: Benchmark

Wohin gehen wir?
- Sovle Open NL2SQL -Problem
- Entwickeln Sie kostengünstige NL2SQL-Methoden
- Machen Sie NL2SQL -Lösungen vertrauenswürdig
- NL2SQL mit mehrdeutigen und nicht näher bezeichneten NL -Abfragen
- Adaptive Trainingsdatensynthese
Katalog für unsere Umfrage
Sie können weitere Informationen aus unserem Unterabschnitt erhalten. Wir stellen repräsentative Arbeiten zu verwandten Konzepten vor:
- Vorverarbeitung
- NL2SQL -Übersetzungsmethoden
- Nachbearbeitung
- Benchmark
- Auswertung
- Fehleranalyse
? Praktischer Leitfaden für Anfänger
So erhalten Sie Daten:
- Wir sammeln NL2SQL -Benchmark -Funktionen und laden Links für Sie herunter. Aus diesem Kapitel können Sie weitere Details erhalten: Benchmark
- Der Analysecode für Benchmarks ist im Verzeichnis
src/dataset_analysis verfügbar. Benchmark -Analyseberichte finden Sie im report/ Verzeichnis.
So erstellen Sie ein LLM-basierter NL2SQL-Modell:
LITGPT -Repository -Link
Dieses Repository bietet Zugriff auf über 20 Hochleistungs-Großsprachenmodelle (LLMs) mit umfassenden Leitfäden für Vorab-, Feinabstimmung und Bereitstellung im Maßstab. Es ist so konzipiert, dass es anfängerfreundlich mit From-Scratch-Implementierungen und ohne komplexe Abstraktionen ist.
LAMA-FACTORY-Repository Link Unified Effiziente Feinabstimmung von 100+ LLMs. Durch die Integration verschiedener Modelle in skalierbare Trainingsressourcen, fortschrittliche Algorithmen, praktische Tricks und umfassende Experiment -Überwachungstools ermöglicht dieses Setup eine effiziente und schnellere Folgerung durch optimierte APIs und UIs.
Feinabstimmung und Kontext-Lernen für Bird-SQL-Benchmark-Repository-Link
Ein Tutorial für Feinabstimmungen und Kontextlernen erfolgt vom Bird-SQL-Benchmark.
? Wie bewerten Sie Ihr Modell:
Wir sammeln NL2SQL -Bewertungsmetriken für Sie. Aus diesem Kapitel können Sie weitere Details erhalten: Bewertung
NLSQL360 Repository Link
NL2SQL360 ist ein Testbett für die feinkörnige Bewertung von NL2SQL-Lösungen. Unser Testbed integriert vorhandene NL2SQL-Benchmarks, ein Repository von NL2SQL-Modellen und verschiedene Bewertungsmetriken, die darauf abzielen, eine intuitive und benutzerfreundliche Plattform bereitzustellen, um sowohl Standard- als auch maßgeschneiderte Leistungsbewertungen zu ermöglichen.
Test-suite-SQL-Eval-Repository-Link
Dieses Repo enthält eine Testsuite-Bewertungsmetrik für 11 Text-zu-SQL-Aufgaben. Es ist jetzt die offizielle Metrik von Spider, SPARC und COSQL und ist jetzt auch für Akademiker, ATIs, Beratung, Geographie, IMDB, Restaurants, Gelehrte und Yelp erhältlich (bauen auf der erstaunlichen Arbeit von Catherine und Jonathan).
Bird-SQL-Official Repository Link
Es ist jetzt das offizielle Werkzeug von Bird-SQL. Es ist das erste Instrument, das Ves vorschlägt und eine offizielle Testsuite angibt.
Roadmap und Entscheidungsfluss
Sie können sich von der Roadmap und dem Entscheidungsfluss inspirieren lassen.

NL2SQL -verwandte Anwendungen:
- CHAT2DB: AI-gesteuerter Datenbank-Tool und SQL-Client, der heißeste GUI-Client, unterstützt MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, Clickhouse und mehr.
- DB-GPT: KI native Daten-App-Entwicklungsframework mit Awel (Agenten Workflow Expression Language) und Agenten.
- Postgres.new: In-Browser Postgres Sandbox mit AI-Unterstützung.


