NL2SQLハンドブック
このリポジトリから、NL2SQLの最新の進歩を表示できます。このハンドブックは、私たちの調査論文に対応しています:大規模な言語モデルを使用したNL2SQLの調査:私たちはどこにいて、どこに行くのですか?また、この調査の重要なポイントを要約するためのチュートリアルスライドも提供しています。言語モデルの開発の傾向に基づいて、NL2SQLフィールドの進化を追跡するために、NL2SQLメソッドの川図を作成しました。
あなたが初心者であろうと、心配しないでください。私たちはあなたのための実用的なガイドを準備し、ここで幅広い基本的な資料をカバーしています。 NL2SQL関連アプリケーションを要約しました。

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}? NL2SQLはじめに
ユーザーの自然言語クエリ(NL)をSQLクエリに変換すると、リレーショナルデータベースへのアクセスに対する障壁を大幅に減らし、さまざまな商用アプリケーションをサポートできます。 NL2SQLのパフォーマンスは、言語モデル(LMS)の出現により大幅に改善されました。これに関連して、現在の位置を評価し、実務家が特定のシナリオに採用する必要があるNL2SQLソリューションを決定し、研究者が次に探求すべき研究トピックを特定することが重要です。
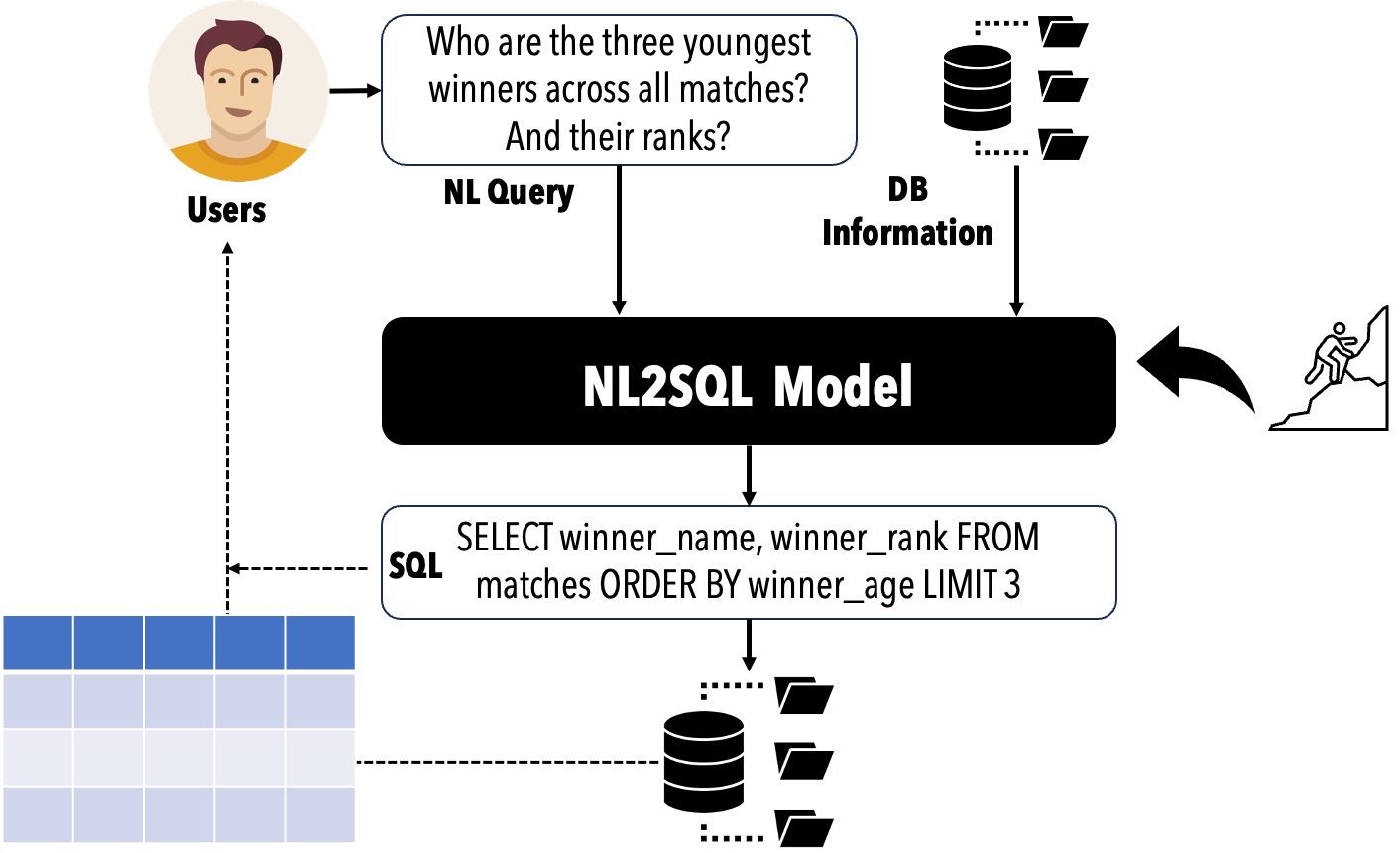
? NL2SQLライフサイクル

モデル:NLのあいまいさと不足の仕様だけでなく、NLをデータベーススキーマとインスタンスに適切にマッピングするNL2SQL翻訳技術。
データ:トレーニングデータの収集から、トレーニングデータ不足によるデータ統合、NL2SQLベンチマークまで。
評価:異なるメトリックと粒度を使用して、複数の角度からNL2SQLメソッドを評価します。
エラー分析:NL2SQLエラーを分析して根本原因を見つけ、NL2SQLモデルを進化させるようガイドします。
?ここはどこ?
NL2SQLの課題を5つのレベルに分類し、それぞれが特定のハードルに対処します。最初の3つのレベルは、NL2SQLの進歩的な発達を反映して、現在対処されている、または現在取り組んでいる課題をカバーしています。 4番目のレベルは、LLMS段階で取り組むことを目的とした課題を表し、5番目のレベルは今後5年間でNL2SQLシステムのビジョンを概説しています。
言語モデルの観点からNL2SQLソリューションの進化について説明し、それを4つの段階に分類します。 NL2SQLの各段階について、ターゲットユーザーの変化と、課題に対処する程度を分析します。

?モジュールベースのNL2SQLメソッド
言語モデルを利用してNL2SQLソリューションの重要なモジュールを要約します。
- 前処理は、 NL2SQL解析プロセスにおけるモデルの入力の強化として機能します。この章から詳細を確認できます:前処理
- NL2SQL翻訳方法は、入力自然言語クエリをSQLクエリに変換するnl2SQLソリューションのコアを構成します。この章から詳細を確認できます:NL2SQL翻訳方法
- 後処理は、生成されたSQLクエリを改良し、ユーザーの期待をより正確に満たすための重要なステップです。この章から詳細を確認できます:後処理

NL2SQL調査&チュートリアル
- 大規模な言語モデルを使用したNL2SQLの調査:私たちはどこにいて、どこに行くのか
- 次世代データベースインターフェイス:LLMベースのテキストからSQLの調査。
- 大規模な言語モデル強化テキストからSQLの生成:調査。
- 自然言語からSQLへ:LLMベースのテキストからSQLシステムのレビュー。
- テキスト間タスクに大規模な言語モデルを採用することに関する調査。
- 表形式データのクエリと視覚化のための自然言語インターフェイス:調査。
- 深い学習を備えたデータベースの自然言語インターフェイス。
- テキストからSQLのディープラーニングアプローチに関する調査。
- テキストからSQLへの最近の進歩:私たちが持っているものと期待するものの調査。
- テキスト間システムのディープラーニングアプローチに深く掘り下げます。
- 自然言語インターフェイスにおける最先端の芸術とオープンな課題。
- SQLへの自然言語:今日はどこにいますか?
? NL2SQLペーパーリスト
- SQLへの自然言語の夜明け:私たちは完全に準備ができていますか?
- 大規模な言語モデルによって権限を与えられるテキストからSQL:ベンチマーク評価。
- ゼロショットNL2SQL生成のための事前に訓練された言語モデルと大規模な言語モデルをインターリーブします。
- 大規模な言語モデルの費用効率の高いプロンプトのためのデータベーススキーマの簡潔な説明を生成します。
- ScienceBenchmark:自然言語をSQLシステムに評価するための複雑な実世界のベンチマーク。
- コード:テキストからSQLのオープンソース言語モデルの構築に向けて。
- FINSQL:財務分析のためのモデルに依存しないLLMSベースのテキストからSQLフレームワーク。
- パープル:大規模な言語モデルをより優れたSQLライターにする。
- MetASQL:SQL翻訳への自然言語の生成ランクフレームワーク。
- Archer:算術、常識、仮説的な推論を備えた人間の標識テキストからSQLデータセット。
- 弱いLLMと強いLLMからのテキスト間データを合成します。
- テキストからSQLへの騒音の影響を理解する:鳥のベンチベンチマークの検査。
- 私は助けが必要です!ユーザーのサポートを要求するLLMの能力の評価:テキスト間生成に関するケーススタディ。
- PTD-SQL:テキストからSQLのLLMを使用したパーティション化およびターゲット掘削。
- ASTベースのランキングとスキーマプルーニングを使用して、検索されたテキストからSQLの改善。
- 大規模な言語モデルを使用したデータ中心のテキストからSQL。
- SPIDER 2.0:実際のエンタープライズテキストからSQLワークフローの言語モデルの評価。
- SQL生成の構造ガイド付き大規模な言語モデル。
- RSL-SQL:テキストとSQLの生成にリンクする堅牢なスキーマ。
- TrustSQL:ペナルティベースのスコアリングでテキストからSQLへの信頼性をベンチマークします。
- SQL-Gen:合成データとモデルのマージを介して、テキスト間の方言のギャップを埋める。
- データベースの自己概要を使用して、SQL翻訳に自然言語を接地します。
- Chase-SQL:マルチパスの推論と設定テキストからSQLの最適化された候補の選択。
- LLMルーティングを介してSQL生成の最適化に向けて。
- xiyan-sql:テキストからSQLのマルチジェネレーターアンサンブルフレームワーク。
- E-SQL:テキストからSQLへの質問濃縮を介してリンクする直接スキーマ。
- DB-GPT:プライベート大規模な言語モデルとのデータベースの相互作用の力を強化します。
- スキーマの死はリンクしていますか?十分に達成された言語モデルの時代のテキストからSQL。
- dbcopilot:大規模なデータベースへの自然言語クエリのスケーリング。
- チェス:効率的なSQL合成のためのコンテキストハーネス。
- PET-SQL:クロスコンシンティ性を備えたテキストからSQLへの迅速な2ラウンドの改良。
- COE-SQL:チェーンを使用したマルチターンテキストからSQLのコンテキスト学習。
- Ambrosia:データベースクエリにあいまいな質問を解析するためのベンチマーク。
- 構造とコンテンツの迅速な学習を使用した少数のテキストからSQLへの翻訳。
- CATSQL:Real World Natural Language to SQLアプリケーションに向けて。
- DIN-SQL:自己修正によるテキストからSQLへのテキストからSQLへの分解されたコンテキスト学習。
- データのあいまいさは逆になります:ドキュメントがGPTのテキストからSQLを改善する方法。
- ACT-SQL:自動化されたチェーンを使用したテキストからSQLのコンテキスト学習。
- クロスドメインテキストからSQLの選択的デモンストレーション。
- resdsql:テキストからSQLのためのリンクとスケルトンの解析スキーマのデカップリング。
- Graphix-T5:事前に訓練された変圧器と、テキストからSQLへの解析用のグラフアウェア層と混合します。
- 言語モデルベースのテキストからSQLのセマンティック解析の一般化の改善:2つの単純なセマンティック境界ベースの手法。
- G 3 R:複雑およびドメインのテキストからSQLの生成のためのグラフ誘導生成および再実行フレームワーク。
- テキストからSQLへの解析のための高品質のデータを合成することの重要性。
- 私が知らないことを知っています:テキストからSQLの曖昧で未知の質問の処理。
- C3:ChatGPTを使用したゼロショットテキストからSQL
- MAC-SQL:テキストからSQLのマルチエージェントコラボレーションフレームワーク。
- SQLFormer:テキストからSQLへの翻訳のためのディープオートエレクゼーションクエリグラフ生成。
NL2SQLベンチマーク
ベンチマークの開発のタイムラインを作成し、関連するマイルストーンをマークします。この章:ベンチマークから詳細を確認できます

どこに行くの?
- SOVLE OPEN NL2SQL問題
- 費用対効果の高いNL2SQLメソッドを開発します
- NL2SQLソリューションを信頼できるものにします
- あいまいで不特定のNLクエリを備えたNL2SQL
- 適応トレーニングデータの合成
調査用のカタログ
サブセクションから詳細情報を入手できます。関連する概念に関する代表的な論文を紹介します。
- 前処理
- NL2SQL翻訳方法
- 後処理
- ベンチマーク
- 評価
- エラー分析
?初心者のための実践ガイド
データの取得方法:
- NL2SQLベンチマーク機能を収集し、リンクをダウンロードします。この章:ベンチマークから詳細を確認できます
- ベンチマークの分析コードは
src/dataset_analysisディレクトリで入手できます。ベンチマーク分析レポートはreport/ディレクトリに記載されています。
LLMベースのNL2SQLモデルを構築する方法:
litgptリポジトリリンク
このリポジトリは、20を超える高性能の大手言語モデル(LLM)へのアクセスを提供します。それは、SCRATCHからの実装と複雑な抽象化がないことで初心者に優しいように設計されています。
llama-factoryリポジトリリンクは、100以上のLLMの効率的な微調整を統合します。さまざまなモデルをスケーラブルなトレーニングリソース、高度なアルゴリズム、実用的なトリック、および包括的な実験監視ツールと統合すると、このセットアップにより、最適化されたAPIとUIを通じて効率的かつ高速な推論が可能になります。
Bird-SQLベンチマークリポジトリリンクの微調整およびコンテキスト学習
微調整とコンテキスト内の学習の両方のチュートリアルは、Bird-SQLベンチマークによって提供されます。
?モデルを評価する方法:
NL2SQL評価メトリックを収集します。この章で詳細を確認できます:評価
NLSQL360リポジトリリンク
NL2SQL360は、NL2SQLソリューションの細粒評価のテストベッドです。テストベッドは、既存のNL2SQLベンチマーク、NL2SQLモデルのリポジトリ、およびさまざまな評価メトリックを統合します。これは、標準的でカスタマイズされたパフォーマンス評価の両方を可能にするための直感的でユーザーフレンドリーなプラットフォームを提供することを目的としています。
Test-Suite-SQL-Evalリポジトリリンク
このレポは、11のテキストからSQLタスクのテストスイート評価メトリックが含まれています。現在、Spider、SPARC、およびCOSQLの公式メトリックであり、学術、ATIS、アドバイス、地理、IMDB、レストラン、学者、およびYelp(キャサリンとジョナサンの驚くべき作品に基づいて構築)にも利用できます。
Bird-SQL-official Repositoryリンク
現在、Bird-SQLの公式ツールです。これは、VESを提案し、公式のテストスイートを提供する最初のツールです。
?§ロードマップと決定フロー
ロードマップと意思決定の流れからインスピレーションを得ることができます。

NL2SQL関連アプリケーション:
- Chat2DB:AI駆動型のデータベースツールとSQLクライアントであるSQLクライアントは、MySQL、Oracle、PostgreSQL、DB2、SQL Server、DB2、SQLite、H2、Clickhouseなどをサポートしています。
- DB-GPT:AIネイティブデータアプリ開発フレームワーク(エージェントワークフロー表現言語)およびエージェント。
- postgres.new:Browser In-Browser Postgres Sandbox with AI Assistance。


