Manuel NL2SQL
À partir de ce référentiel, vous pouvez afficher les dernières avancées de NL2SQL. Ce manuel correspond à notre document d'enquête: une enquête de NL2SQL avec des modèles de langues importants: où sommes-nous et où allons-nous ?. Nous fournissons également des diapositives de tutoriel pour résumer les points clés de cette enquête. Sur la base des tendances du développement des modèles de langage, nous avons créé un diagramme fluvial de méthodes NL2SQL pour tracer l'évolution du champ NL2SQL.
Si vous êtes novice, ne vous inquiétez pas - nous avons préparé un guide pratique pour vous, couvrant ici un large éventail de documents fondamentaux. Nous avons résumé les applications liées à NL2SQL.

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}? Introduction NL2SQL
La traduction des requêtes en langage naturel des utilisateurs (NL) en requêtes SQL peut réduire considérablement les obstacles à l'accès aux bases de données relationnelles et prendre en charge diverses applications commerciales. Les performances de NL2SQL ont été considérablement améliorées avec l'émergence de modèles de langage (LMS). Dans ce contexte, il est crucial d'évaluer notre position actuelle, de déterminer les solutions NL2SQL qui devraient être adoptées pour des scénarios spécifiques par les praticiens et d'identifier les sujets de recherche que les chercheurs devraient explorer ensuite.
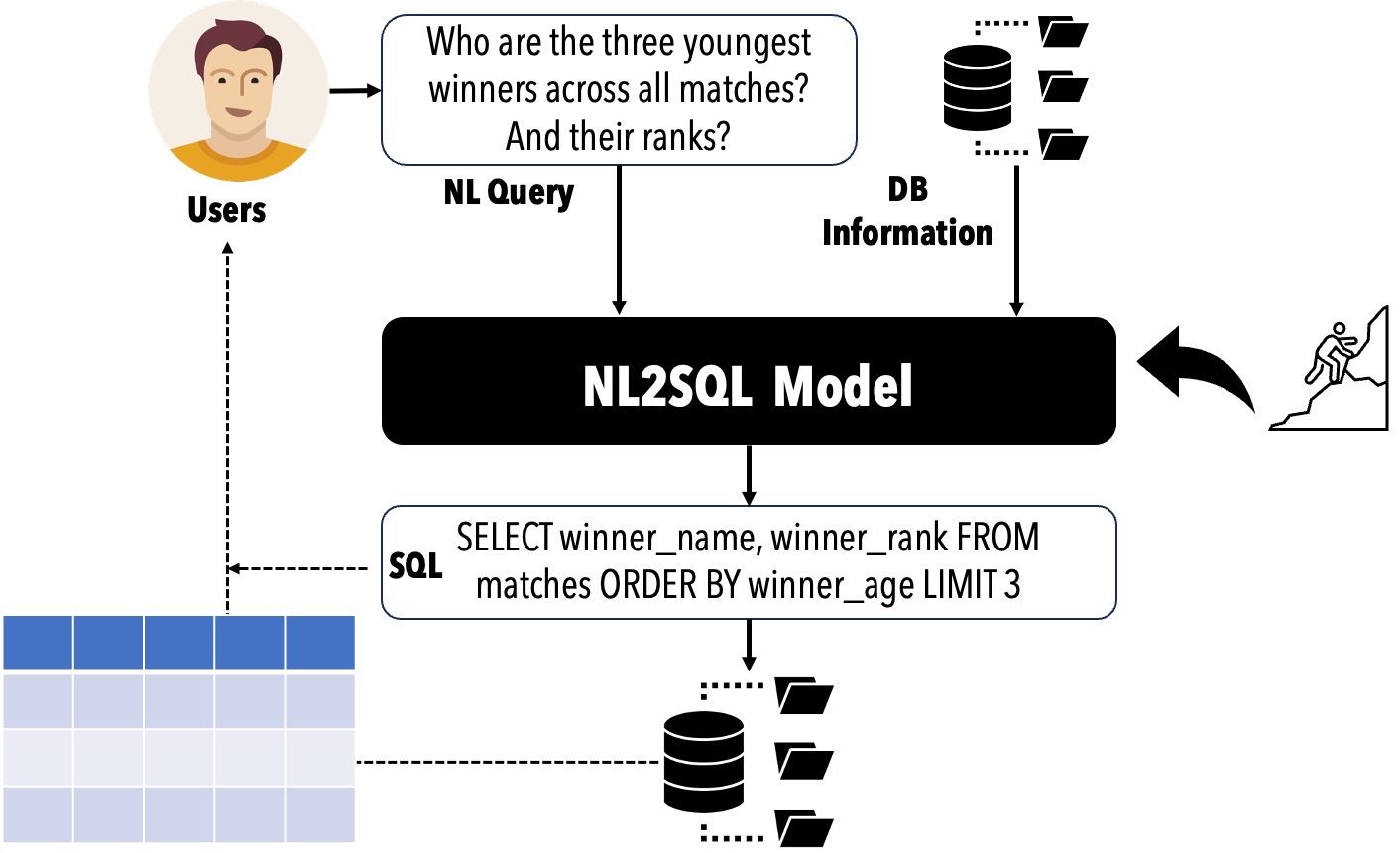
? Cycle de vie NL2SQL

Modèle: Techniques de traduction NL2SQL qui s'attaquent non seulement à l'ambiguïté NL et à la sous-spécification, mais aussi à cartographier correctement NL avec le schéma de base de données et les instances;
Données: De la collecte des données de formation, la synthèse des données due à la rareté des données de formation, aux repères NL2SQL;
Évaluation: évaluation des méthodes NL2SQL sous plusieurs angles en utilisant différentes mesures et granulations;
Analyse des erreurs: analyser les erreurs NL2SQL pour trouver la cause profonde et guider les modèles NL2SQL pour évoluer.
? Où sommes-nous?
Nous classons les défis de NL2SQL en cinq niveaux, chacun abordant des obstacles spécifiques. Les trois premiers niveaux couvrent les défis qui ont été ou sont actuellement à relever, reflétant le développement progressif de NL2SQL. Le quatrième niveau représente les défis que nous visons à relever dans l'étape LLMS, tandis que le cinquième niveau décrit notre vision du système NL2SQL au cours des cinq prochaines années.
Nous décrivons l'évolution des solutions NL2SQL du point de vue des modèles de langage, la catégorisant en quatre étapes. Pour chaque étape de NL2SQL, nous analysons les modifications des utilisateurs cibles et la mesure dans laquelle les défis sont relevés.

? Méthodes NL2SQL basées sur le module
Nous résumons les modules clés des solutions NL2SQL en utilisant le modèle de langue.
- Le prétraitement sert d'amélioration aux entrées du modèle dans le processus d'analyse NL2SQL. Vous pouvez obtenir plus de détails de ce chapitre: prétraitement
- Les méthodes de traduction NL2SQL constituent le noyau de la solution NL2SQL, responsable de la conversion des requêtes en langage naturel en entrée en requêtes SQL. Vous pouvez obtenir plus de détails à partir de ce chapitre: NL2SQL Méthodes de traduction
- Le post-traitement est une étape cruciale pour affiner les requêtes SQL générées, garantissant qu'ils répondent plus précisément aux attentes des utilisateurs. Vous pouvez obtenir plus de détails de ce chapitre: post-traitement

ENQUÊTE ET TUTORAL NL2SQL
- Une étude de NL2SQL avec des modèles de grande langue: où sommes-nous, et où allons-nous?
- Interfaces de données de nouvelle génération: une étude du texte à SQL basé sur LLM.
- Modèle de grande langue amélioré de la génération de texte à SQL: une enquête.
- De la langue naturelle à SQL: examen des systèmes de texte à SQL basés sur LLM.
- Une enquête sur l'utilisation de modèles de langue importants pour les tâches de texte à SQL.
- Interfaces en langage naturel pour les requêtes et visualisation des données tabulaires: une enquête.
- Interfaces en langue naturelle pour les bases de données avec apprentissage en profondeur.
- Une enquête sur les approches d'apprentissage en profondeur pour le texte à SQL.
- Avancées récentes dans le texte à SQL: une enquête sur ce que nous avons et ce que nous attendons.
- Une plongée profonde dans les approches d'apprentissage en profondeur pour les systèmes de texte à SQL.
- De l'état de l'art et des défis ouverts dans les interfaces en langage naturel aux données.
- Langage naturel à SQL: Où en sommes-nous aujourd'hui?
? Liste de papier NL2SQL
- L'aube du langage naturel à SQL: sommes-nous pleinement prêts?
- Texte à SQL responsable par les grands modèles de langue: une évaluation de référence.
- Entrelacement des modèles de langage pré-formé et des modèles de grands langues pour la génération NL2SQL à tirs zéro.
- Génération de descriptions succinctes de schémas de base de données pour une incitation rentable des modèles de grandes langues.
- ScienceBenchmark: une référence complexe du monde réel pour évaluer le langage naturel aux systèmes SQL.
- Codes: Vers la construction de modèles de langue open source pour le texte à SQL.
- FINSQL: Framework Text-to-SQL basé sur les LLMS modèle pour l'analyse financière.
- Purple: Faire d'un grand modèle de langue un meilleur écrivain SQL.
- METASQL: Un cadre de génération entre le rang pour la traduction du langage naturel à SQL.
- Archer: un ensemble de données de texte à SQL marqué par l'homme avec un raisonnement arithmétique, bon sens et hypothétique.
- Synthèse des données de texte à SQL à partir de LLM faible et forte.
- Comprendre les effets du bruit dans le texte à SQL: un examen de la référence du banc d'oiseaux.
- J'ai besoin d'aide! Évaluation de la capacité de LLM à demander le support des utilisateurs: une étude de cas sur la génération de texte à SQL.
- PTD-SQL: partitionnement et forage ciblé avec LLMS en texte à SQL.
- Amélioration du texte à la récupération auprès de la récupération avec un classement basé sur l'AST et l'élagage des schémas.
- Texte à SQL centré sur les données avec de grands modèles de langue.
- Spider 2.0: Évaluation des modèles de langage sur les workflows de texte en entreprise du monde réel.
- Modèle de grande langue guidé par la structure pour la génération SQL.
- RSL-SQL: schéma robuste liant la génération de texte à SQL.
- TrustSQL: Benchmarking Text-to-SQL avec une notation basée sur les pénalités.
- SQL-Gen: combler l'écart de dialecte pour le texte à SQL via des données synthétiques et la fusion du modèle.
- Mise à la terre du langage naturel à la traduction SQL avec des auto-explications basées sur les données.
- CHASE-SQL: Raisonnement multi-PATH et préférence Sélection des candidats optimisés dans le texte à SQL.
- Vers l'optimisation de la génération SQL via le routage LLM.
- Xiyan-sql: un cadre d'ensemble multi-générateur pour le texte à SQL.
- E-SQL: schéma direct liant via l'enrichissement de la question en texte à SQL.
- DB-GPT: Autonomiser les interactions de la base de données avec des modèles privés de grande langue.
- La mort du schéma liant? Texte à SQL à l'ère des modèles de langage bien exploités.
- DBCOPILOT: Échelle de linguisme naturel Interroger dans des bases de données massives.
- Échecs: harnais contextuel pour une synthèse SQL efficace.
- PET-SQL: un raffinement à deux tours amélioré de texte à SQL avec une co-conscience.
- COE-SQL: Apprentissage en contexte pour le texte à plusieurs tournant avec la chaîne d'éditions.
- Ambrosia: une référence pour analyser les questions ambiguës dans les requêtes de base de données.
- Traduction de texte à SQL à quelques coups en utilisant l'apprentissage de la structure et de l'invite de contenu.
- Catsql: Vers le langage naturel du monde réel aux applications SQL.
- DIN-SQL: Apprentissage en contexte décomposé du texte à SQL avec auto-correction.
- L'ambiguïté des données revient: comment la documentation améliore le texte à SQL de GPT.
- ACT-SQL: Apprentissage dans le contexte pour le texte à SQL avec une chaîne de pensée générée automatiquement.
- Démonstrations sélectives pour le texte transversal de Text-to-SQL.
- Resdsql: liaison de schéma de découplage et analyse squelette pour le texte à SQL.
- Graphix-T5: Mélange de transformateurs pré-formés avec des couches de graphie pour l'analyse de texte à SQL.
- Amélioration de la généralisation dans l'analyse sémantique de texte basée sur des modèles de langage: deux techniques sémantiques basées sur les limites sémantiques simples.
- G 3 R: Un cadre de génération et de réduction guidé par graphe pour la génération de texte à domaine complexe et transversal.
- Importance de synthétiser des données de haute qualité pour l'analyse de texte à SQL.
- Sachez ce que je ne sais pas: gérer des questions ambiguës et inconnues pour le texte à SQL.
- C3: Texte à shot zéro avec Chatgpt
- MAC-SQL: un cadre collaboratif multi-agents pour le texte à SQL.
- SQLFORMER: Génération de graphiques de requête auto-régressive profonde pour la traduction du texte à SQL.
Benchmark NL2SQL
Nous créons un calendrier du développement de la référence et marquez les étapes pertinentes. Vous pouvez obtenir plus de détails de ce chapitre: Benchmark

Où allons-nous?
- Problème de Sovle Open NL2SQL
- Développer des méthodes NL2SQL rentables
- Rendre les solutions NL2SQL dignes de confiance
- NL2SQL avec des requêtes NL ambiguës et non spécifiées
- Synthèse des données de formation adaptative
Catalogue pour notre enquête
Vous pouvez obtenir plus d'informations de notre sous-section. Nous présentons des articles représentatifs sur des concepts connexes:
- Prétraitement
- Méthodes de traduction NL2SQL
- Post-traitement
- Référence
- Évaluation
- Analyse des erreurs
? Guide pratique pour novice
Comment obtenir des données:
- Nous collectons des fonctionnalités de référence NL2SQL et téléchargeons des liens pour vous. Vous pouvez obtenir plus de détails de ce chapitre: Benchmark
- Le code d'analyse pour les repères est disponible dans le répertoire
src/dataset_analysis . Des rapports d'analyse de référence peuvent être trouvés dans le report/ répertoire.
Comment construire un modèle NL2SQL basé sur LLM:
Lien de référentiel Litgpt
Ce référentiel offre un accès à plus de 20 modèles de langage grande performance (LLM) avec des guides complets pour la pré-formation, le réglage fin et le déploiement à grande échelle. Il est conçu pour être adapté aux débutants avec des implémentations à partir de casquettes et aucune abstraction complexe.
Liaison de référentiel de facteur llama de réglage finifié unifié de plus de 100 LLMS. Intégrant divers modèles avec des ressources de formation évolutives, des algorithmes avancés, des astuces pratiques et des outils de surveillance d'expérimentation complets, cette configuration permet une inférence efficace et plus rapide grâce à des API et des UIS optimisées.
Apprentissage fin et apprentissage en contexte pour le lien de référentiel de référence Bird-SQL
Un tutoriel pour l'apprentissage à deux remontés et en contexte est fourni par la référence Bird-SQL.
? Comment évaluer votre modèle:
Nous collectons pour vous des mesures d'évaluation NL2SQL. Vous pouvez obtenir plus de détails de ce chapitre: Évaluation
Lien de référentiel NLSQL360
NL2SQL360 est un banc d'essai pour une évaluation à grain fin des solutions NL2SQL. Notre banc d'essai intègre des repères NL2SQL existants, un référentiel de modèles NL2SQL et diverses mesures d'évaluation, qui vise à fournir une plate-forme intuitive et conviviale pour permettre des évaluations de performances standard et personnalisées.
Test-Suite-SQL-Eval Lien de référentiel
Ce dépôt contient une métrique d'évaluation de la suite de tests pour 11 tâches de texte à SQL. C'est maintenant la métrique officielle de Spider, SPARC et COSQL, et est également maintenant disponible pour les académiques, les ATI, le conseil, la géographie, l'IMDB, les restaurants, le savant et Yelp (Building on the Incroyable travail de Catherine et Jonathan).
Lien de référentiel officiel d'oiseau
C'est maintenant l'outil officiel de Bird-SQL. Il s'agit du premier outil à proposer VES et à donner une suite de test officielle.
? ️ Feuille de route et flux de décision
Vous pouvez vous inspirer de la feuille de route et du flux de décision.

Applications liées à NL2SQL:
- CHAT2DB: outil de base de données dirigée par AI et client SQL, le client GUI le plus chaud, prenant en charge MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, Clickhouse, etc.
- DB-GPT: Framework de développement d'applications de données natifs AI avec AWEL (Langage d'expression de flux de travail agentique) et les agents.
- Postgres.New: Sandbox de Postgres in-Browser avec l'aide de l'IA.


