Manual NL2SQL
A partir deste repositório, você pode visualizar os mais recentes avanços no NL2SQL. Este manual corresponde ao nosso documento de pesquisa: uma pesquisa do NL2SQL com grandes modelos de idiomas: onde estamos e para onde estamos indo?. Também fornecemos slides tutoriais para resumir os principais pontos desta pesquisa. Com base nas tendências no desenvolvimento de modelos de linguagem, criamos um diagrama de rios dos métodos NL2SQL para rastrear a evolução do campo NL2SQL.
Se você é um novato, não se preocupe - preparamos um guia prático para você, cobrindo uma ampla gama de materiais fundamentais aqui. Resumimos aplicativos relacionados ao NL2SQL.

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}? NL2SQL Introdução
Traduzir as consultas de linguagem natural dos usuários (NL) em consultas SQL pode reduzir significativamente as barreiras ao acesso a bancos de dados relacionais e apoiar várias aplicações comerciais. O desempenho do NL2SQL foi bastante aprimorado com o surgimento de modelos de linguagem (LMS). Nesse contexto, é crucial avaliar nossa posição atual, determinar as soluções NL2SQL que devem ser adotadas para cenários específicos pelos profissionais e identificar os tópicos de pesquisa que os pesquisadores devem explorar a seguir.
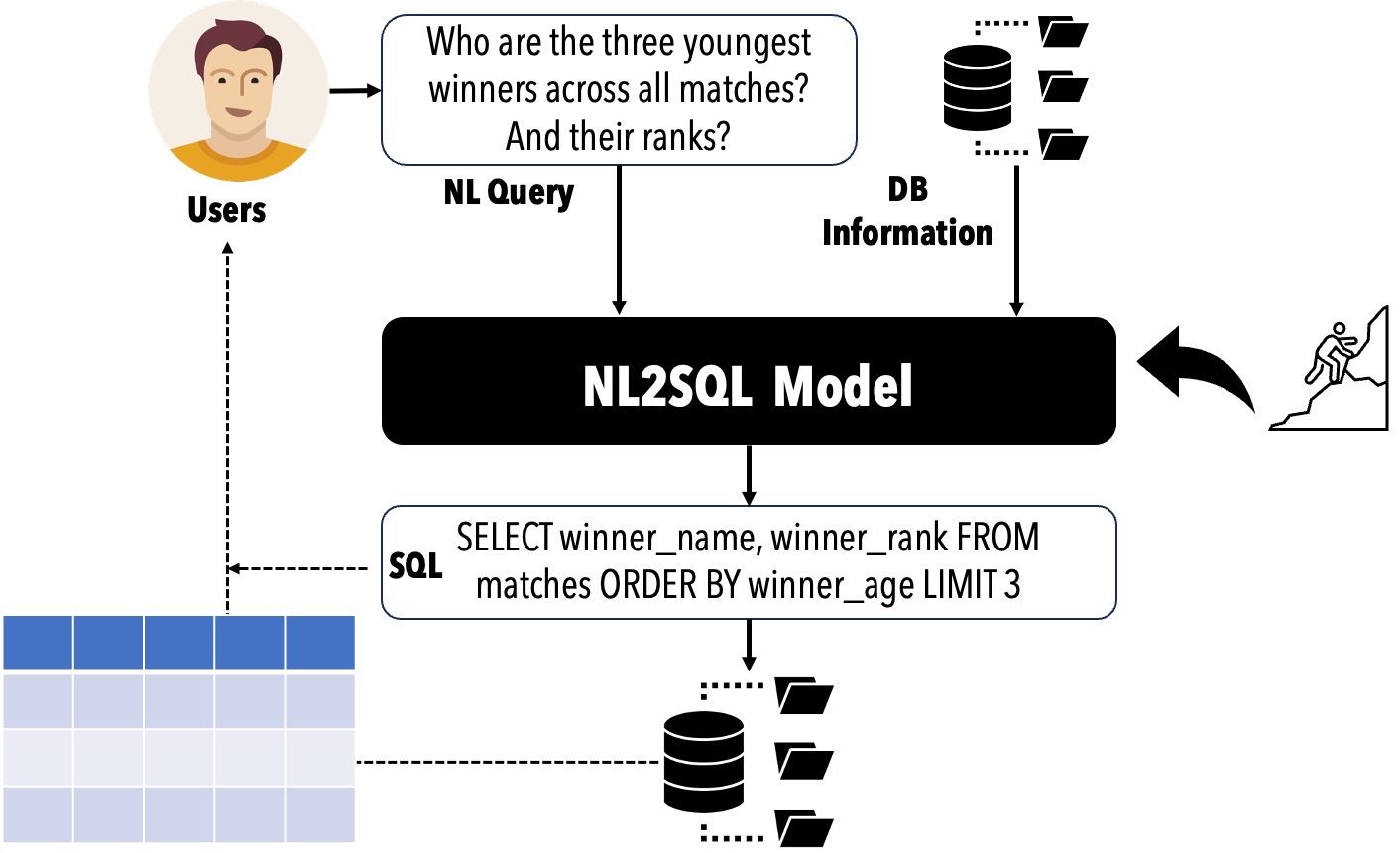
? Ciclo de vida NL2SQL

Modelo: técnicas de tradução NL2SQL que abordam não apenas a ambiguidade e a especificação do NL, mas também mapeiam adequadamente o NL com esquema e instâncias de banco de dados;
Dados: desde a coleta de dados de treinamento, a síntese de dados devido à escassez de dados de treinamento, aos benchmarks NL2SQL;
Avaliação: Avaliando os métodos NL2SQL a partir de múltiplos ângulos usando diferentes métricas e granularidades;
Análise de erros: Analisando erros de NL2SQL para encontrar a causa raiz e orientar os modelos NL2SQL a evoluir.
? Onde estamos?
Categorizamos os desafios do NL2SQL em cinco níveis, cada um abordando obstáculos específicos. Os três primeiros níveis abrangem desafios que foram ou estão sendo enfrentados atualmente, refletindo o desenvolvimento progressivo do NL2SQL. O quarto nível representa os desafios que pretendemos enfrentar no estágio LLMS, enquanto o quinto nível descreve nossa visão para o sistema NL2SQL nos próximos cinco anos.
Descrevemos a evolução das soluções NL2SQL da perspectiva dos modelos de linguagem, categorizando -o em quatro estágios. Para cada estágio do NL2SQL, analisamos as alterações nos usuários -alvo e até que ponto os desafios são enfrentados.

? Métodos NL2SQL baseados em módulo
Resumimos os principais módulos das soluções NL2SQL utilizando o modelo de idioma.
- O pré-processamento serve como um aprimoramento das entradas do modelo no processo de análise NL2SQL. Você pode obter mais detalhes deste capítulo: Pré-processamento
- Os métodos de tradução NL2SQL constituem o núcleo da solução NL2SQL, responsável por converter consultas de linguagem natural de entrada em consultas SQL. Você pode obter mais detalhes deste capítulo: Métodos de tradução NL2SQL
- O pós-processamento é uma etapa crucial para refinar as consultas SQL geradas, garantindo que elas atendam às expectativas do usuário com mais precisão. Você pode obter mais detalhes deste capítulo: Pós-processamento

Pesquisa e tutorial NL2SQL
- Uma pesquisa do NL2SQL com grandes modelos de idiomas: onde estamos nós e para onde estamos indo?
- Interfaces de banco de dados de próxima geração: uma pesquisa com texto para SQL baseado em LLM.
- Modelo de linguagem grande aumentou a geração de texto para SQL: uma pesquisa.
- Da linguagem natural ao SQL: Revisão de sistemas de texto para SQL baseados em LLM.
- Uma pesquisa sobre o emprego de grandes modelos de idiomas para tarefas de texto para SQL.
- Interfaces de linguagem natural para consulta e visualização de dados tabulares: uma pesquisa.
- Interfaces de linguagem natural para bancos de dados com aprendizado profundo.
- Uma pesquisa sobre abordagens de aprendizado profundo para o texto para SQL.
- Avanços recentes no texto-para-SQL: uma pesquisa do que temos e do que esperamos.
- Um profundo mergulho em abordagens de aprendizado profundo para sistemas de texto para SQL.
- Estado da arte e desafios abertos nas interfaces de linguagem natural aos dados.
- Linguagem natural para SQL: Onde estamos hoje?
? Lista de papel NL2SQL
- O amanhecer da linguagem natural para SQL: estamos totalmente prontos?
- Texto para SQL capacitado por grandes modelos de idiomas: uma avaliação de referência.
- Intercalando modelos de idiomas pré-treinados e grandes modelos de idiomas para geração NL2SQL de tiro zero.
- Gerando descrições sucintas de esquemas de banco de dados para solicitação econômica de grandes modelos de idiomas.
- ScienceBenchmark: uma referência complexa do mundo real para avaliar a linguagem natural aos sistemas SQL.
- Códigos: para criar modelos de idiomas de código aberto para texto para SQL.
- FINSQL: Modelo-Agnóstico LLMS baseado em texto para SQL para análise financeira.
- Roxo: Tornar um grande modelo de idioma um melhor escritor de SQL.
- METASQL: A GERER-THEN-RANK Framework para a linguagem natural para a tradução SQL.
- Archer: Um conjunto de dados de texto para SQL marcado humano com raciocínio aritmético, sensual e hipotético.
- Sintetizando dados de texto para SQL a partir de LLMs fracos e fortes.
- Compreendendo os efeitos do ruído no texto-para-SQL: um exame da referência do banco de pássaros.
- Eu preciso de ajuda! Avaliando a capacidade da LLM de solicitar suporte dos usuários: um estudo de caso sobre geração de texto para SQL.
- PTD-SQL: Particionamento e perfuração direcionada com LLMS no texto para SQL.
- Melhorando o texto para recuperação de recuperação, com ranking e poda de esquema baseado em AST.
- Data-Centric Text-to-SQL com grandes modelos de linguagem.
- Spider 2.0: Avaliando modelos de idiomas em fluxos de trabalho de texto para SQL do mundo real.
- Modelo de linguagem grande guiada por estrutura para geração SQL.
- RSL-SQL: Esquema robusto vinculando-se na geração de texto para SQL.
- TrustsQL: Benchmarking Text-to SQL Confiabilidade com pontuação baseada em penalidade.
- SQL-GEN: Bridging the Dialect Gap para texto para SQL por meio de dados sintéticos e fusão de modelos.
- Fundando a linguagem natural para a tradução SQL com auto-explicações baseadas em dados.
- CHASE-SQL: Raciocínio de vários caminhos e seleção de candidatos otimizados de preferência no texto para SQL.
- Para otimizar a geração SQL via roteamento LLM.
- XIYAN-SQL: Uma estrutura de conjunto multi-gerador para texto para SQL.
- E-SQL: Esquema direto vinculando por meio de enriquecimento de perguntas no texto-para-SQL.
- DB-GPT: Empoderando as interações do banco de dados com modelos de idiomas grandes privados.
- A morte do esquema vinculando? Texto para SQL na era dos modelos de idiomas bem fundamentados.
- DBCOPILOT: Escalando a consulta de linguagem natural para bancos de dados maciços.
- Xadrez: aproveitamento contextual para síntese eficiente de SQL.
- PET-SQL: Um refinamento de duas rodadas de texto rápido com o texto para SQL com consistência cruzada.
- COE-SQL: Aprendizagem no Contexto para Text-to-SQL de várias turnos com cadeia de edições.
- Ambrosia: Uma referência para analisar perguntas ambíguas em consultas de banco de dados.
- Tradução de texto para SQL com poucas fotos usando o aprendizado de estrutura e conteúdo.
- CATSQL: Para a linguagem natural do mundo real para aplicações SQL.
- DIN-SQL: Aprendizagem no contexto em contexto decomposto de texto para SQL com a auto-corrigir.
- A ambiguidade de dados ocorre de volta: como a documentação melhora o texto-para-SQL da GPT.
- ACT-SQL: Aprendizagem no contexto para texto para SQL com cadeia de pensamento gerada automaticamente.
- Demonstrações seletivas para o texto cruzado de texto para SQL.
- Resdsql: Desaparelar o esquema de vinculação e o esqueleto analisando o texto-para-sql.
- Graphix-T5: Misturando transformadores pré-treinados com camadas com reconhecimento gráfico para análise de texto para SQL.
- Melhorando a generalização na análise semântica de texto para modelos de idiomas: duas técnicas simples baseadas em limites semânticos.
- G 3 R: Uma estrutura de geração e liberação guiada por gráficos para geração de texto para sql complexa e cruzada.
- Importância de sintetizar dados de alta qualidade para análise de texto para SQL.
- Saiba o que não sei: lidar com perguntas ambíguas e desconhecidas para o texto para SQL.
- C3: Zero Shot Text-to-SQL com chatgpt
- MAC-SQL: Uma estrutura colaborativa multi-agente para texto para SQL.
- SQLFORMER: Geração de gráficos de consulta automática profunda para tradução de texto para SQL.
NL2SQL Benchmark
Criamos uma linha do tempo do desenvolvimento da referência e marcamos marcos relevantes. Você pode obter mais detalhes deste capítulo: Benchmark

Para onde estamos indo?
- SOVLE OPEN NL2SQL PROBLEMA
- Desenvolva métodos NL2SQL econômicos
- Torne as soluções NL2SQL confiáveis
- NL2SQL com consultas NL ambíguas e não especificadas
- Síntese de dados de treinamento adaptável
Catálogo para a nossa pesquisa
Você pode obter mais informações de nossa subseção. Introduzimos artigos representativos sobre conceitos relacionados:
- Pré-processamento
- Métodos de tradução NL2SQL
- Pós-processamento
- Benchmark
- Avaliação
- Análise de erros
? Guia prático para iniciantes
Como obter dados:
- Coletamos recursos de benchmark NL2SQL e baixamos links para você. Você pode obter mais detalhes deste capítulo: Benchmark
- O código de análise para benchmarks está disponível no diretório
src/dataset_analysis . Relatórios de análise de referência podem ser encontrados no report/ diretório.
Como construir um modelo NL2SQL baseado em LLM:
Link do repositório LitGPT
Este repositório oferece acesso a mais de 20 modelos de linguagem de grande desempenho (LLMS) com guias abrangentes para pré-treinamento, ajuste fino e implantação em escala. Ele foi projetado para ser adequado para iniciantes, com implementações de arranhões e sem abstrações complexas.
Link de repositório de fábrica de llama unificado eficiente ajuste fino de mais de 100 LLMs. Integrando vários modelos com recursos de treinamento escalonáveis, algoritmos avançados, truques práticos e ferramentas abrangentes de monitoramento de experimentos, essa configuração permite inferência eficiente e mais rápida por meio de APIs e UIs otimizadas.
Aprendizagem de ajuste fino e contexto para o link de repositório de benchmark Bird-SQL
Um tutorial para a aprendizagem de ajuste fino e em contexto é fornecido pelo benchmark Bird-SQL.
? Como avaliar seu modelo:
Coletamos métricas de avaliação NL2SQL para você. Você pode obter mais detalhes deste capítulo: Avaliação
Link do repositório NLSQL360
O NL2SQL360 é um teste para avaliação de granulação fina das soluções NL2SQL. Nosso teste de teste integra os benchmarks NL2SQL existentes, um repositório de modelos NL2SQL e várias métricas de avaliação, que visa fornecer uma plataforma intuitiva e amigável para ativar as avaliações de desempenho padrão e personalizadas.
Link de repositório Test-Suite-SQL-EVAL
Este repo contém uma métrica de avaliação do conjunto de testes para 11 tarefas de texto para SQL. Agora é a métrica oficial da Spider, SPARC e COSQL, e agora também está disponível para acadêmico, ATIS, aconselhamento, geografia, IMDB, restaurantes, estudiosos e Yelp (com base no trabalho incrível de Catherine e Jonathan).
Link de repositório oficial-de-sql
Agora é a ferramenta oficial do Bird-SQL. É a primeira ferramenta a propor VES e fornecer uma suíte de teste oficial.
? ️ Roteiro e fluxo de decisão
Você pode se inspirar no roteiro e no fluxo de decisão.

Aplicativos relacionados ao NL2SQL:
- Chat2db: Ferramenta de banco de dados acionada por IA e cliente SQL, o cliente GUI mais quente, suportando MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, Clickhouse e muito mais.
- DB-GPT: estrutura de desenvolvimento de aplicativos de dados nativos de IA com AWEL (Idioma de expressão de fluxo de trabalho Agentic) e agentes.
- PostGres.New: Sandbox no navegador Postgres com assistência de IA.


