NL2SQL Справочник
Из этого репозитория вы можете просмотреть последние достижения в NL2SQL. Этот справочник соответствует нашей документе опроса: опрос NL2SQL с большими языковыми моделями: куда мы и куда мы идем?. Мы также предоставляем учебные слайды, чтобы суммировать ключевые моменты этого опроса. Основываясь на тенденциях в разработке языковых моделей, мы создали речную диаграмму методов NL2SQL, чтобы проследить эволюцию поля NL2SQL.
Если вы новичок, не волнуйтесь - мы подготовили для вас практическое руководство, охватывающее здесь широкий спектр основополагающих материалов. Мы суммировали приложения, связанные с NL2SQL.

@misc { liu2024surveynl2sqllargelanguage ,
title = { A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? } ,
author = { Xinyu Liu and Shuyu Shen and Boyan Li and Peixian Ma and Runzhi Jiang and Yuyu Luo and Yuxin Zhang and Ju Fan and Guoliang Li and Nan Tang } ,
year = { 2024 } ,
eprint = { 2408.05109 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DB } ,
url = { https://arxiv.org/abs/2408.05109 } ,
}? NL2SQL ВВЕДЕНИЕ
Перевод запросов естественного языка пользователей (NL) в запросы SQL может значительно снизить барьеры для доступа к реляционным базам данных и поддержать различные коммерческие приложения. Производительность NL2SQL была значительно улучшена с появлением языковых моделей (LMS). В этом контексте крайне важно оценить нашу текущую позицию, определить решения NL2SQL, которые должны быть приняты для конкретных сценариев со стороны практиков, и определить темы исследования, которые исследователи должны исследовать дальше.
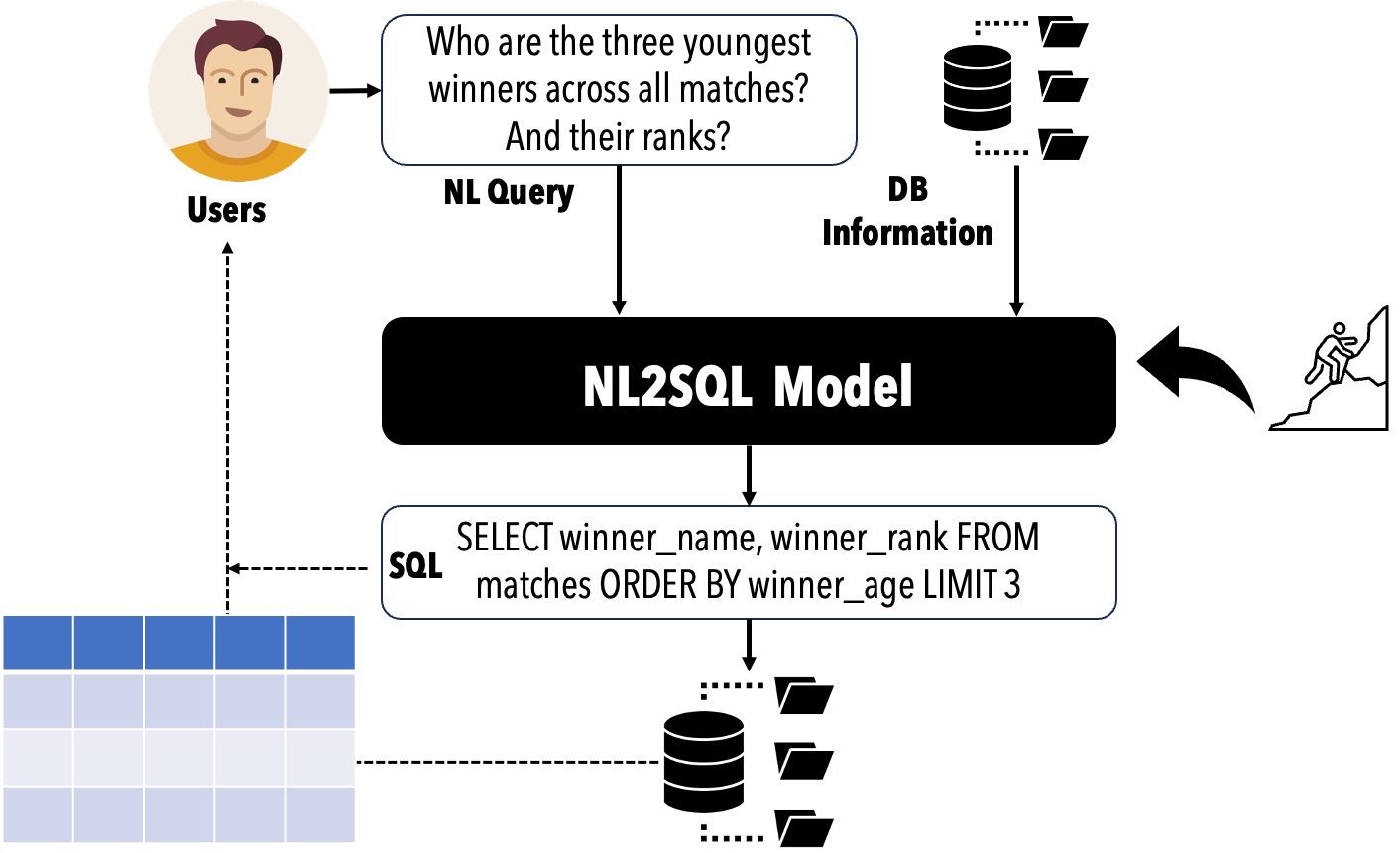
? NL2SQL LifeCycle

Модель: методы перевода NL2SQL, которые занимаются не только двусмысленностью NL и недостаточной спецификацией, но и надлежащим образом сопоставляют NL со схемой базы данных и экземплярами;
Данные: от сбора учебных данных, синтеза данных из -за дефицита обучения данных, до уровня NL2SQL;
Оценка: оценка методов NL2SQL с разных углов с использованием различных метрик и гранулярности;
Анализ ошибок: анализ ошибок NL2SQL, чтобы найти основную причину и направлять модели NL2SQL для развития.
? Где мы?
Мы классифицируем проблемы NL2SQL на пять уровней, каждый из которых рассматривает конкретные препятствия. Первые три уровня охватывают проблемы, которые были или в настоящее время решаются, что отражает прогрессивное развитие NL2SQL. Четвертый уровень представляет собой проблемы, которые мы стремимся решать на стадии LLMS, в то время как пятый уровень описывает наше видение системы NL2SQL в ближайшие пять лет.
Мы описываем эволюцию решений NL2SQL с точки зрения языковых моделей, классифицируя их на четыре этапа. Для каждого этапа NL2SQL мы анализируем изменения в целевых пользователях и степень решения проблем.

? Методы NL2SQL на основе модулей
Мы суммируем ключевые модули решений NL2SQL с использованием языковой модели.
- Предварительная обработка служит улучшением входов модели в процессе анализа NL2SQL. Вы можете получить более подробную информацию из этой главы: предварительная обработка
- Методы трансляции NL2SQL составляют ядро решения NL2SQL, отвечающего за преобразование запросов естественного языка в вводе в запросы SQL. Вы можете получить более подробную информацию из этой главы: методы перевода NL2SQL
- Пост-обработка -это решающий шаг для уточнения сгенерированных запросов SQL, обеспечивающих более точные ожидания пользователей. Вы можете получить более подробную информацию из этой главы: пост-обработка

Обследование и учебник NL2SQL
- Обзор NL2SQL с большими языковыми моделями: куда мы находимся и куда мы идем?
- Интерфейсы баз данных следующего поколения: обследование текста в SQL на основе LLM.
- Большая языковая модель Усовершенствованная генерация текста до SQL: опрос.
- От естественного языка до SQL: обзор систем Text-Sql на основе LLM.
- Опрос о использовании крупных языковых моделей для задач текста до SQL.
- Интерфейсы естественного языка для запросов и визуализации табличных данных: опрос.
- Интерфейсы естественного языка для баз данных с глубоким обучением.
- Опрос о подходах к глубокому обучению для текста в SQL.
- Недавние достижения в области текста в SQL: опрос того, что у нас есть и чего мы ожидаем.
- Глубокое погружение в глубокие подходы к обучению для систем текста в SQL.
- Состояние искусства и открытые проблемы в интерфейсах естественного языка с данными.
- Естественный язык для SQL: где мы сегодня?
? NL2SQL бумажный список
- Рассвет естественного языка для SQL: мы полностью готовы?
- Текст до SQL, наделенные большими языковыми моделями: эталонная оценка.
- Червейные предварительно обученные языковые модели и крупные языковые модели для генерации NL2SQL с нулевым выстрелом.
- Создание кратких описаний схемы базы данных для экономически эффективного подсказования моделей крупных языков.
- Sciencebenchmark: сложный реальный эталон для оценки естественного языка для SQL Systems.
- Коды: к созданию языковых моделей с открытым исходным кодом для текста до SQL.
- FINSQL: модель-алкогольную плату на основе LLMS Text-Sql Framework для финансового анализа.
- Фиолетовый: Сделать большую языковую модель лучшим писателем SQL.
- MetASQL: Generate-Then-Rank Framework для естественного языка для перевода SQL.
- ARCHER: меченный человеком набор данных Text-SQL с арифметикой, здравым смыслом и гипотетическими рассуждениями.
- Синтезирование данных текста к SQL из слабых и сильных LLMS.
- Понимание влияния шума в текстовом до-кв.
- Мне нужна помощь! Оценка способности LLM запрашивать поддержку пользователей: тематическое исследование по генерации текста в SQL.
- PTD-SQL: разделение и целевое бурение с LLMS в текстовом до SQL.
- Улучшение поиска-аугированного текста в SQL с рейтингом на основе AST и обрезкой схемы.
- Ориентированный на данные текст к SQL с большими языковыми моделями.
- SPIDER 2.0: Оценка языковых моделей на реальных рабочих процессах предприятия Text-Sql.
- Структура управляла большой языковой моделью для поколения SQL.
- RSL-SQL: надежная схема, связывающая в поколении текста к SQL.
- TrustSQL: сравнительная задача достоверности текста до SQL с помощью штрафной оценки.
- SQL-GEN: Соединение диалектного разрыва для текста до SQL с помощью синтетических данных и слияния модели.
- Основание естественного языка для перевода SQL с помощью самоэкспенцировки на основе данных.
- Chase-SQL: мультиплановые рассуждения и предпочтения оптимизированный выбор кандидатов в текстовом до SQL.
- К оптимизации генерации SQL через маршрутизацию LLM.
- Xiyan-SQL: ансамбль с несколькими поколениями для текста до SQL.
- E-SQL: прямая схема, связывающая через обогащение вопросов в текстовом до-SQL.
- DB-GPT: расширение возможностей взаимодействия базы данных с частными крупными языковыми моделями.
- Смерть схемы, связывающая? Текст-квл в эпоху хорошо разобранных языковых моделей.
- DBCOPILOT: масштабирование запросов естественного языка в массовых базах данных.
- Шахматы: контекстуальное использование для эффективного синтеза SQL.
- PET-SQL: усовершенствование двух раундов с подсказкой с перекрестным согласованностью.
- COE-SQL: Внутреннее обучение для многоворотного текста в SQL с цепочкой излузов.
- Ambrosia: эталон для неоднозначных вопросов разбора в вопросах базы данных.
- Несколько выстрелов трансляции текста в SQL с использованием структуры и контента быстрого обучения.
- CATSQL: к реальному естественному языку для приложений SQL.
- DIN-SQL: разложенное в контекстном порядке изучение текста в SQL с самокоррекцией.
- Данные неоднозначности возвращаются: как документация улучшает текст GPT-SQL.
- ACT-SQL: Внутреннее обучение для текста к SQL с автоматически генерируемой цепью.
- Селективные демонстрации для междоменного текста в SQL.
- RESDSQL: схема развязки, связывание и диапазон скелета для текста в SQL.
- Graphix-T5: смешивание предварительно обученных трансформаторов со слоями с графом для анализа текста в SQL.
- Улучшение обобщения в семантическом анализе на основе языковых моделей: два простых семантических метода на основе границ.
- G 3 R: фреймворк с графическим направлением для создания генерации комплексного и междомена.
- Важность синтеза высококачественных данных для анализа текста до SQL.
- Знайте, что я не знаю: обработка неоднозначных и неизвестных вопросов для текста в SQL.
- C3: с нулевым выстрелом текст в SQL с CHATGPT
- MAC-SQL: многоагентная совместная структура для текста в SQL.
- SQLFORMER: Глубокое генерация графиков запросов с ауторегрессивным запросом для перевода текста в SQL.
NL2SQL
Мы создаем график разработки теста и отмечаем соответствующие этапы. Вы можете получить более подробную информацию из этой главы: эталон

Куда мы идем?
- Sovle Open NL2SQL Проблема
- Разработать экономически эффективные методы NL2SQL
- Сделайте достоверные решения NL2SQL
- NL2SQL с неоднозначными и неуточненными NL -запросами
- Синтез адаптивного обучения синтез
Каталог для нашего опроса
Вы можете получить больше информации от нашего подраздела. Мы вводим репрезентативные статьи о связанных концепциях:
- Предварительная обработка
- NL2SQL Методы перевода
- Пост-обработка
- Эталон
- Оценка
- Анализ ошибок
? Практическое руководство для новичка
Как получить данные:
- Мы собираем для вас ссылки NL2SQL и ссылки для загрузки. Вы можете получить более подробную информацию из этой главы: эталон
- Код анализа для тестов доступен в каталоге
src/dataset_analysis . Отчеты о анализе эталона можно найти в report/ каталоге.
Как построить модель NL2SQL на основе LLM:
LITGPT Repository Link
Этот репозиторий предлагает доступ к более чем 20 высокопроизводительным моделям крупных языков (LLM) с комплексными руководствами для предварительной подготовки, тонкой настройки и развертывания в масштабе. Он предназначен для того, чтобы быть для начинающих, с реализациями от скрещивания и без сложных абстракций.
Лама-фактическая репозитория связывает единую эффективную точную настройку 100+ LLMS. Интегрируя различные модели с масштабируемыми учебными ресурсами, передовыми алгоритмами, практическими трюками и комплексными инструментами мониторинга экспериментов, эта настройка обеспечивает эффективные и более быстрые выводы с помощью оптимизированных API и пользовательских интерфейсов.
Точная настраиваемая и встроенная обучение для перепозитория Bird-SQL.
Учебное пособие как для точной настройки, так и для обучения в контексте обеспечивается эталоном Bird-SQL.
? Как оценить вашу модель:
Мы собираем для вас метрики оценки NL2SQL. Вы можете получить более подробную информацию из этой главы: оценка
NLSQL360 Ссылка
NL2SQL360 является испытательным стендом для мелкозернистой оценки решений NL2SQL. Наш тестовый стенд объединяет существующие тесты NL2SQL, репозиторий моделей NL2SQL и различные показатели оценки, которые направлены на предоставление интуитивно понятной и удобной платформы для обеспечения как стандартной, так и индивидуальной оценки производительности.
Теста-suite-sql-eval ссылка на хранилище
Этот репо содержит метрику оценки тестового пакета для 11 задач текста к SQL. В настоящее время это официальный показатель Spider, Sparc и Cosql, а также теперь доступен для академических, ATIS, консультирования, географии, IMDB, ресторанов, ученых и Yelp (опираясь на удивительную работу Кэтрин и Джонатана).
Официальная репозитория Bird-SQL
Теперь это официальный инструмент Bird-SQL. Это первый инструмент для предложения VES и предоставления официального набора тестов.
? ️ дорожная карта и поток решений
Вы можете получить некоторое вдохновение от дорожной карты и потока решений.

Приложения, связанные с NL2SQL:
- CHAT2DB: ИИ-управляемый инструмент базы данных и клиент SQL, самый горячий клиент GUI, поддержка MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLITE, H2, Clickhouse и многое другое.
- DB-GPT: Структура разработки приложений для приложений для нативных данных ИИ с AWEL (Язык выражения агента рабочего процесса) и агенты.
- Postgres.new: в браузера Postgres Sandbox с помощью ИИ.


