BERTopic
v0.16.4

Bertopic เป็นเทคนิคการสร้างแบบจำลองหัวข้อที่ใช้ประโยชน์หรือไม่? Transformers และ C-TF-IDF เพื่อสร้างกลุ่มหนาแน่นช่วยให้หัวข้อที่ตีความได้ง่ายในขณะที่รักษาคำสำคัญในคำอธิบายหัวข้อ
Bertopic รองรับเทคนิคการสร้างแบบจำลองหัวข้อทุกประเภท:
| ที่ได้ถูกชี้นำ | ดูแล | กึ่งอุณหภูมิ |
| คู่มือ | การแจกแจงแบบหลายหัวข้อ | เกี่ยวกับลำดับชั้น |
| เกี่ยวกับชั้นเรียน | พลวัต | ออนไลน์/เพิ่ม |
| หลายรูปแบบ | หลายครั้ง | การสร้างข้อความ/LLM |
| zero-shot (ใหม่!) | ผสานโมเดล (ใหม่!) | คำพูดของเมล็ดพันธุ์ (ใหม่!) |
โพสต์สื่อที่เกี่ยวข้องสามารถพบได้ที่นี่ที่นี่และที่นี่ สำหรับภาพรวมโดยละเอียดเพิ่มเติมคุณสามารถอ่านกระดาษหรือดูภาพรวมโดยย่อ
การติดตั้งพร้อมกับการเปลี่ยนประโยคสามารถทำได้โดยใช้ PYPI:
pip install bertopicหากคุณต้องการติดตั้ง bertopic กับรุ่น Embedding อื่น ๆ คุณสามารถเลือกอย่างใดอย่างหนึ่งต่อไปนี้:
# Choose an embedding backend
pip install bertopic[flair,gensim,spacy,use]
# Topic modeling with images
pip install bertopic[vision]สำหรับภาพรวมเชิงลึกของคุณสมบัติของ Bertopic คุณสามารถตรวจสอบ เอกสารฉบับเต็ม หรือคุณสามารถติดตามพร้อมกับหนึ่งในตัวอย่างด้านล่าง:
| ชื่อ | การเชื่อมโยง |
|---|---|
| เริ่มต้นที่นี่ - แนวปฏิบัติที่ดีที่สุดใน Bertopic | |
| - ใหม่! - การสร้างแบบจำลองหัวข้อเกี่ยวกับข้อมูลขนาดใหญ่ (การเร่งความเร็ว GPU) | |
| - ใหม่! - การสร้างแบบจำลองหัวข้อด้วย Llama 2? | |
| - ใหม่! - การสร้างแบบจำลองหัวข้อด้วย LLM แบบเชิงปริมาณ | |
| การสร้างแบบจำลองหัวข้อด้วย bertopic | |
| (กำหนดเอง) แบบจำลองการฝังใน bertopic | |
| การปรับแต่งขั้นสูงใน bertopic | |
| (กึ่ง) การสร้างแบบจำลองหัวข้อภายใต้การดูแลด้วย bertopic | |
| การสร้างแบบจำลองหัวข้อแบบไดนามิกกับทวีตของทรัมป์ | |
| การสร้างแบบจำลองหัวข้อบทคัดย่อ arxiv |
เราเริ่มต้นด้วยการแยกหัวข้อจากชุดข้อมูลกลุ่มข่าวที่รู้จักกันดี 20 ชุดที่มีเอกสารภาษาอังกฤษ:
from bertopic import BERTopic
from sklearn . datasets import fetch_20newsgroups
docs = fetch_20newsgroups ( subset = 'all' , remove = ( 'headers' , 'footers' , 'quotes' ))[ 'data' ]
topic_model = BERTopic ()
topics , probs = topic_model . fit_transform ( docs )หลังจากสร้างหัวข้อและความน่าจะเป็นของพวกเขาเราสามารถเข้าถึงหัวข้อทั้งหมดพร้อมกับการเป็นตัวแทนหัวข้อของพวกเขา:
> >> topic_model . get_topic_info ()
Topic Count Name
- 1 4630 - 1_ can_your_will_any
0 693 49_ windows_drive_dos_file
1 466 32_j esus_bible_christian_faith
2 441 2_ space_launch_orbit_lunar
3 381 22_ key_encryption_keys_encrypted
... หัวข้อ -1 หมายถึงเอกสารที่ผิดปกติทั้งหมดและโดยทั่วไปจะถูกละเว้น แต่ละคำในหัวข้ออธิบายธีมพื้นฐานของหัวข้อนั้นและสามารถใช้สำหรับการตีความหัวข้อนั้น ถัดไปลองดูหัวข้อที่พบบ่อยที่สุดที่สร้างขึ้น:
> >> topic_model . get_topic ( 0 )
[( 'windows' , 0.006152228076250982 ),
( 'drive' , 0.004982897610645755 ),
( 'dos' , 0.004845038866360651 ),
( 'file' , 0.004140142872194834 ),
( 'disk' , 0.004131678774810884 ),
( 'mac' , 0.003624848635985097 ),
( 'memory' , 0.0034840976976789903 ),
( 'software' , 0.0034415334250699077 ),
( 'email' , 0.0034239554442333257 ),
( 'pc' , 0.003047105930670237 )] การใช้ .get_document_info เรายังสามารถแยกข้อมูลในระดับเอกสารเช่นหัวข้อที่สอดคล้องกันความน่าจะเป็นไม่ว่าจะเป็นเอกสารตัวแทนสำหรับหัวข้อ ฯลฯ :
> >> topic_model . get_document_info ( docs )
Document Topic Name Top_n_words Probability ...
I am sure some bashers of Pens ... 0 0_ game_team_games_season game - team - games ... 0.200010 ...
My brother is in the market for ... - 1 - 1_ can_your_will_any can - your - will ... 0.420668 ...
Finally you said what you dream ... - 1 - 1_ can_your_will_any can - your - will ... 0.807259 ...
Think ! It ' s the SCSI card doing ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.071746 ...
1 ) I have an old Jasmine drive ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.038983 ... Tip : ใช้ BERTopic(language="multilingual") เพื่อเลือกรุ่นที่รองรับ 50+ ภาษา
ใน Bertopic มีการแสดงหัวข้อต่าง ๆ จำนวนมากที่เราสามารถเลือกได้ พวกเขาทั้งหมดค่อนข้างแตกต่างจากกันและให้มุมมองที่น่าสนใจและการเปลี่ยนแปลงของการเป็นตัวแทนหัวข้อ การเริ่มต้นที่ยอดเยี่ยมคือ KeyBERTInspired ซึ่งสำหรับผู้ใช้จำนวนมากเพิ่มการเชื่อมโยงกันและลดคำสั่งหยุดจากการแสดงหัวข้อผลลัพธ์:
from bertopic . representation import KeyBERTInspired
# Fine-tune your topic representations
representation_model = KeyBERTInspired ()
topic_model = BERTopic ( representation_model = representation_model )อย่างไรก็ตามคุณอาจต้องการใช้สิ่งที่ทรงพลังกว่าเพื่ออธิบายกลุ่มของคุณ คุณสามารถใช้ CHATGPT หรือรุ่นอื่น ๆ จาก OpenAI เพื่อสร้างฉลากสรุปวลีคำหลักและอื่น ๆ :
import openai
from bertopic . representation import OpenAI
# Fine-tune topic representations with GPT
client = openai . OpenAI ( api_key = "sk-..." )
representation_model = OpenAI ( client , model = "gpt-3.5-turbo" , chat = True )
topic_model = BERTopic ( representation_model = representation_model ) Tip : แทนที่จะวนซ้ำในการเป็นตัวแทนหัวข้อที่แตกต่างกันทั้งหมดเหล่านี้คุณสามารถสร้างแบบจำลองพร้อมกันด้วยการแสดงหัวข้อหลายหัวข้อใน Bertopic
หลังจากฝึกอบรมแบบจำลอง bertopic ของเราเราสามารถผ่านหัวข้อหลายร้อยหัวข้อเพื่อให้เข้าใจหัวข้อที่สกัดได้ดี อย่างไรก็ตามนั่นต้องใช้เวลาพอสมควรและขาดการเป็นตัวแทนระดับโลก แต่เราสามารถใช้หนึ่งในตัวเลือกการสร้างภาพข้อมูลมากมายใน Bertopic ตัวอย่างเช่นเราสามารถเห็นภาพหัวข้อที่สร้างขึ้นในลักษณะที่คล้ายกับ LDAVIS:
topic_model . visualize_topics ()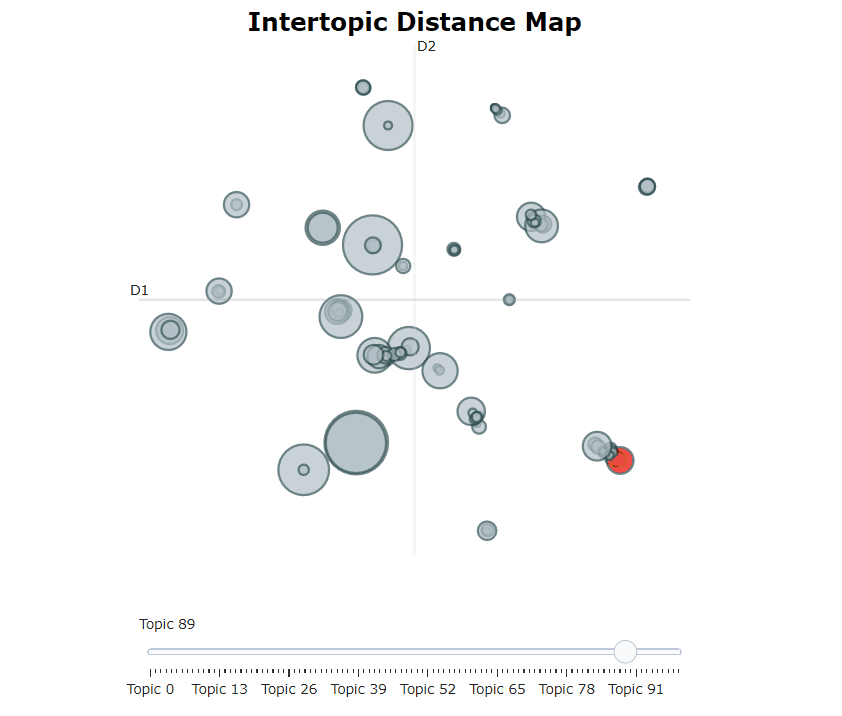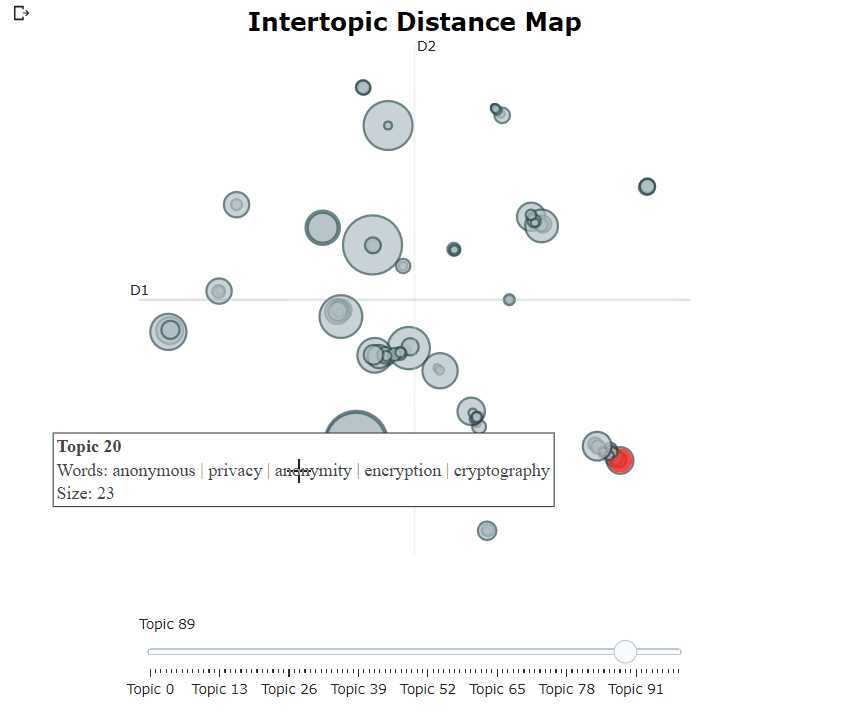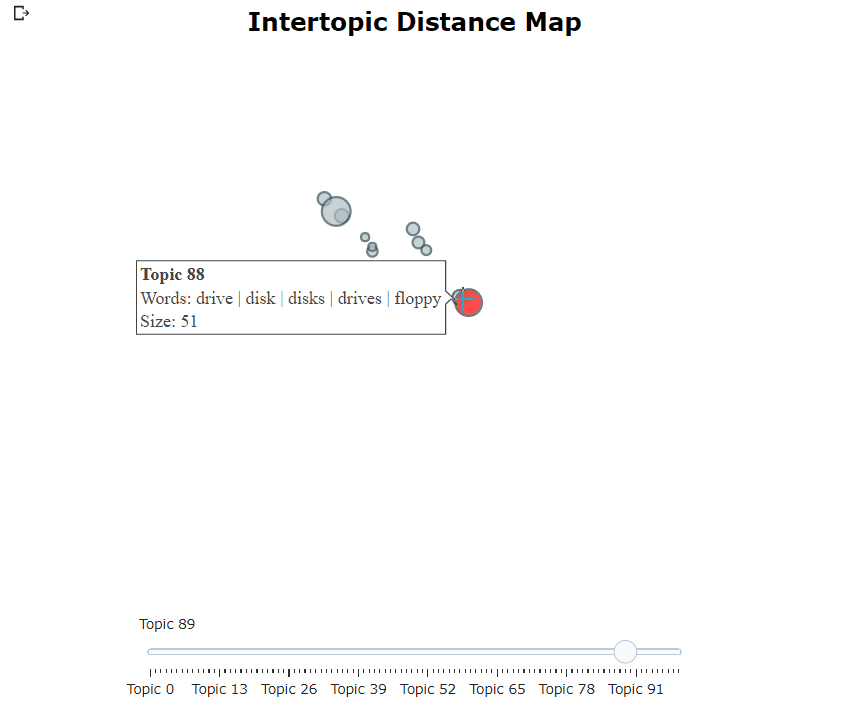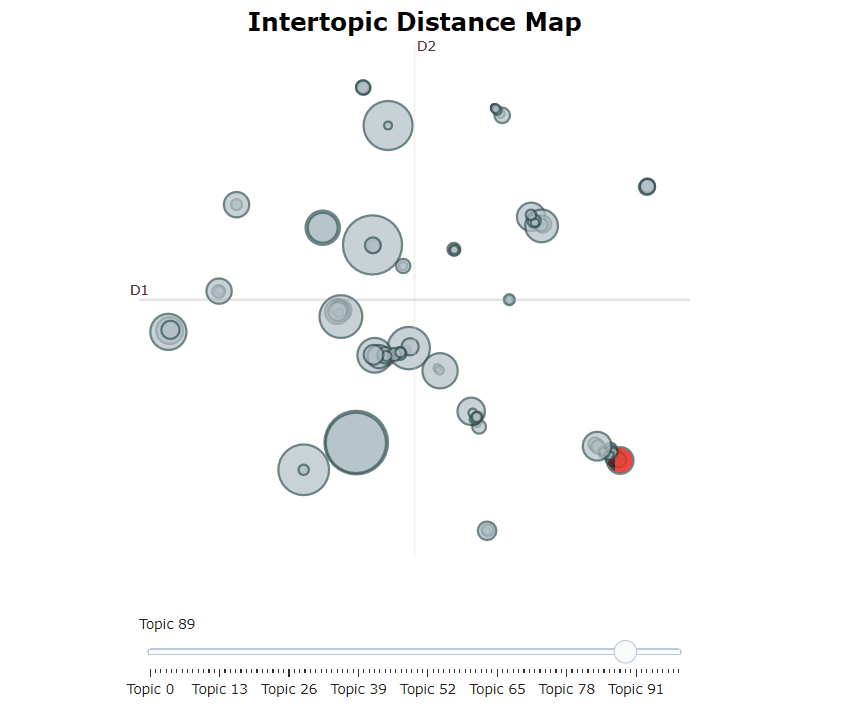
โดยค่าเริ่มต้นขั้นตอนหลักสำหรับการสร้างแบบจำลองหัวข้อด้วย bertopic คือการแปลงประโยค, UMAP, HDBSCAN และ C-TF-IDF ทำงานตามลำดับ อย่างไรก็ตามมันถือว่าเป็นอิสระบางอย่างระหว่างขั้นตอนเหล่านี้ซึ่งทำให้ bertopic ค่อนข้างเป็นโมดูล กล่าวอีกนัยหนึ่ง Bertopic ไม่เพียง แต่อนุญาตให้คุณสร้างโมเดลหัวข้อของคุณเองเท่านั้น แต่ยังสำรวจเทคนิคการสร้างแบบจำลองหัวข้อต่างๆที่อยู่ด้านบนของโมเดลหัวข้อที่กำหนดเอง:
คุณสามารถแลกเปลี่ยนโมเดลเหล่านี้หรือลบออกทั้งหมด ขั้นตอนต่อไปนี้เป็นโมดูลอย่างสมบูรณ์:
Bertopic มีฟังก์ชั่นมากมายที่สามารถครอบงำได้อย่างรวดเร็ว เพื่อบรรเทาปัญหานี้คุณจะพบภาพรวมของวิธีการทั้งหมดและคำอธิบายสั้น ๆ เกี่ยวกับวัตถุประสงค์
ด้านล่างคุณจะพบภาพรวมของฟังก์ชั่นทั่วไปใน Bertopic
| วิธี | รหัส |
|---|---|
| พอดีกับรุ่น | .fit(docs) |
| พอดีกับโมเดลและทำนายเอกสาร | .fit_transform(docs) |
| ทำนายเอกสารใหม่ | .transform([new_doc]) |
| เข้าถึงหัวข้อเดียว | .get_topic(topic=12) |
| เข้าถึงหัวข้อทั้งหมด | .get_topics() |
| รับหัวข้อ freq | .get_topic_freq() |
| รับข้อมูลหัวข้อทั้งหมด | .get_topic_info() |
| รับข้อมูลเอกสารทั้งหมด | .get_document_info(docs) |
| รับเอกสารตัวแทนต่อหัวข้อ | .get_representative_docs() |
| อัปเดตหัวข้อการแสดง | .update_topics(docs, n_gram_range=(1, 3)) |
| สร้างฉลากหัวข้อ | .generate_topic_labels() |
| ตั้งค่าฉลากหัวข้อ | .set_topic_labels(my_custom_labels) |
| หัวข้อผสาน | .merge_topics(docs, topics_to_merge) |
| ลด NR ของหัวข้อ | .reduce_topics(docs, nr_topics=30) |
| ลดค่าผิดปกติ | .reduce_outliers(docs, topics) |
| ค้นหาหัวข้อ | .find_topics("vehicle") |
| บันทึกโมเดล | .save("my_model", serialization="safetensors") |
| โหลดโมเดล | BERTopic.load("my_model") |
| รับพารามิเตอร์ | .get_params() |
หลังจากฝึกอบรมแบบจำลอง bertopic ของคุณแล้วคุณลักษณะหลายอย่างจะถูกบันทึกไว้ในโมเดลของคุณ แอตทริบิวต์เหล่านี้ส่วนหนึ่งอ้างถึงวิธีการจัดเก็บข้อมูลโมเดลบนตัวประมาณในระหว่างการปรับให้เหมาะสม คุณลักษณะที่คุณเห็นด้านล่างทั้งหมดใน _ และเป็นแอตทริบิวต์สาธารณะที่สามารถใช้ในการเข้าถึงข้อมูลโมเดล
| คุณลักษณะ | คำอธิบาย |
|---|---|
.topics_ | หัวข้อที่สร้างขึ้นสำหรับแต่ละเอกสารหลังจากการฝึกอบรมหรืออัปเดตโมเดลหัวข้อ |
.probabilities_ | ความน่าจะเป็นที่สร้างขึ้นสำหรับแต่ละเอกสารหากใช้ HDBSCAN |
.topic_sizes_ | ขนาดของแต่ละหัวข้อ |
.topic_mapper_ | ชั้นเรียนสำหรับการติดตามหัวข้อและการแมปของพวกเขาทุกครั้งที่พวกเขาถูกรวม/ลดลง |
.topic_representations_ | คำศัพท์ N สูงสุดต่อหัวข้อและค่า C-TF-IDF ที่เกี่ยวข้อง |
.c_tf_idf_ | เมทริกซ์หัวข้อระยะที่คำนวณผ่าน C-TF-IDF |
.topic_aspects_ | แง่มุมต่าง ๆ หรือการเป็นตัวแทนของแต่ละหัวข้อ |
.topic_labels_ | ป้ายกำกับเริ่มต้นสำหรับแต่ละหัวข้อ |
.custom_labels_ | ฉลากที่กำหนดเองสำหรับแต่ละหัวข้อที่สร้างผ่าน. .set_topic_labels |
.topic_embeddings_ | EMBEDDINGS สำหรับแต่ละหัวข้อหากใช้ embedding_model |
.representative_docs_ | เอกสารตัวแทนสำหรับแต่ละหัวข้อหากใช้ HDBSCAN |
มีกรณีการใช้งานที่แตกต่างกันมากมายในการสร้างแบบจำลองหัวข้อ ดังนั้นจึงมีการพัฒนา bertopic หลายรูปแบบเพื่อให้สามารถใช้แพ็คเกจหนึ่งในหลายกรณีการใช้งาน
| วิธี | รหัส |
|---|---|
| การประมาณการกระจายหัวข้อ | .approximate_distribution(docs) |
| การสร้างแบบจำลองหัวข้อออนไลน์ | .partial_fit(doc) |
| การสร้างแบบจำลองหัวข้อกึ่งหัวเมือง | .fit(docs, y=y) |
| การสร้างแบบจำลองหัวข้อภายใต้การดูแล | .fit(docs, y=y) |
| การสร้างแบบจำลองหัวข้อด้วยตนเอง | .fit(docs, y=y) |
| การสร้างแบบจำลองหัวข้อหลายรูปแบบ | .fit(docs, images=images) |
| การสร้างแบบจำลองหัวข้อต่อคลาส | .topics_per_class(docs, classes) |
| การสร้างแบบจำลองหัวข้อแบบไดนามิก | .topics_over_time(docs, timestamps) |
| การสร้างแบบจำลองหัวข้อลำดับชั้น | .hierarchical_topics(docs) |
| การสร้างแบบจำลองหัวข้อนำทาง | BERTopic(seed_topic_list=seed_topic_list) |
| การสร้างแบบจำลองหัวข้อ zero-shot | BERTopic(zeroshot_topic_list=zeroshot_topic_list) |
| รวมหลายรุ่น | BERTopic.merge_models([topic_model_1, topic_model_2]) |
การประเมินรูปแบบหัวข้ออาจค่อนข้างยากเนื่องจากลักษณะการประเมินแบบอัตนัย การมองเห็นแง่มุมต่าง ๆ ของโมเดลหัวข้อช่วยในการทำความเข้าใจโมเดลและทำให้ง่ายต่อการปรับแต่งโมเดลตามความชอบของคุณ
| วิธี | รหัส |
|---|---|
| แสดงภาพหัวข้อ | .visualize_topics() |
| แสดงภาพเอกสาร | .visualize_documents() |
| แสดงภาพลำดับชั้นของเอกสาร | .visualize_hierarchical_documents() |
| แสดงภาพลำดับชั้นของหัวข้อ | .visualize_hierarchy() |
| ทรีหัวข้อภาพ | .get_topic_tree(hierarchical_topics) |
| คำศัพท์หัวข้อภาพ | .visualize_barchart() |
| ภาพความคล้ายคลึงกันของหัวข้อ | .visualize_heatmap() |
| เห็นภาพคำศัพท์ที่ลดลง | .visualize_term_rank() |
| แสดงภาพการกระจายความน่าจะเป็นของหัวข้อ | .visualize_distribution(probs[0]) |
| ภาพหัวข้อเมื่อเวลาผ่านไป | .visualize_topics_over_time(topics_over_time) |
| แสดงภาพหัวข้อต่อคลาส | .visualize_topics_per_class(topics_per_class) |
หากต้องการอ้างอิงกระดาษ bertopic โปรดใช้การอ้างอิง BibTex ต่อไปนี้:
@article{grootendorst2022bertopic,
title={BERTopic: Neural topic modeling with a class-based TF-IDF procedure},
author={Grootendorst, Maarten},
journal={arXiv preprint arXiv:2203.05794},
year={2022}
}


