BERTopic
v0.16.4

Bertopic adalah teknik pemodelan topik yang memanfaatkan? Transformers dan C-TF-IDF untuk membuat cluster padat yang memungkinkan topik yang mudah ditafsirkan sambil menyimpan kata-kata penting dalam deskripsi topik.
Bertopic mendukung semua jenis teknik pemodelan topik:
| Dipandu | Diawasi | Semi-diawasi |
| Manual | Distribusi multi-topik | Hierarkis |
| Berbasis kelas | Dinamis | Online/Incremental |
| Multimodal | Multi-aspek | Pembuatan teks/llm |
| Zero-shot (baru!) | Model Gabungan (Baru!) | Kata benih (baru!) |
Posting medium yang sesuai dapat ditemukan di sini, di sini dan di sini. Untuk ikhtisar yang lebih rinci, Anda dapat membaca kertas atau melihat tinjauan singkat.
Instalasi, dengan kalimat-transformer, dapat dilakukan dengan menggunakan PYPI:
pip install bertopicJika Anda ingin menginstal Bertopic dengan model embedding lainnya, Anda dapat memilih salah satu dari yang berikut:
# Choose an embedding backend
pip install bertopic[flair,gensim,spacy,use]
# Topic modeling with images
pip install bertopic[vision]Untuk ikhtisar mendalam tentang fitur Bertopic, Anda dapat memeriksa dokumentasi lengkap atau Anda dapat mengikuti dengan salah satu contoh di bawah ini:
| Nama | Link |
|---|---|
| Mulai di sini - Praktik Terbaik di Bertopic | |
| ? Baru! - Pemodelan topik pada data besar (akselerasi GPU) | |
| ? Baru! - Pemodelan topik dengan llama 2? | |
| ? Baru! - Pemodelan topik dengan llms terkuantisasi | |
| Pemodelan topik dengan Bertopic | |
| (Kustom) Model penyematan di Bertopic | |
| Kustomisasi lanjutan di Bertopic | |
| (Semi-) Pemodelan topik yang diawasi dengan Bertopic | |
| Pemodelan topik dinamis dengan tweet Trump | |
| Topic Modeling Arxiv Abstrak |
Kami mulai dengan mengekstraksi topik dari dataset 20 newsgroup terkenal yang berisi dokumen bahasa Inggris:
from bertopic import BERTopic
from sklearn . datasets import fetch_20newsgroups
docs = fetch_20newsgroups ( subset = 'all' , remove = ( 'headers' , 'footers' , 'quotes' ))[ 'data' ]
topic_model = BERTopic ()
topics , probs = topic_model . fit_transform ( docs )Setelah menghasilkan topik dan probabilitasnya, kami dapat mengakses semua topik bersama dengan representasi topik mereka:
> >> topic_model . get_topic_info ()
Topic Count Name
- 1 4630 - 1_ can_your_will_any
0 693 49_ windows_drive_dos_file
1 466 32_j esus_bible_christian_faith
2 441 2_ space_launch_orbit_lunar
3 381 22_ key_encryption_keys_encrypted
... Topik -1 mengacu pada semua dokumen outlier dan biasanya diabaikan. Setiap kata dalam suatu topik menjelaskan tema yang mendasari topik itu dan dapat digunakan untuk menafsirkan topik itu. Selanjutnya, mari kita lihat topik paling sering yang dihasilkan:
> >> topic_model . get_topic ( 0 )
[( 'windows' , 0.006152228076250982 ),
( 'drive' , 0.004982897610645755 ),
( 'dos' , 0.004845038866360651 ),
( 'file' , 0.004140142872194834 ),
( 'disk' , 0.004131678774810884 ),
( 'mac' , 0.003624848635985097 ),
( 'memory' , 0.0034840976976789903 ),
( 'software' , 0.0034415334250699077 ),
( 'email' , 0.0034239554442333257 ),
( 'pc' , 0.003047105930670237 )] Menggunakan .get_document_info , kami juga dapat mengekstrak informasi pada tingkat dokumen, seperti topik yang sesuai, probabilitas, apakah mereka adalah dokumen yang representatif untuk suatu topik, dll.:
> >> topic_model . get_document_info ( docs )
Document Topic Name Top_n_words Probability ...
I am sure some bashers of Pens ... 0 0_ game_team_games_season game - team - games ... 0.200010 ...
My brother is in the market for ... - 1 - 1_ can_your_will_any can - your - will ... 0.420668 ...
Finally you said what you dream ... - 1 - 1_ can_your_will_any can - your - will ... 0.807259 ...
Think ! It ' s the SCSI card doing ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.071746 ...
1 ) I have an old Jasmine drive ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.038983 ... Tip : Gunakan BERTopic(language="multilingual") untuk memilih model yang mendukung 50+ bahasa.
Di Bertopic, ada sejumlah representasi topik berbeda yang dapat kita pilih. Mereka semua sangat berbeda satu sama lain dan memberikan perspektif yang menarik dan variasi representasi topik. Awal yang bagus adalah KeyBERTInspired , yang bagi banyak pengguna meningkatkan koherensi dan mengurangi stopword dari representasi topik yang dihasilkan:
from bertopic . representation import KeyBERTInspired
# Fine-tune your topic representations
representation_model = KeyBERTInspired ()
topic_model = BERTopic ( representation_model = representation_model )Namun, Anda mungkin ingin menggunakan sesuatu yang lebih kuat untuk menggambarkan kelompok Anda. Anda bahkan dapat menggunakan chatgpt atau model lain dari openai untuk menghasilkan label, ringkasan, frasa, kata kunci, dan banyak lagi:
import openai
from bertopic . representation import OpenAI
# Fine-tune topic representations with GPT
client = openai . OpenAI ( api_key = "sk-..." )
representation_model = OpenAI ( client , model = "gpt-3.5-turbo" , chat = True )
topic_model = BERTopic ( representation_model = representation_model ) Tip : Alih-alih mengulangi semua representasi topik yang berbeda ini, Anda dapat memodelkannya secara bersamaan dengan representasi topik multi-aspek di Bertopic.
Setelah melatih model Bertopic kami, kami dapat secara iteratif melalui ratusan topik untuk mendapatkan pemahaman yang baik tentang topik yang diekstraksi. Namun, itu membutuhkan waktu cukup lama dan tidak memiliki representasi global. Sebaliknya, kita dapat menggunakan salah satu dari banyak opsi visualisasi di Bertopic. Misalnya, kita dapat memvisualisasikan topik yang dihasilkan dengan cara yang sangat mirip dengan LDAVIS:
topic_model . visualize_topics ()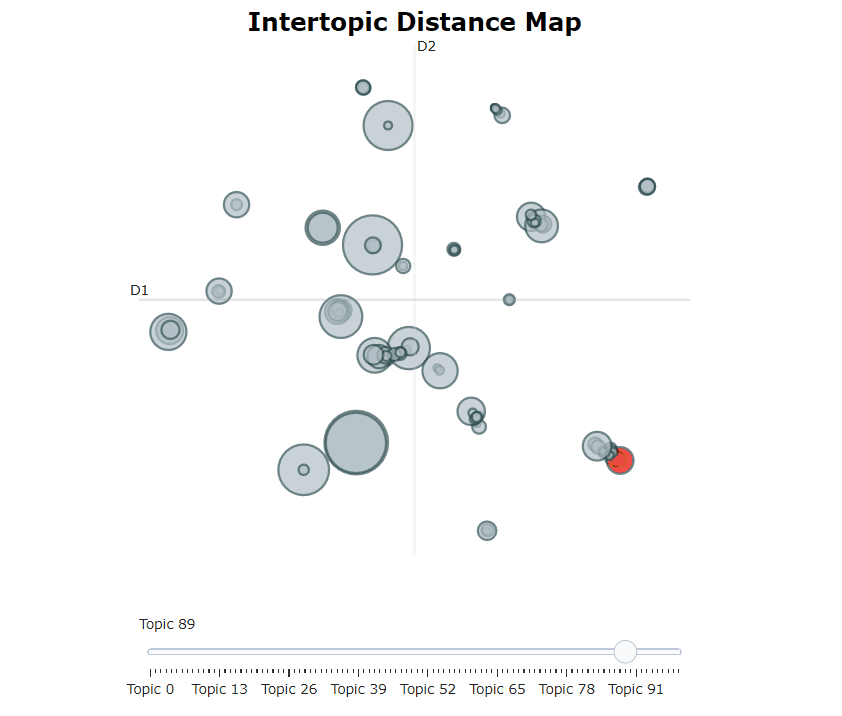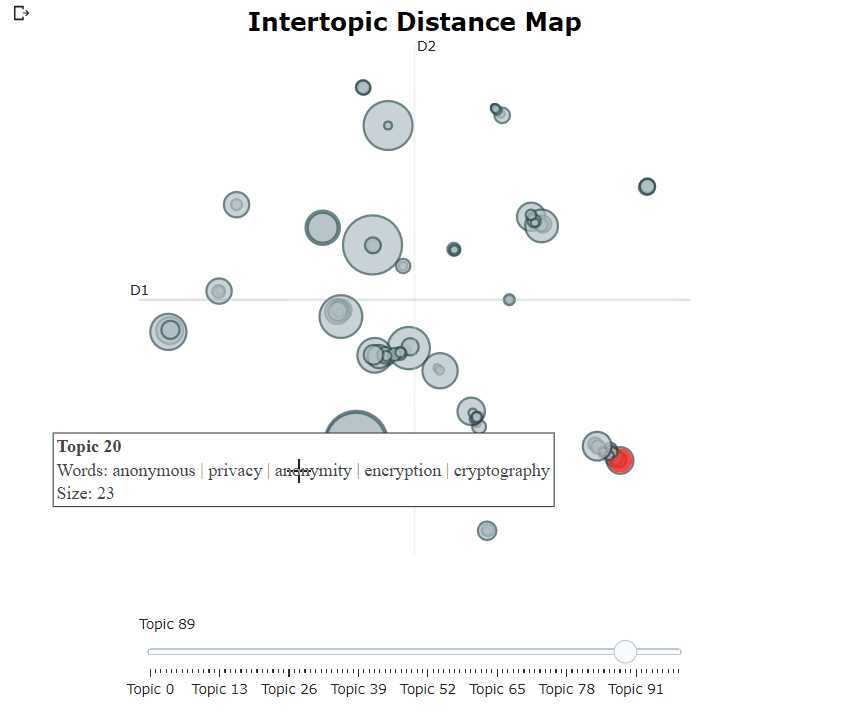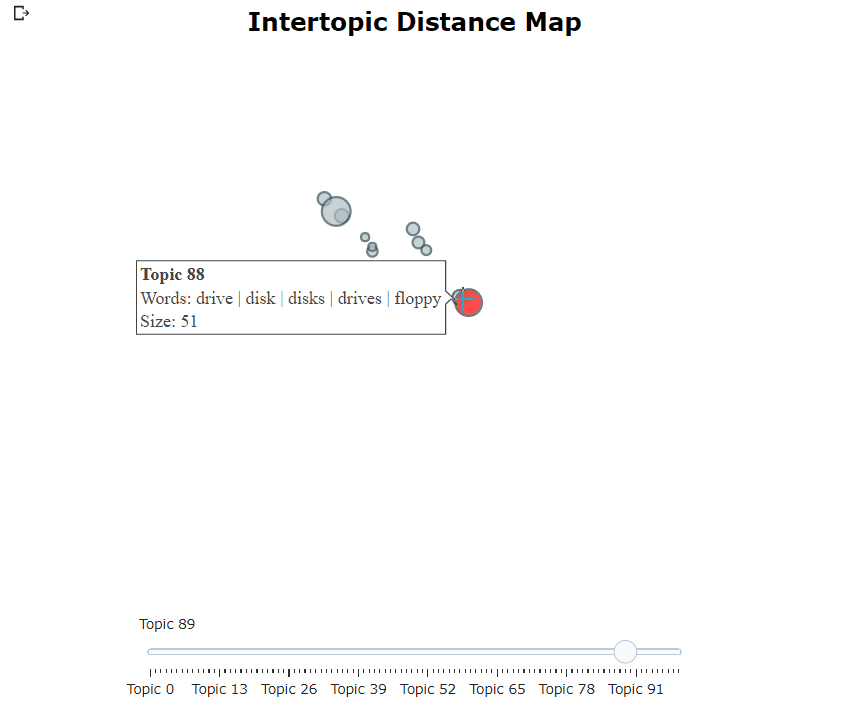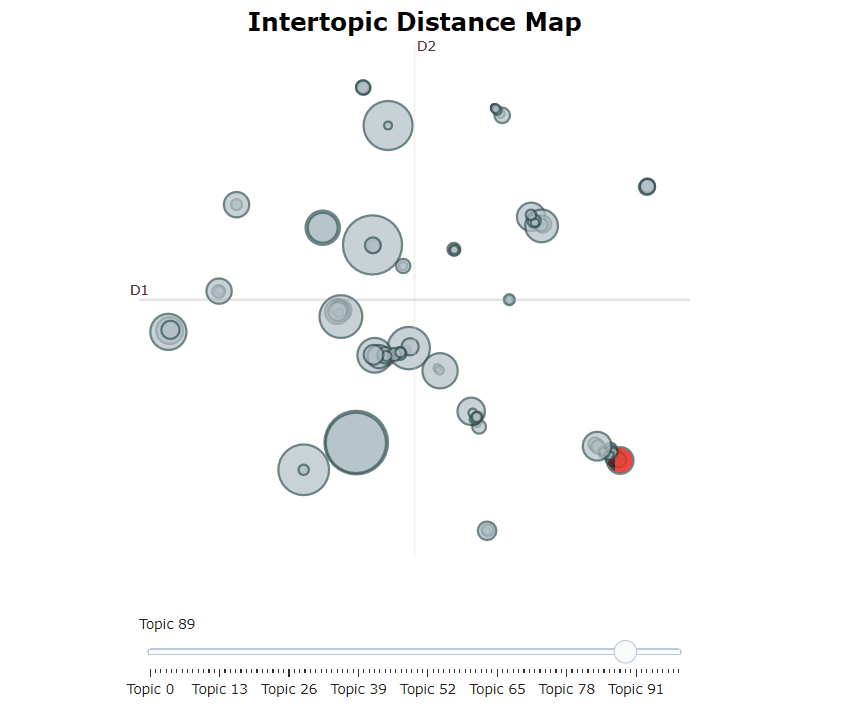
Secara default, langkah-langkah utama untuk pemodelan topik dengan Bertopic adalah kalimat kalimat, UMAP, HDBSCAN, dan C-TF-IDF dijalankan secara berurutan. Namun, ia mengasumsikan beberapa independensi antara langkah -langkah ini yang membuat Bertopic cukup modular. Dengan kata lain, Bertopic tidak hanya memungkinkan Anda untuk membangun model topik Anda sendiri tetapi untuk mengeksplorasi beberapa teknik pemodelan topik di atas model topik khusus Anda:
Anda dapat menukar salah satu model ini atau bahkan menghapusnya sepenuhnya. Langkah -langkah berikut sepenuhnya modular:
Bertopic memiliki banyak fungsi yang dengan cepat bisa menjadi luar biasa. Untuk mengurangi masalah ini, Anda akan menemukan gambaran umum dari semua metode dan deskripsi singkat tentang tujuannya.
Di bawah ini, Anda akan menemukan ikhtisar fungsi umum di Bertopic.
| Metode | Kode |
|---|---|
| Sesuai dengan model | .fit(docs) |
| Sesuai dengan model dan memprediksi dokumen | .fit_transform(docs) |
| Memprediksi dokumen baru | .transform([new_doc]) |
| Akses topik tunggal | .get_topic(topic=12) |
| Akses semua topik | .get_topics() |
| Dapatkan topik freq | .get_topic_freq() |
| Dapatkan semua informasi topik | .get_topic_info() |
| Dapatkan semua informasi dokumen | .get_document_info(docs) |
| Dapatkan dokumen perwakilan per topik | .get_representative_docs() |
| Perbarui Representasi Topik | .update_topics(docs, n_gram_range=(1, 3)) |
| Menghasilkan label topik | .generate_topic_labels() |
| Tetapkan label topik | .set_topic_labels(my_custom_labels) |
| Gabungkan topik | .merge_topics(docs, topics_to_merge) |
| Kurangi NR topik | .reduce_topics(docs, nr_topics=30) |
| Kurangi outlier | .reduce_outliers(docs, topics) |
| Temukan topik | .find_topics("vehicle") |
| Simpan model | .save("my_model", serialization="safetensors") |
| Model Muat | BERTopic.load("my_model") |
| Dapatkan parameter | .get_params() |
Setelah melatih model Bertopic Anda, beberapa atribut disimpan dalam model Anda. Atribut ini, sebagian, merujuk pada bagaimana informasi model disimpan pada estimator selama pemasangan. Atribut yang Anda lihat di bawah semua berakhir di _ dan merupakan atribut publik yang dapat digunakan untuk mengakses informasi model.
| Atribut | Keterangan |
|---|---|
.topics_ | Topik yang dihasilkan untuk setiap dokumen setelah pelatihan atau memperbarui model topik. |
.probabilities_ | Probabilitas yang dihasilkan untuk setiap dokumen jika HDBSCAN digunakan. |
.topic_sizes_ | Ukuran setiap topik |
.topic_mapper_ | Kelas untuk melacak topik dan pemetaan mereka kapan saja mereka digabungkan/dikurangi. |
.topic_representations_ | Istilah N teratas per topik dan nilai C-TF-IDF masing-masing. |
.c_tf_idf_ | Matriks termatur topik sebagaimana dihitung melalui C-TF-IDF. |
.topic_aspects_ | Berbagai aspek, atau representasi, dari setiap topik. |
.topic_labels_ | Label default untuk setiap topik. |
.custom_labels_ | Label khusus untuk setiap topik seperti yang dihasilkan melalui .set_topic_labels . |
.topic_embeddings_ | Embeddings untuk setiap topik jika embedding_model digunakan. |
.representative_docs_ | Dokumen yang representatif untuk setiap topik jika HDBSCAN digunakan. |
Ada banyak kasus penggunaan yang berbeda di mana pemodelan topik dapat digunakan. Dengan demikian, beberapa variasi Bertopic telah dikembangkan sedemikian rupa sehingga satu paket dapat digunakan di banyak kasus penggunaan.
| Metode | Kode |
|---|---|
| Perkiraan distribusi topik | .approximate_distribution(docs) |
| Pemodelan topik online | .partial_fit(doc) |
| Pemodelan topik semi-diawasi | .fit(docs, y=y) |
| Pemodelan topik yang diawasi | .fit(docs, y=y) |
| Pemodelan topik manual | .fit(docs, y=y) |
| Pemodelan topik multimodal | .fit(docs, images=images) |
| Pemodelan topik per kelas | .topics_per_class(docs, classes) |
| Pemodelan Topik Dinamis | .topics_over_time(docs, timestamps) |
| Pemodelan topik hierarkis | .hierarchical_topics(docs) |
| Pemodelan topik terpandu | BERTopic(seed_topic_list=seed_topic_list) |
| Pemodelan Topik Zero-Shot | BERTopic(zeroshot_topic_list=zeroshot_topic_list) |
| Gabungkan banyak model | BERTopic.merge_models([topic_model_1, topic_model_2]) |
Mengevaluasi model topik bisa agak sulit karena sifat evaluasi yang agak subyektif. Memvisualisasikan berbagai aspek model topik membantu dalam memahami model dan membuatnya lebih mudah untuk mengubah model sesuai keinginan Anda.
| Metode | Kode |
|---|---|
| Visualisasikan topik | .visualize_topics() |
| Visualisasikan dokumen | .visualize_documents() |
| Visualisasikan Hirarki Dokumen | .visualize_hierarchical_documents() |
| Visualisasikan Hirarki Topik | .visualize_hierarchy() |
| Visualisasikan pohon topik | .get_topic_tree(hierarchical_topics) |
| Visualisasikan istilah topik | .visualize_barchart() |
| Visualisasikan kesamaan topik | .visualize_heatmap() |
| Visualisasikan Penurunan Skor Istilah | .visualize_term_rank() |
| Visualisasikan Distribusi Probabilitas Topik | .visualize_distribution(probs[0]) |
| Visualisasikan topik dari waktu ke waktu | .visualize_topics_over_time(topics_over_time) |
| Visualisasikan topik per kelas | .visualize_topics_per_class(topics_per_class) |
Untuk mengutip kertas Bertopic, silakan gunakan referensi Bibtex berikut:
@article{grootendorst2022bertopic,
title={BERTopic: Neural topic modeling with a class-based TF-IDF procedure},
author={Grootendorst, Maarten},
journal={arXiv preprint arXiv:2203.05794},
year={2022}
}


