BERTopic
v0.16.4

Bertopicは、活用するトピックモデリング手法ですか?トランスとC-TF-IDFは、トピックの説明に重要な単語を保持しながら、簡単に解釈できるトピックを可能にする密なクラスターを作成します。
Bertopicは、あらゆる種類のトピックモデリング手法をサポートしています。
| ガイド付き | 監督 | 半監督 |
| マニュアル | マルチトピック分布 | 階層 |
| クラスベース | 動的 | オンライン/増分 |
| マルチモーダル | マルチアスペクト | テキスト生成/LLM |
| ゼロショット(新規!) | モデルのマージ(新しい!) | シードワード(新しい!) |
対応する中程度の投稿は、こちら、こちらとこちらをご覧ください。より詳細な概要については、論文を読んだり、簡単な概要をご覧ください。
文の変換器を使用したインストールは、PYPIを使用して行うことができます。
pip install bertopic他の埋め込みモデルでBertopicをインストールする場合は、次のいずれかを選択できます。
# Choose an embedding backend
pip install bertopic[flair,gensim,spacy,use]
# Topic modeling with images
pip install bertopic[vision]Bertopicの機能の詳細な概要については、完全なドキュメントを確認するか、以下の例の1つをフォローできます。
| 名前 | リンク |
|---|---|
| ここから始めます -ベルトピックのベストプラクティス | |
| ?新しい! - 大規模なデータのトピックモデリング(GPU加速) | |
| ?新しい! -Llama2を使用したトピックモデリング? | |
| ?新しい! - 量子化されたLLMを使用したトピックモデリング | |
| ベルトピックによるトピックモデリング | |
| (カスタム)ベルトピックの埋め込みモデル | |
| Bertopicの高度なカスタマイズ | |
| (セミ)ベルトピックによる監視されたトピックモデリング | |
| トランプのツイートによる動的トピックモデリング | |
| トピックモデリングARXIV要約 |
英語文書を含む有名な20のニュースグループデータセットからトピックを抽出することから始めます。
from bertopic import BERTopic
from sklearn . datasets import fetch_20newsgroups
docs = fetch_20newsgroups ( subset = 'all' , remove = ( 'headers' , 'footers' , 'quotes' ))[ 'data' ]
topic_model = BERTopic ()
topics , probs = topic_model . fit_transform ( docs )トピックとその確率を生成した後、トピック表現と一緒にすべてのトピックにアクセスできます。
> >> topic_model . get_topic_info ()
Topic Count Name
- 1 4630 - 1_ can_your_will_any
0 693 49_ windows_drive_dos_file
1 466 32_j esus_bible_christian_faith
2 441 2_ space_launch_orbit_lunar
3 381 22_ key_encryption_keys_encrypted
... -1トピックは、すべての外れ値ドキュメントを指し、通常は無視されます。トピックの各単語は、そのトピックの根本的なテーマを説明し、そのトピックを解釈するために使用できます。次に、生成された最も頻繁なトピックを見てみましょう。
> >> topic_model . get_topic ( 0 )
[( 'windows' , 0.006152228076250982 ),
( 'drive' , 0.004982897610645755 ),
( 'dos' , 0.004845038866360651 ),
( 'file' , 0.004140142872194834 ),
( 'disk' , 0.004131678774810884 ),
( 'mac' , 0.003624848635985097 ),
( 'memory' , 0.0034840976976789903 ),
( 'software' , 0.0034415334250699077 ),
( 'email' , 0.0034239554442333257 ),
( 'pc' , 0.003047105930670237 )] .get_document_info使用すると、対応するトピック、確率、トピックの代表的なドキュメントなど、ドキュメントレベルに関する情報を抽出することもできます。
> >> topic_model . get_document_info ( docs )
Document Topic Name Top_n_words Probability ...
I am sure some bashers of Pens ... 0 0_ game_team_games_season game - team - games ... 0.200010 ...
My brother is in the market for ... - 1 - 1_ can_your_will_any can - your - will ... 0.420668 ...
Finally you said what you dream ... - 1 - 1_ can_your_will_any can - your - will ... 0.807259 ...
Think ! It ' s the SCSI card doing ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.071746 ...
1 ) I have an old Jasmine drive ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.038983 ... Tip : BERTopic(language="multilingual")を使用して、50以上の言語をサポートするモデルを選択します。
Bertopicでは、選択できるさまざまなトピック表現がいくつかあります。それらはすべて互いにまったく異なり、トピック表現の興味深い視点とバリエーションを与えます。素晴らしいスタートはKeyBERTInspiredであり、多くのユーザーにとって一貫性を高め、結果のトピック表現からストップワードを減らすことができます。
from bertopic . representation import KeyBERTInspired
# Fine-tune your topic representations
representation_model = KeyBERTInspired ()
topic_model = BERTopic ( representation_model = representation_model )ただし、クラスターを説明するために、より強力なものを使用することをお勧めします。 OpenaiのChatGptやその他のモデルを使用して、ラベル、要約、フレーズ、キーワードなどを生成することもできます。
import openai
from bertopic . representation import OpenAI
# Fine-tune topic representations with GPT
client = openai . OpenAI ( api_key = "sk-..." )
representation_model = OpenAI ( client , model = "gpt-3.5-turbo" , chat = True )
topic_model = BERTopic ( representation_model = representation_model ) Tip :これらのさまざまなトピック表現のすべてを反復する代わりに、Bertopicのマルチアスペクトトピック表現と同時にモデル化できます。
脳視モデルを訓練した後、繰り返し何百ものトピックを調べて、抽出されたトピックをよく理解することができます。しかし、それにはかなりの時間がかかり、グローバルな表現がありません。代わりに、Bertopicの多くの視覚化オプションの1つを使用できます。たとえば、Ldavisに非常によく似た方法で生成されたトピックを視覚化できます。
topic_model . visualize_topics ()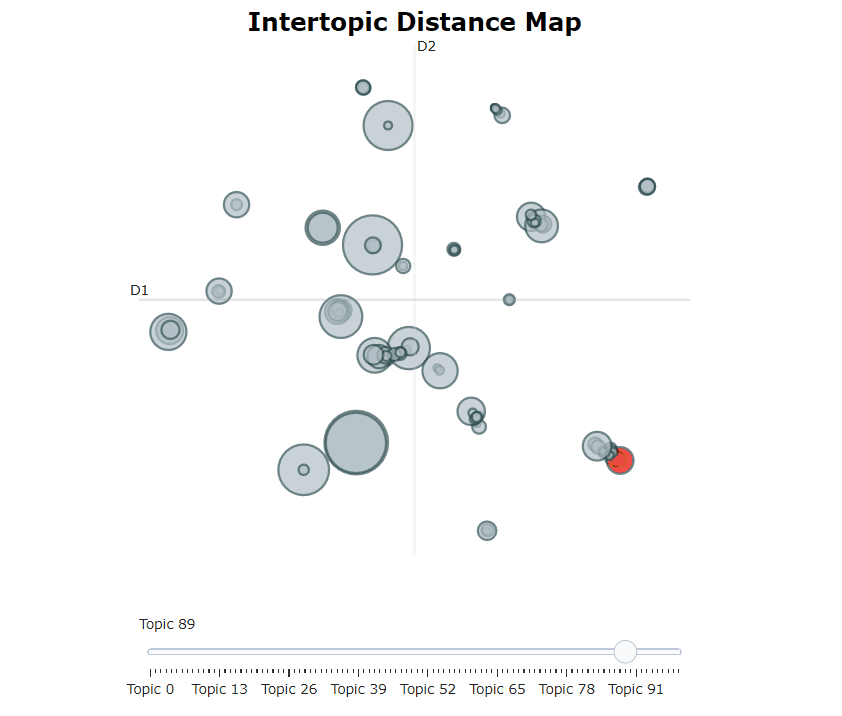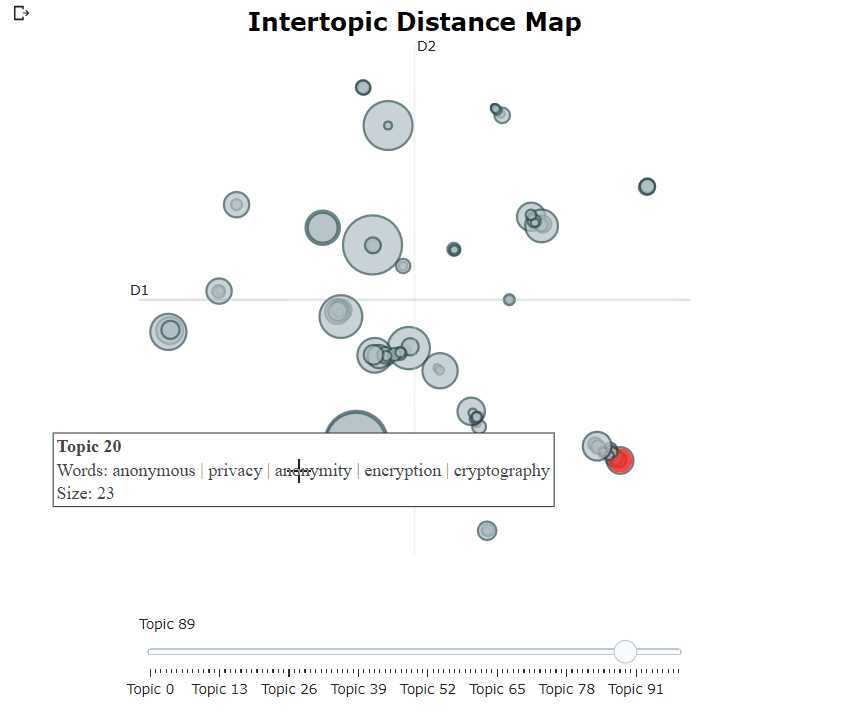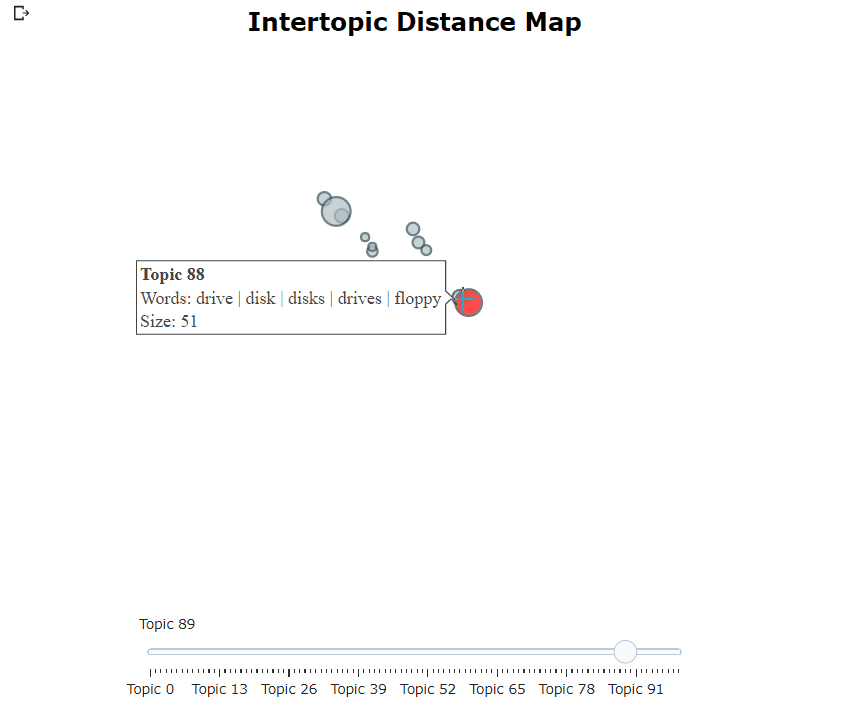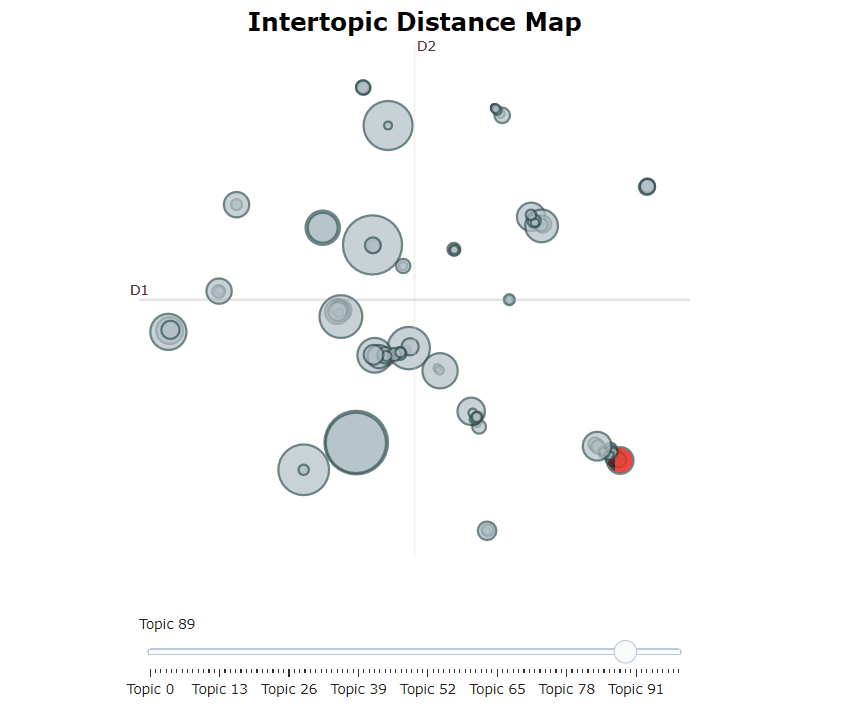
デフォルトでは、Bertopicを使用したトピックモデリングの主な手順は、文化変換者、UMAP、HDBSCAN、およびC-TF-IDFが順番に実行されます。ただし、これらのステップ間の独立性を想定しているため、Bertopicを非常にモジュール化します。言い換えれば、Bertopicでは、独自のトピックモデルを構築できるだけでなく、カスタマイズされたトピックモデルに加えていくつかのトピックモデリング手法を探求することができます。
これらのモデルのいずれかを交換したり、完全に削除することもできます。次の手順は完全にモジュール式です。
Bertopicには多くの機能があり、すぐに圧倒的になります。この問題を軽減するために、すべての方法の概要とその目的の簡単な説明が見つかります。
以下に、Bertopicの一般的な関数の概要を示します。
| 方法 | コード |
|---|---|
| モデルに適合します | .fit(docs) |
| モデルに適合し、ドキュメントを予測します | .fit_transform(docs) |
| 新しいドキュメントを予測します | .transform([new_doc]) |
| 単一のトピックにアクセスします | .get_topic(topic=12) |
| すべてのトピックにアクセスします | .get_topics() |
| トピックfreqを取得します | .get_topic_freq() |
| すべてのトピック情報を取得します | .get_topic_info() |
| すべてのドキュメント情報を取得します | .get_document_info(docs) |
| トピックごとに代表的なドキュメントを取得します | .get_representative_docs() |
| トピック表現を更新します | .update_topics(docs, n_gram_range=(1, 3)) |
| トピックラベルを生成します | .generate_topic_labels() |
| トピックラベルを設定します | .set_topic_labels(my_custom_labels) |
| トピックをマージします | .merge_topics(docs, topics_to_merge) |
| トピックのNRを削減します | .reduce_topics(docs, nr_topics=30) |
| 外れ値を減らします | .reduce_outliers(docs, topics) |
| トピックを見つけます | .find_topics("vehicle") |
| モデルを保存します | .save("my_model", serialization="safetensors") |
| ロードモデル | BERTopic.load("my_model") |
| パラメーターを取得します | .get_params() |
ベルトピックモデルを訓練した後、モデル内にいくつかの属性が保存されます。これらの属性は、一部には、フィッティング中にモデル情報が推定器に保存される方法を指します。以下に表示される属性は_で_で、モデル情報にアクセスするために使用できるパブリック属性です。
| 属性 | 説明 |
|---|---|
.topics_ | トピックモデルのトレーニングまたは更新後に各ドキュメントに対して生成されるトピック。 |
.probabilities_ | HDBSCANが使用されている場合、各ドキュメントに対して生成される確率。 |
.topic_sizes_ | 各トピックのサイズ |
.topic_mapper_ | トピックとそのマッピングを追跡するためのクラスは、いつでもマージ/削減されます。 |
.topic_representations_ | トピックごとの上部N用語とそれぞれのC-TF-IDF値。 |
.c_tf_idf_ | C-TF-IDFを介して計算されたトピックタームマトリックス。 |
.topic_aspects_ | 各トピックのさまざまな側面または表現。 |
.topic_labels_ | 各トピックのデフォルトラベル。 |
.custom_labels_ | .set_topic_labelsを介して生成された各トピックのカスタムラベル。 |
.topic_embeddings_ | embedding_modelが使用された場合、各トピックの埋め込み。 |
.representative_docs_ | HDBSCANが使用されている場合、各トピックの代表的なドキュメント。 |
トピックモデリングを使用できる多くの異なるユースケースがあります。そのため、多くのユースケースで1つのパッケージを使用できるように、ベルトピックのいくつかのバリエーションが開発されています。
| 方法 | コード |
|---|---|
| トピック分布近似 | .approximate_distribution(docs) |
| オンライントピックモデリング | .partial_fit(doc) |
| 半教師のトピックモデリング | .fit(docs, y=y) |
| 監視されたトピックモデリング | .fit(docs, y=y) |
| マニュアルトピックモデリング | .fit(docs, y=y) |
| マルチモーダルトピックモデリング | .fit(docs, images=images) |
| クラスごとのトピックモデリング | .topics_per_class(docs, classes) |
| 動的トピックモデリング | .topics_over_time(docs, timestamps) |
| 階層的トピックモデリング | .hierarchical_topics(docs) |
| ガイド付きトピックモデリング | BERTopic(seed_topic_list=seed_topic_list) |
| ゼロショットトピックモデリング | BERTopic(zeroshot_topic_list=zeroshot_topic_list) |
| 複数のモデルをマージします | BERTopic.merge_models([topic_model_1, topic_model_2]) |
評価の多少主観的な性質により、トピックモデルの評価はかなり困難です。トピックモデルのさまざまな側面を視覚化すると、モデルの理解に役立ち、モデルを好みに合わせやすくします。
| 方法 | コード |
|---|---|
| トピックを視覚化します | .visualize_topics() |
| ドキュメントを視覚化します | .visualize_documents() |
| ドキュメントの階層を視覚化します | .visualize_hierarchical_documents() |
| トピックの階層を視覚化します | .visualize_hierarchy() |
| トピックツリーを視覚化します | .get_topic_tree(hierarchical_topics) |
| トピック用語を視覚化します | .visualize_barchart() |
| トピックの類似性を視覚化します | .visualize_heatmap() |
| タームスコアの減少を視覚化します | .visualize_term_rank() |
| トピックの確率分布を視覚化します | .visualize_distribution(probs[0]) |
| 時間の経過とともにトピックを視覚化します | .visualize_topics_over_time(topics_over_time) |
| クラスごとにトピックを視覚化します | .visualize_topics_per_class(topics_per_class) |
Bertopic Paperを引用するには、次のBibtexリファレンスを使用してください。
@article{grootendorst2022bertopic,
title={BERTopic: Neural topic modeling with a class-based TF-IDF procedure},
author={Grootendorst, Maarten},
journal={arXiv preprint arXiv:2203.05794},
year={2022}
}


